Public Channels
- # 3m
- # accounting
- # adm-class-action
- # admin-tip-2022-pay-plan
- # admin_blx_dailyscrum
- # admin_shield_helpdesk
- # admin_sl_tip_reconcile
- # admin_tip_contractreporting
- # admin_tip_declines-cb
- # admin_tip_declines-lv
- # admin_tip_qa_error_log_test
- # admin_tip_qa_log_test
- # admin_tip_setup_vegas
- # adult-survivors-act
- # adventist-school-abuse
- # alameda-juv-detention-abuse
- # amazon-discrimination
- # amex-black-owned-bus-discrimination
- # arizona-juvenile-hall-abuse
- # arizona-youth-treatment-center
- # asbestos-cancer
- # assault-datingapp
- # ata-mideast
- # aunt-marthas-integrated-care-abuse
- # auto-accidents
- # auto-insurance-denial
- # auto-nation-class
- # awko-inbound-return-calls
- # baby-food-autism
- # backpage-cityxguide-sex-trafficking
- # bair-hugger
- # baltimore-clergy-abuse
- # bard-powerport-catheter
- # bayview-sexual-abuse
- # belviq
- # big_brothers_sister_abuse
- # birth-injuries
- # birth-injury
- # bizdev
- # bp_camp_lejune_log
- # button-batteries
- # ca-camp-abuse
- # ca-group-home-abuse
- # ca-institute-for-women
- # ca-juvenile-hall-abuse
- # ca-life-insurance-lapse
- # california-jdc-abuse
- # call-center-tv-planning
- # camp-lejeune
- # capital-prep-school-abuse
- # carlsbad_office
- # cartiva
- # cerebral-palsy
- # chowchilla-womens-prison-abuse
- # christian_youth_assault
- # city-national-bank-discrimination
- # clergy-abuse
- # contract-litigation
- # craig-harward-joseph-weller-abuse
- # creativeproduction
- # cumberland-hospital-abuse
- # daily-decline-report
- # daily-replacement-request-report
- # dailynumbers
- # debtrelief
- # defective-idle-stop-lawsuit
- # depo-provera
- # dr-barry-brock-abuse
- # dr-bradford-bomba-abuse
- # dr-derrick-todd-abuse
- # dr-hadden-abuse
- # dr-oumair-aejaz-abuse
- # dr-scott-lee-abuse
- # dublin-correctional-institute-abuse
- # dubsmash-video-privacy
- # e-sign_alerts
- # elmiron
- # equitable-financial-life
- # erbs-palsy
- # eric-norman-olsen-ca-school-abuse
- # ertc
- # estate-planning
- # ethylene-oxide
- # ezricare-eye-drops
- # farmer-loan-discrimination
- # fb-form-field-names
- # female-ny-correctional-facility-abuse
- # firefoam
- # first-responder-accidents
- # flo-app-class-rep
- # food_poisoning
- # ford-lincoln-sudden-engine-failure
- # form-95-daily-report
- # gaming-addiction
- # general
- # general-liability
- # general-storm-damage
- # glen-mills-school-abuse
- # globaldashboard
- # gm_oil_defect
- # gtmcontainers
- # hanna-boys-center-abuse
- # harris-county-jail-deaths
- # healthcare-data-breach
- # herniamesh
- # hoag-hospital-abuse
- # hospital-portal-privacy
- # hudsons-bay-high-school-abuse
- # hurricane-damage
- # illinois-clergy-abuse
- # illinois-foster-care-abuse
- # illinois-juv-hall-abuse
- # illinois-youth-treatment-abuse
- # instant-soup-cup-child-burns
- # intake-daily-disposition-report
- # internal-fb-accounts
- # intuit-privacy-violations
- # ivc
- # jehovahs-witness-church-abuse
- # jrotc-abuse
- # kanakuk-kamps-abuse
- # kansas-juv-detention-center-abuse
- # kansas-juvenile-detention-center-yrtc-abuse
- # kentucky-organ-donor-investigation
- # knee_implant_cement
- # la-county-foster-care-abuse
- # la-county-juv-settlement
- # la-wildfires
- # la_wildfires_fba_organic
- # lausd-abuse
- # law-runle-intake-questions
- # leadspedia
- # liquid-destroyed-embryo
- # los-padrinos-juv-hall-abuse
- # maclaren-hall-abuse
- # maryland-female-cx-abuse
- # maryland-juv-hall-abuse
- # maryland-school-abuse
- # maui-lahaina-wildfires
- # mcdonogh-school-abuse
- # medical-mal-cancer
- # medical-malpractice
- # mercedes-class-action
- # metal-hip
- # michigan-catholic-clergy-abuse
- # michigan-foster-care-abuse
- # michigan-juv-hall-abuse
- # michigan-pollution
- # michigan-youth-treatment-abuse
- # milestone-tax-solutons
- # moreno-valley-pastor-abuse
- # mormon-church-abuse
- # mortgage-race-lawsuit
- # muslim-bank-discrimination
- # mva
- # nec
- # nevada-juvenile-hall-abuse
- # new-jersey-juvenile-detention-abuse
- # nh-juvenile-abuse
- # non-english-speaking-callers
- # northwell-sleep-center
- # nursing-home-abuse
- # nursing-home-abuse-litigation
- # ny-presbyterian-abuse
- # ny-urologist-abuse
- # nyc-private-school-abuse
- # onstar-drive-tracking
- # operations-project-staffing-needs
- # organic-tampon-lawsuit
- # otc-decongenstant-cases
- # oxbryta
- # ozempic
- # paragard
- # paraquat
- # patreon-video-privacy-lawsuit
- # patton-hospital-abuse
- # peloton-library-class-action
- # pfas-water-contamination
- # pixels
- # polinsky-childrens-center-abuse
- # pomona-high-school-abuse
- # popcorn-machine-status-
- # porterville-developmental-center-ab
- # posting-specs
- # ppp-fraud-whistleblower
- # prescription-medication-overpayment
- # principal-financial-401k-lawsuit
- # private-boarding-school-abuse
- # probate
- # psychiatric-sexual-abuse
- # redlands-school-sex-abuse
- # rent-increase-lawsuit
- # riceberg-sex-abuse
- # riverside-juvenile-detention-abuse
- # rosemead-highschool-abuse
- # roundup
- # royal-rangers-abuse
- # sacramento-juvenile-detention-abuse
- # salon-professional-bladder-cancer
- # san-bernardiino-juv-detention-abuse
- # san-diego-juvenile-detention-yrtc-abuse
- # santa-clara-juv-detention-abuse
- # services_blx_dl_log
- # services_blx_seo
- # services_blx_sitedev_pixels
- # shared_shield_legal
- # shield_orders_copper
- # shieldclientservices
- # shimano-crank-set-recall
- # sjs
- # social-media-teen-harm
- # socialengagement
- # southern-baptist-church-abuse
- # southwest-airlines-discrimination
- # st-helens-sexual-abuse
- # state-farm-denial
- # student-athlete-photo-hacking
- # suboxone-dental-injuries
- # tasigna
- # tepezza-hearing-loss
- # tesla-discrimination
- # texas-youth-facilities-abuse
- # thacher-school-abuse
- # the-hill-video-privacy
- # tip-tracking-number-config
- # total-loss-insurance
- # tough-mudder-illness
- # transvaginal-mesh
- # trinity-private-school-abuse
- # trucking-accidents
- # truvada
- # twominutetopicsdevs
- # tylenol-autism
- # type-2-child-diabetes
- # uber_lyft_assault
- # uhc-optum-change-databreach
- # university-of-chicago-discrimination
- # usa-consumer-network
- # valsartan
- # vertical_fields
- # video-gaming-sextortion
- # west-virginia-hernia-repair
- # wood-pellet-lawsuits
- # wordpress
- # workers-compensation
- # wtc_cancer
- # youth-treatment-center-abuse
Private Channels
- 🔒 2fa
- 🔒 account_services
- 🔒 acts-integrations
- 🔒 acv-gummy
- 🔒 admin-tip-invoicing
- 🔒 admin_activity
- 🔒 admin_blx_account_key
- 🔒 admin_blx_account_mgmt
- 🔒 admin_blx_analytics
- 🔒 admin_blx_bizdev
- 🔒 admin_blx_bizdev_audits
- 🔒 admin_blx_bizdev_sales
- 🔒 admin_blx_callcenter
- 🔒 admin_blx_callcetner_dispos
- 🔒 admin_blx_dailyfinancials
- 🔒 admin_blx_finance
- 🔒 admin_blx_invoices
- 🔒 admin_blx_lead_dispo
- 🔒 admin_blx_library
- 🔒 admin_blx_moments_ai
- 🔒 admin_blx_office
- 🔒 admin_shield_analytics
- 🔒 admin_shield_callcenter
- 🔒 admin_shield_callcenter_bills
- 🔒 admin_shield_commissions
- 🔒 admin_shield_contract-pacing
- 🔒 admin_shield_finance
- 🔒 admin_shield_finance_temp
- 🔒 admin_shield_google
- 🔒 admin_shield_google_leads
- 🔒 admin_shield_integrations
- 🔒 admin_shield_isa-sc_log
- 🔒 admin_shield_isl-mb_log
- 🔒 admin_shield_isl-rev_log
- 🔒 admin_shield_isl-svc_log
- 🔒 admin_shield_library
- 🔒 admin_shield_pmo
- 🔒 admin_shield_sales_ops
- 🔒 admin_shield_unsold-leads
- 🔒 admin_tip_analytics
- 🔒 admin_tip_casecriteria
- 🔒 admin_tip_corpdev
- 🔒 admin_tip_dialer
- 🔒 admin_tip_finance
- 🔒 admin_tip_formation
- 🔒 admin_tip_hiring
- 🔒 admin_tip_integrations
- 🔒 admin_tip_lawruler
- 🔒 admin_tip_library
- 🔒 admin_tip_logistics
- 🔒 admin_tip_services
- 🔒 advisor-connect-life
- 🔒 ai-development-team
- 🔒 airbnb-assault
- 🔒 arcads-support
- 🔒 badura-management-team
- 🔒 bailey-glasser-integrations
- 🔒 bcl-integration-coordination
- 🔒 blx-social-media-teen-harm
- 🔒 boysgirlsclubs-abuse
- 🔒 bp_camp_lejune_metrics
- 🔒 brandlytics-maxfusion
- 🔒 brandmentaility
- 🔒 brittanys-birthday-surprise
- 🔒 business-intelligence
- 🔒 business_intelligence_dev_team
- 🔒 call_leads_dispos
- 🔒 camp-lejeune-gwpb
- 🔒 camp_lejeune_organic
- 🔒 campaign_alerts
- 🔒 clo
- 🔒 commits
- 🔒 conference-planning
- 🔒 content-dev-requests
- 🔒 contract-float-postings
- 🔒 cpap-recall
- 🔒 cust_blx_alg
- 🔒 cust_blx_bcl
- 🔒 cust_blx_bcl_ext
- 🔒 cust_blx_bcl_intake_cc_ext
- 🔒 cust_blx_bcl_sachs_ext
- 🔒 cust_blx_bdl
- 🔒 cust_blx_br
- 🔒 cust_blx_brandlytics
- 🔒 cust_blx_ccghealth
- 🔒 cust_blx_dl
- 🔒 cust_blx_fls
- 🔒 cust_blx_glo
- 🔒 cust_blx_jgw
- 🔒 cust_blx_losg
- 🔒 cust_blx_rwz
- 🔒 cust_blx_sok
- 🔒 cust_blx_som
- 🔒 cust_blx_som_pr_ext
- 🔒 cust_blx_spl
- 🔒 d-is-for-data
- 🔒 dacthal
- 🔒 darrow-disposition_report
- 🔒 data-dictionary
- 🔒 datastan
- 🔒 deploys
- 🔒 dev_shield_lcp
- 🔒 developers
- 🔒 devereaux-abuse
- 🔒 devops
- 🔒 dicello-flatirons_coordination
- 🔒 dl-client-escalations
- 🔒 dwight-maximus
- 🔒 exactech-recall
- 🔒 external-shieldlegal-mediamath
- 🔒 exxon-discrimination
- 🔒 final-video-ads
- 🔒 firefoam_organic
- 🔒 five9-project-team
- 🔒 flatirons-coordination
- 🔒 focus_groups
- 🔒 form-integrations
- 🔒 gilman_schools_abuse
- 🔒 gilman_schools_abuse_organic
- 🔒 google-accounts-transition-to-shieldlegal_dot_com
- 🔒 google-ads-conversions
- 🔒 google_media_buying_general
- 🔒 group-messages
- 🔒 hair-relaxer-cancer
- 🔒 hair_relaxer_organic
- 🔒 help-desk
- 🔒 help-desk-google-alerts
- 🔒 help-desk-integrations
- 🔒 help-desk-old
- 🔒 help-desk-security
- 🔒 hiring
- 🔒 hiring_bizdev
- 🔒 howard_county_abuse
- 🔒 howard_county_abuse_organic
- 🔒 human-trafficking
- 🔒 il_clergy_abuse_organic
- 🔒 il_juvenile_hall_organic
- 🔒 il_school_abuse_organic
- 🔒 illinois-juv-hall-abuse-bg-tv
- 🔒 illinois-juv-hall-abuse-dl-tv
- 🔒 illinois-juv-hall-abuse-sss-tv
- 🔒 innovation
- 🔒 intakes-and-fieldmaps
- 🔒 integrations
- 🔒 integrations-qa
- 🔒 integrations-team
- 🔒 integrations_team
- 🔒 internaltraffic
- 🔒 invoicing
- 🔒 la-county-settlements
- 🔒 la-juv-hall-abuse-tv
- 🔒 lawruler_dev
- 🔒 m-a-g
- 🔒 md-juv-hall-abuse-bg-tv
- 🔒 md-juv-hall-abuse-dl-tv
- 🔒 md-juv-hall-abuse-sss-tv
- 🔒 md-juvenile-hall-abuse-organic
- 🔒 md_clergy_organic
- 🔒 md_key_schools_organic
- 🔒 md_school_abuse_organic
- 🔒 meadow-integrations
- 🔒 media_buyers
- 🔒 michigan_clergy_abuse_organic
- 🔒 ml_tip_university
- 🔒 monday_reporting
- 🔒 mtpr-creative
- 🔒 mva_tx_lsa_bcl
- 🔒 national-sex-abuse-organic
- 🔒 national_sex_abuse_sil_organic
- 🔒 new_orders_shield
- 🔒 newcampaignsetup
- 🔒 nicks-notes
- 🔒 nitido-meta-integrations
- 🔒 nitido_fbpmd_capi
- 🔒 northwestern-sports-abuse
- 🔒 northwestern-university-abuse-organic
- 🔒 nv_auto_accidents
- 🔒 ny-presbyterian-organic
- 🔒 ogintake
- 🔒 ops-administrative
- 🔒 ops_shield_lcp
- 🔒 overthecap
- 🔒 paqfixes
- 🔒 pennsylvania-juvenile-hall-abuse
- 🔒 pixels_server
- 🔒 pointbreak_analytics
- 🔒 pointbreak_enrollments
- 🔒 pointbreak_operations
- 🔒 predictive-model-platform
- 🔒 privacy-requests
- 🔒 proj-leadflow
- 🔒 reporting_automations
- 🔒 return-requests
- 🔒 rev-update-anthony
- 🔒 rev-update-caleb
- 🔒 rev-update-hamik
- 🔒 rev-update-jack
- 🔒 rev-update-john
- 🔒 rev-update-kris
- 🔒 rev-update-main
- 🔒 rev-update-maximus
- 🔒 runcloud
- 🔒 sales-commissions
- 🔒 security
- 🔒 services_blx_creatives
- 🔒 services_blx_leadspedia
- 🔒 services_blx_mediabuying
- 🔒 services_blx_mediabuying_disputes
- 🔒 services_blx_sitedev
- 🔒 services_blx_socialmedia
- 🔒 shield-dash-pvs
- 🔒 shield-legal_fivetran
- 🔒 shield_daily_revenue
- 🔒 shield_pvs_reports
- 🔒 shield_tv_callcenter_ext
- 🔒 shieldclientdashboards
- 🔒 sl-data-team
- 🔒 sl_sentinel_openjar_admin_docs
- 🔒 sl_sentinel_openjar_admin_general
- 🔒 sl_sentinel_openjar_admin_orders
- 🔒 sl_sentinel_openjar_birthinjury
- 🔒 sl_sentinel_openjar_cartiva
- 🔒 sl_sentinel_openjar_clergyabuse
- 🔒 sl_sentinel_openjar_nec
- 🔒 social-media-organic-and-paid
- 🔒 social-media-postback
- 🔒 som_miami_reg
- 🔒 statistics-and-reporting
- 🔒 stats-and-reporting-announcements
- 🔒 stock-fraud
- 🔒 strategy-and-operations
- 🔒 sunscreen
- 🔒 super-pod
- 🔒 surrogacy
- 🔒 talc
- 🔒 testing-media-spend-notification
- 🔒 the-apartment
- 🔒 the-blog-squad-v2
- 🔒 the-condo
- 🔒 tik-tok-video-production
- 🔒 tiktok_media_ext
- 🔒 tip-connect
- 🔒 tip-connect-notes
- 🔒 tip-director-commission
- 🔒 tip-organic-linkedin
- 🔒 tip_new_campaign_requests-6638
- 🔒 tip_pricing_commissions
- 🔒 tip_reporting
- 🔒 tip_services_customer_shieldlegal
- 🔒 training-recordings
- 🔒 truerecovery-dev
- 🔒 tv_media
- 🔒 university-abuse-organic
- 🔒 video-production
- 🔒 video_content_team
- 🔒 vmi-abuse
- 🔒 wordpress-mgmt
- 🔒 xeljanz
- 🔒 zantac
Direct Messages
- 👤 Mike Everhart , Mike Everhart
- 👤 Mike Everhart , slackbot
- 👤 slackbot , slackbot
- 👤 Google Drive , slackbot
- 👤 Jack Altunyan , Jack Altunyan
- 👤 Mike Everhart , Jack Altunyan
- 👤 Jack Altunyan , slackbot
- 👤 Mike Everhart , Google Calendar
- 👤 brandon , brandon
- 👤 Marc Barmazel , Marc Barmazel
- 👤 Marc Barmazel , slackbot
- 👤 Ben Brown , Ben Brown
- 👤 Cameron Rentch , slackbot
- 👤 sean , sean
- 👤 Cameron Rentch , Cameron Rentch
- 👤 sean , Cameron Rentch
- 👤 Erik Gratz , slackbot
- 👤 Google Drive , Cameron Rentch
- 👤 Cameron Rentch , Ryan Vaspra
- 👤 Jack Altunyan , Cameron Rentch
- 👤 Ryan Vaspra , slackbot
- 👤 Ryan Vaspra , Ryan Vaspra
- 👤 Mike Everhart , Cameron Rentch
- 👤 sean , Ryan Vaspra
- 👤 Maximus , slackbot
- 👤 Cameron Rentch , Maximus
- 👤 Mike Everhart , Ryan Vaspra
- 👤 Maximus , Maximus
- 👤 Ryan Vaspra , Maximus
- 👤 Jack Altunyan , Maximus
- 👤 Mike Everhart , Maximus
- 👤 Cameron Rentch , john
- 👤 Ryan Vaspra , john
- 👤 john , slackbot
- 👤 Mike Everhart , john
- 👤 Maximus , john
- 👤 Mark Hines , slackbot
- 👤 Mark Hines , Mark Hines
- 👤 Mike Everhart , Mark Hines
- 👤 Ryan Vaspra , Mark Hines
- 👤 Maximus , Mark Hines
- 👤 Cameron Rentch , Mark Hines
- 👤 Maximus , slackbot
- 👤 Google Calendar , Ryan Vaspra
- 👤 deactivateduser717106 , deactivateduser717106
- 👤 Jack Altunyan , Ryan Vaspra
- 👤 Quint , slackbot
- 👤 Intraday_Sold_Leads_Microservice , slackbot
- 👤 james barlow , slackbot
- 👤 Ryan Vaspra , Intraday_Sold_Leads_Microservice
- 👤 Jack Altunyan , Mark Hines
- 👤 Hamik Akhverdyan , slackbot
- 👤 john , Intraday_Sold_Leads_Microservice
- 👤 Mark Hines , Hamik Akhverdyan
- 👤 Maximus , Intraday_Sold_Leads_Microservice
- 👤 Jack Altunyan , Intraday_Sold_Leads_Microservice
- 👤 Devin Dubin , Devin Dubin
- 👤 Devin Dubin , slackbot
- 👤 Hailie Lane , slackbot
- 👤 SLacktopus , slackbot
- 👤 john , Mark Hines
- 👤 Chris , slackbot
- 👤 Ryan Vaspra , Chris
- 👤 TIP Signed Contracts Alert , slackbot
- 👤 Cameron Rentch , Chris
- 👤 Tony , slackbot
- 👤 Tony , Tony
- 👤 Cameron Rentch , Tony
- 👤 Ryan Vaspra , Tony
- 👤 ryan , slackbot
- 👤 Marc Barmazel , Ryan Vaspra
- 👤 Brian Hirst , slackbot
- 👤 Maximus , Brian Hirst
- 👤 Ryan Vaspra , Brian Hirst
- 👤 Tony , Brian Hirst
- 👤 Mike Everhart , Brian Hirst
- 👤 john , Brian Hirst
- 👤 Cameron Rentch , Brian Hirst
- 👤 Brian Hirst , Brian Hirst
- 👤 Caleb Peters , Caleb Peters
- 👤 john , Caleb Peters
- 👤 Caleb Peters , slackbot
- 👤 Brian Hirst , Caleb Peters
- 👤 Cameron Rentch , Caleb Peters
- 👤 Ryan Vaspra , Caleb Peters
- 👤 Intraday_Sold_Leads_Microservice , Caleb Peters
- 👤 Kelly C. Richardson, EdS , slackbot
- 👤 Cameron Rentch , Kelly C. Richardson, EdS
- 👤 Maximus , Caleb Peters
- 👤 Kelly C. Richardson, EdS , Kelly C. Richardson, EdS
- 👤 Marc Barmazel , Cameron Rentch
- 👤 john , Kelly C. Richardson, EdS
- 👤 Mike Everhart , Fabian De Simone
- 👤 Ryan Vaspra , Kelly C. Richardson, EdS
- 👤 Cameron Rentch , Fabian De Simone
- 👤 Mark Hines , Kelly C. Richardson, EdS
- 👤 Mark Hines , Caleb Peters
- 👤 Mark Hines , Brian Hirst
- 👤 Mike Everhart , Caleb Peters
- 👤 Ian Knight , slackbot
- 👤 Kris Standley , slackbot
- 👤 Cameron Rentch , Kris Standley
- 👤 Kris Standley , Kris Standley
- 👤 Google Calendar , Tony
- 👤 Ryan Vaspra , Loom
- 👤 Sabrina Da Silva , slackbot
- 👤 Jack Altunyan , Brian Hirst
- 👤 Google Drive , Kris Standley
- 👤 Cameron Rentch , Andy Rogers
- 👤 Andy Rogers , slackbot
- 👤 Andy Rogers , Andy Rogers
- 👤 Ryan Vaspra , Andy Rogers
- 👤 Luis Cortes , Luis Cortes
- 👤 Luis Cortes , slackbot
- 👤 Hamik Akhverdyan , slackbot
- 👤 sean , Andy Rogers
- 👤 David Temmesfeld , slackbot
- 👤 Cameron Rentch , Dorshan Millhouse
- 👤 Mike Everhart , Chris
- 👤 Dorshan Millhouse , Dorshan Millhouse
- 👤 Dorshan Millhouse , slackbot
- 👤 Chris , Dorshan Millhouse
- 👤 Google Calendar , David Temmesfeld
- 👤 David Temmesfeld , David Temmesfeld
- 👤 Ryan Vaspra , Dorshan Millhouse
- 👤 David Temmesfeld , Dorshan Millhouse
- 👤 Natalie Nguyen , slackbot
- 👤 Chris , David Temmesfeld
- 👤 Mark Hines , Andy Rogers
- 👤 Rahat Yasir , slackbot
- 👤 Mike Everhart , Tony
- 👤 Caleb Peters , David Temmesfeld
- 👤 brettmichael , slackbot
- 👤 luke , luke
- 👤 greg , slackbot
- 👤 Ryan Vaspra , luke
- 👤 luke , slackbot
- 👤 Brian Hirst , luke
- 👤 Mike Everhart , luke
- 👤 sean , greg
- 👤 Allen Gross , slackbot
- 👤 Jon Pascal , slackbot
- 👤 Ryan Vaspra , brettmichael
- 👤 Google Drive , brettmichael
- 👤 Brittany Barnett , Brittany Barnett
- 👤 LaToya Palmer , LaToya Palmer
- 👤 LaToya Palmer , slackbot
- 👤 luke , LaToya Palmer
- 👤 Brittany Barnett , slackbot
- 👤 Ryan Vaspra , LaToya Palmer
- 👤 Mike Everhart , LaToya Palmer
- 👤 Mark Hines , LaToya Palmer
- 👤 Kelly C. Richardson, EdS , LaToya Palmer
- 👤 Maximus , luke
- 👤 Dealbot by Pipedrive , slackbot
- 👤 Google Drive , LaToya Palmer
- 👤 craig , slackbot
- 👤 Brian Hirst , Andy Rogers
- 👤 Ryan Vaspra , craig
- 👤 Tony , John Gillespie
- 👤 Kyle Chung , Kyle Chung
- 👤 Cameron Rentch , craig
- 👤 John Gillespie , connor
- 👤 Google Drive , Kelly C. Richardson, EdS
- 👤 Google Drive , connor
- 👤 Tony , Andy Rogers
- 👤 Google Calendar , Andy Rogers
- 👤 Brian Hirst , Loom
- 👤 Andy Rogers , luke
- 👤 Andy Rogers , LaToya Palmer
- 👤 carl , carl
- 👤 Google Drive , Brittany Barnett
- 👤 Caleb Peters , luke
- 👤 Google Calendar , Mark Hines
- 👤 Google Calendar , sean
- 👤 Google Calendar , Maximus
- 👤 Brian Hirst , LaToya Palmer
- 👤 Google Calendar , Brian Hirst
- 👤 Ryan Vaspra , deleted-U04KC9L4HRB
- 👤 Cameron Rentch , LaToya Palmer
- 👤 Adrienne Hester , slackbot
- 👤 Ryan Vaspra , Adrienne Hester
- 👤 Adrienne Hester , Adrienne Hester
- 👤 Mike Everhart , Adrienne Hester
- 👤 LaToya Palmer , Adrienne Hester
- 👤 Mike Everhart , Andy Rogers
- 👤 Andy Rogers , Adrienne Hester
- 👤 Kelly C. Richardson, EdS , Adrienne Hester
- 👤 Maximus , Andy Rogers
- 👤 Ryan Vaspra , connor
- 👤 Mark Hines , Adrienne Hester
- 👤 Chris , Adrienne Hester
- 👤 Cameron Rentch , Adrienne Hester
- 👤 Mark Hines , Loom
- 👤 Google Drive , Andy Rogers
- 👤 Cameron Rentch , deleted-U04GZ79CPNG
- 👤 Mike Everhart , deleted-U056TJH4KUL
- 👤 luke , Mark Maniora
- 👤 Mark Hines , Mark Maniora
- 👤 Kelly C. Richardson, EdS , Mark Maniora
- 👤 Mark Maniora , slackbot
- 👤 Mark Maniora , Mark Maniora
- 👤 LaToya Palmer , Mark Maniora
- 👤 Cameron Rentch , Mark Maniora
- 👤 Mike Everhart , Mark Maniora
- 👤 sean , craig
- 👤 Ryan Vaspra , Mark Maniora
- 👤 Adrienne Hester , Mark Maniora
- 👤 Brian Hirst , Mark Maniora
- 👤 Tony , deleted-U04HFGHL4RW
- 👤 robert , slackbot
- 👤 Cameron Rentch , deleted-U05DY7UGM2L
- 👤 Mike Everhart , Joe Santana
- 👤 Google Calendar , Joe Santana
- 👤 deleted-U04KC9L4HRB , Mark Maniora
- 👤 Joe Santana , Joe Santana
- 👤 Joe Santana , slackbot
- 👤 sean , luke
- 👤 Dorshan Millhouse , Adrienne Hester
- 👤 Mike Everhart , deleted-U04GZ79CPNG
- 👤 Ryan Vaspra , deleted-U05DY7UGM2L
- 👤 Ryan Vaspra , deleted-U05CPGEJRD3
- 👤 Ryan Vaspra , deleted-UPH0C3A9K
- 👤 Adrienne Hester , deleted-U059JKB35RU
- 👤 Tony , Mark Maniora
- 👤 Dwight Thomas , slackbot
- 👤 Dwight Thomas , Dwight Thomas
- 👤 Mike Everhart , Dwight Thomas
- 👤 Tony , craig
- 👤 LaToya Palmer , Dwight Thomas
- 👤 Ryan Vaspra , Dwight Thomas
- 👤 Mark Maniora , Dwight Thomas
- 👤 Ryan Vaspra , deleted-U05EFH3S2TA
- 👤 Rose Fleming , slackbot
- 👤 Andy Rogers , deleted-U05DY7UGM2L
- 👤 Cameron Rentch , ian
- 👤 Tony Jones , Nicholas McFadden
- 👤 Greg Owen , slackbot
- 👤 Mike Everhart , Nicholas McFadden
- 👤 Nicholas McFadden , Nicholas McFadden
- 👤 Cameron Rentch , Nicholas McFadden
- 👤 Ryan Vaspra , Nicholas McFadden
- 👤 Tony , Nicholas McFadden
- 👤 deleted-U04HFGHL4RW , Greg Owen
- 👤 Brian Hirst , Nicholas McFadden
- 👤 Tony , Greg Owen
- 👤 Mark Maniora , Nicholas McFadden
- 👤 Mike Everhart , Greg Owen
- 👤 Andy Rogers , Greg Owen
- 👤 Kris Standley , David Temmesfeld
- 👤 Justin Troyer , slackbot
- 👤 Nicholas McFadden , slackbot
- 👤 luke , Greg Owen
- 👤 deleted-U05EFH3S2TA , Nicholas McFadden
- 👤 Mike Everhart , deleted-U05DY7UGM2L
- 👤 deleted-U04GZ79CPNG , Greg Owen
- 👤 Joe Santana , Nicholas McFadden
- 👤 Cameron Rentch , Rose Fleming
- 👤 Cameron Rentch , deleted-U04R23BEW3V
- 👤 deleted-U055HQT39PC , Mark Maniora
- 👤 Google Calendar , Caleb Peters
- 👤 Brian Hirst , Greg Owen
- 👤 Google Calendar , Greg Owen
- 👤 Google Calendar , greg
- 👤 Brian Hirst , deleted-U055HQT39PC
- 👤 Google Calendar , luke
- 👤 Google Calendar , Nicholas McFadden
- 👤 Google Calendar , Devin Dubin
- 👤 Google Calendar , kelly840
- 👤 Google Calendar , Dorshan Millhouse
- 👤 Tony , debora
- 👤 Google Calendar , brettmichael
- 👤 debora , slackbot
- 👤 Ryan Vaspra , Julie-Margaret Johnson
- 👤 debora , debora
- 👤 Google Calendar , Kris Standley
- 👤 Google Calendar , Luis Cortes
- 👤 Google Calendar , Brittany Barnett
- 👤 LaToya Palmer , debora
- 👤 Google Calendar , debora
- 👤 Brian Hirst , Dwight Thomas
- 👤 Mark Maniora , Greg Owen
- 👤 Julie-Margaret Johnson , Julie-Margaret Johnson
- 👤 Julie-Margaret Johnson , slackbot
- 👤 LaToya Palmer , Julie-Margaret Johnson
- 👤 Google Calendar , Dwight Thomas
- 👤 deleted-U05M3DME3GR , debora
- 👤 Adrienne Hester , Julie-Margaret Johnson
- 👤 Ryan Vaspra , Rose Fleming
- 👤 Adrienne Hester , Greg Owen
- 👤 Dwight Thomas , Julie-Margaret Johnson
- 👤 luke , debora
- 👤 Ryan Vaspra , debora
- 👤 Cameron Rentch , Julie-Margaret Johnson
- 👤 LaToya Palmer , deleted-U04GZ79CPNG
- 👤 deleted-U04GU9EUV9A , debora
- 👤 Andy Rogers , debora
- 👤 Greg Owen , Julie-Margaret Johnson
- 👤 LaToya Palmer , Greg Owen
- 👤 Adrienne Hester , debora
- 👤 korbin , slackbot
- 👤 Adrienne Hester , korbin
- 👤 Mark Hines , debora
- 👤 Maximus , Julie-Margaret Johnson
- 👤 Tony , Dwight Thomas
- 👤 Google Drive , Dwight Thomas
- 👤 Ryan Vaspra , Greg Owen
- 👤 Cameron Rentch , korbin
- 👤 Kelly C. Richardson, EdS , Julie-Margaret Johnson
- 👤 Mike Everhart , korbin
- 👤 Maximus , David Temmesfeld
- 👤 Ryan Vaspra , korbin
- 👤 Andy Rogers , Dwight Thomas
- 👤 LaToya Palmer , korbin
- 👤 Jack Altunyan , debora
- 👤 debora , Nayeli Salmeron
- 👤 luke , korbin
- 👤 debora , deleted-U061HNPF4H5
- 👤 Chris , debora
- 👤 Dwight Thomas , Quint Underwood
- 👤 Jack Altunyan , Quint Underwood
- 👤 craig , debora
- 👤 Ryan Vaspra , Quint Underwood
- 👤 Andy Rogers , korbin
- 👤 Lee Zafra , slackbot
- 👤 Dwight Thomas , Lee Zafra
- 👤 Quint Underwood , slackbot
- 👤 Lee Zafra , Lee Zafra
- 👤 LaToya Palmer , Lee Zafra
- 👤 Mark Maniora , Joe Santana
- 👤 Adrienne Hester , Lee Zafra
- 👤 Julie-Margaret Johnson , Lee Zafra
- 👤 Jack Altunyan , Dwight Thomas
- 👤 LaToya Palmer , deleted-U055HQT39PC
- 👤 Cameron Rentch , Lee Zafra
- 👤 Ryan Vaspra , Lee Zafra
- 👤 Maximus , Dorshan Millhouse
- 👤 Mike Everhart , michaelbrunet
- 👤 Cameron Rentch , michaelbrunet
- 👤 Mark Hines , Dwight Thomas
- 👤 Dwight Thomas , Nicholas McFadden
- 👤 Ryan Vaspra , michaelbrunet
- 👤 Google Calendar , James Scott
- 👤 korbin , Lee Zafra
- 👤 Cameron Rentch , debora
- 👤 Caleb Peters , Dorshan Millhouse
- 👤 deleted-U05DY7UGM2L , James Scott
- 👤 Cameron Rentch , James Scott
- 👤 James Scott , James Scott
- 👤 Ryan Vaspra , James Scott
- 👤 Marc Barmazel , James Scott
- 👤 Mike Everhart , freshdesk_legacy
- 👤 James Scott , slackbot
- 👤 Nsay Y , slackbot
- 👤 Ryan Vaspra , Nsay Y
- 👤 sean , debora
- 👤 Brian Hirst , Nsay Y
- 👤 LaToya Palmer , deleted-U05CTUBCP7E
- 👤 Cameron Rentch , Nsay Y
- 👤 Andy Rogers , Nsay Y
- 👤 Cameron Rentch , Michael McKinney
- 👤 Maximus , Nsay Y
- 👤 Ryan Vaspra , Michael McKinney
- 👤 Jack Altunyan , Dorshan Millhouse
- 👤 Dwight Thomas , Michael McKinney
- 👤 Michael McKinney , Michael McKinney
- 👤 Jack Altunyan , Michael McKinney
- 👤 Kris Standley , Nsay Y
- 👤 Michael McKinney , slackbot
- 👤 debora , Nsay Y
- 👤 Mike Everhart , Michael McKinney
- 👤 Intraday_Sold_Leads_Microservice , Quint Underwood
- 👤 Greg Owen , debora
- 👤 Maximus , Dwight Thomas
- 👤 Altonese Neely , slackbot
- 👤 Cameron Rentch , Altonese Neely
- 👤 debora , Altonese Neely
- 👤 Cameron Rentch , brian580
- 👤 debora , brian580
- 👤 Ryan Vaspra , brian580
- 👤 Ryan Vaspra , Altonese Neely
- 👤 Jack Altunyan , Altonese Neely
- 👤 deleted-U04HFGHL4RW , Adrienne Hester
- 👤 brian580 , slackbot
- 👤 Adrienne Hester , Altonese Neely
- 👤 Nicholas McFadden , James Scott
- 👤 Greg Owen , deleted-U06AYDQ4WVA
- 👤 Caleb Peters , Dwight Thomas
- 👤 Cameron Rentch , rachel
- 👤 Google Drive , rachel
- 👤 Mark Hines , Joe Santana
- 👤 Caleb Peters , Lee Zafra
- 👤 Dwight Thomas , Greg Owen
- 👤 deleted-U05DY7UGM2L , Nicholas McFadden
- 👤 Julie-Margaret Johnson , korbin
- 👤 Brian Hirst , James Scott
- 👤 Andy Rogers , deleted-U05CTUBCP7E
- 👤 Maximus , Mark Maniora
- 👤 Mark Hines , Lee Zafra
- 👤 deleted-U04GU9EUV9A , Adrienne Hester
- 👤 luke , craig
- 👤 luke , Nicholas McFadden
- 👤 korbin , deleted-U06AYDQ4WVA
- 👤 Intraday_Sold_Leads_Microservice , Michael McKinney
- 👤 Nicholas McFadden , Greg Owen
- 👤 John Gillespie , debora
- 👤 deleted-U04KC9L4HRB , brian580
- 👤 Adrienne Hester , Dwight Thomas
- 👤 Cameron Rentch , parsa
- 👤 Google Calendar , parsa
- 👤 Google Calendar , patsy
- 👤 parsa , slackbot
- 👤 Cameron Rentch , deleted-U067A4KAB9U
- 👤 Cameron Rentch , patsy
- 👤 LaToya Palmer , deleted-U05CXRE6TBK
- 👤 Adrienne Hester , patsy
- 👤 Mike Everhart , parsa
- 👤 Greg Owen , korbin
- 👤 deleted-U055HQT39PC , Nicholas McFadden
- 👤 deleted-U04GU9EUV9A , Julie-Margaret Johnson
- 👤 LaToya Palmer , deleted-U069G4WMMD4
- 👤 Dorshan Millhouse , Michael McKinney
- 👤 Adrienne Hester , deleted-U069G4WMMD4
- 👤 Dorshan Millhouse , parsa
- 👤 deleted-U055HQT39PC , korbin
- 👤 Mike Everhart , deleted-U04GU9EUV9A
- 👤 Kelly C. Richardson, EdS , korbin
- 👤 Cameron Rentch , Greg Owen
- 👤 Mark Maniora , deleted-U06AYDQ4WVA
- 👤 Dwight Thomas , deleted-U06AYDQ4WVA
- 👤 Ryan Vaspra , deleted-U0679HSE82K
- 👤 deleted-U056TJH4KUL , Dwight Thomas
- 👤 Andy Rogers , Mark Maniora
- 👤 Kelly C. Richardson, EdS , Altonese Neely
- 👤 Greg Owen , deleted-U06C7A8PVLJ
- 👤 Andy Rogers , Nicholas McFadden
- 👤 Andy Rogers , patsy
- 👤 deleted-U04GZ79CPNG , korbin
- 👤 Mike Everhart , Kelly C. Richardson, EdS
- 👤 Mark Maniora , debora
- 👤 brian580 , Altonese Neely
- 👤 deleted-U061HNPF4H5 , Nayeli Salmeron
- 👤 Julie-Margaret Johnson , patsy
- 👤 Mark Hines , Michael McKinney
- 👤 Tony , Lee Zafra
- 👤 deleted-U055HQT39PC , Dwight Thomas
- 👤 Adrienne Hester , deleted-U055HQT39PC
- 👤 ian , debora
- 👤 Google Calendar , darrell
- 👤 Ryan Vaspra , deleted-U04TA486SM6
- 👤 LaToya Palmer , deleted-U042MMWVCH2
- 👤 LaToya Palmer , deleted-U059JKB35RU
- 👤 Nicholas McFadden , darrell
- 👤 darrell , darrell
- 👤 darrell , slackbot
- 👤 Cameron Rentch , darrell
- 👤 Tony , Altonese Neely
- 👤 Google Drive , luke
- 👤 Brian Hirst , darrell
- 👤 Chris , brian580
- 👤 Mike Everhart , deleted-U06N28XTLE7
- 👤 luke , brian580
- 👤 Ryan Vaspra , Joe Santana
- 👤 deleted-U04R23BEW3V , Nicholas McFadden
- 👤 Ryan Vaspra , darrell
- 👤 sean , patsy
- 👤 Ryan Vaspra , patsy
- 👤 Greg Owen , brian580
- 👤 craig , brian580
- 👤 Mike Everhart , myjahnee739
- 👤 Greg Owen , patsy
- 👤 Kelly C. Richardson, EdS , deleted-U05DY7UGM2L
- 👤 luke , James Scott
- 👤 Mark Maniora , Julie-Margaret Johnson
- 👤 Maximus , Chris
- 👤 luke , patsy
- 👤 Andy Rogers , brian580
- 👤 Nicholas McFadden , Nick Ward
- 👤 Nick Ward , Nick Ward
- 👤 brian580 , patsy
- 👤 Nick Ward , slackbot
- 👤 Jack Altunyan , luke
- 👤 Google Drive , darrell
- 👤 myjahnee739 , Nick Ward
- 👤 deleted-U04GU9EUV9A , brian580
- 👤 Mark Maniora , patsy
- 👤 deleted-U05CTUBCP7E , Dwight Thomas
- 👤 Tony , brian580
- 👤 darrell , Nick Ward
- 👤 Google Calendar , deactivateduser168066
- 👤 Mark Maniora , deleted-U05DY7UGM2L
- 👤 deactivateduser168066 , deactivateduser168066
- 👤 Mike Everhart , ahsan
- 👤 Google Calendar , ahsan
- 👤 Joe Santana , ahsan
- 👤 Ryan Vaspra , Nick Ward
- 👤 Dwight Thomas , ahsan
- 👤 ahsan , slackbot
- 👤 Andy Rogers , deleted-U055HQT39PC
- 👤 deleted-U055HQT39PC , Greg Owen
- 👤 John Gillespie , deleted-U06HGJHJWQJ
- 👤 Nicholas McFadden , deactivateduser168066
- 👤 ahsan , ahsan
- 👤 craig , patsy
- 👤 monday.com , ahsan
- 👤 Ryan Vaspra , deactivateduser168066
- 👤 deactivateduser168066 , ahsan
- 👤 Joe Santana , Nick Ward
- 👤 Cameron Rentch , Nick Ward
- 👤 Mark Hines , brian580
- 👤 Google Calendar , David Evans
- 👤 Jack Altunyan , David Temmesfeld
- 👤 Nick Ward , deactivateduser168066
- 👤 Julie-Margaret Johnson , David Evans
- 👤 Mike Everhart , deactivateduser168066
- 👤 Cameron Rentch , deleted-U06C7A8PVLJ
- 👤 Maximus , ahsan
- 👤 Tony Jones , Adrienne Hester
- 👤 Malissa Phillips , slackbot
- 👤 Google Calendar , Malissa Phillips
- 👤 Greg Owen , Malissa Phillips
- 👤 Tony Jones , Greg Owen
- 👤 deleted-U04HFGHL4RW , Malissa Phillips
- 👤 Cameron Rentch , Malissa Phillips
- 👤 LaToya Palmer , ahsan
- 👤 Mark Maniora , Malissa Phillips
- 👤 David Evans , deactivateduser21835
- 👤 Google Calendar , deactivateduser21835
- 👤 Nicholas McFadden , Malissa Phillips
- 👤 Tony Jones , Malissa Phillips
- 👤 Andy Rogers , Malissa Phillips
- 👤 Nick Ward , Malissa Phillips
- 👤 Dwight Thomas , patsy
- 👤 Ryan Vaspra , Malissa Phillips
- 👤 Malissa Phillips , Malissa Phillips
- 👤 Cameron Rentch , Ralecia Marks
- 👤 Adrienne Hester , David Evans
- 👤 Mike Everhart , Nick Ward
- 👤 michaelbrunet , Ralecia Marks
- 👤 Nick Ward , Ralecia Marks
- 👤 Nicholas McFadden , ahsan
- 👤 deleted-U06N28XTLE7 , Malissa Phillips
- 👤 deleted-U055HQT39PC , Malissa Phillips
- 👤 Dwight Thomas , Nick Ward
- 👤 Brian Hirst , Nick Ward
- 👤 Aidan Celeste , slackbot
- 👤 deleted-U055HQT39PC , Nick Ward
- 👤 Mark Maniora , darrell
- 👤 Nsay Y , brian580
- 👤 Mark Maniora , Nick Ward
- 👤 ian , Mark Maniora
- 👤 brian580 , Malissa Phillips
- 👤 Joe Santana , Malissa Phillips
- 👤 korbin , deleted-U069G4WMMD4
- 👤 Aidan Celeste , Aidan Celeste
- 👤 Nick Ward , ahsan
- 👤 Google Drive , Nick Ward
- 👤 craig , Malissa Phillips
- 👤 deleted-U05CTUBCP7E , korbin
- 👤 LaToya Palmer , Nicholas McFadden
- 👤 patsy , Malissa Phillips
- 👤 Nicholas McFadden , Julie-Margaret Johnson
- 👤 Ryan Vaspra , GitHub
- 👤 LaToya Palmer , David Evans
- 👤 craig , Greg Owen
- 👤 Ryan Vaspra , ahsan
- 👤 deleted-U04G7CGMBPC , brian580
- 👤 Tony , Nsay Y
- 👤 deleted-U05DY7UGM2L , Lee Zafra
- 👤 Greg Owen , Nick Ward
- 👤 Google Drive , ahsan
- 👤 Greg Owen , ahsan
- 👤 luke , deleted-U072JS2NHRQ
- 👤 Dwight Thomas , deleted-U06N28XTLE7
- 👤 Cameron Rentch , David Evans
- 👤 deleted-U05DY7UGM2L , Nick Ward
- 👤 Ryan Vaspra , deleted-U072JS2NHRQ
- 👤 deleted-U04GZ79CPNG , Malissa Phillips
- 👤 Mike Everhart , Malissa Phillips
- 👤 deleted-U055HQT39PC , ahsan
- 👤 deleted-U072JS2NHRQ , ahsan
- 👤 Mark Hines , korbin
- 👤 Chris , Andy Rogers
- 👤 Greg Owen , David Evans
- 👤 Brian Hirst , ahsan
- 👤 Dwight Thomas , Malissa Phillips
- 👤 Luis Cortes , deleted-U055HQT39PC
- 👤 Melanie Macias , slackbot
- 👤 craig , David Evans
- 👤 Ryan Vaspra , Tony Jones
- 👤 ahsan , Ralecia Marks
- 👤 Melanie Macias , Melanie Macias
- 👤 Andy Rogers , Melanie Macias
- 👤 Cameron Rentch , Melanie Macias
- 👤 LaToya Palmer , Melanie Macias
- 👤 Nicholas McFadden , Melanie Macias
- 👤 Brittany Barnett , Melanie Macias
- 👤 Chris , Melanie Macias
- 👤 Google Calendar , Melanie Macias
- 👤 Ryan Vaspra , Melanie Macias
- 👤 Adrienne Hester , Melanie Macias
- 👤 David Evans , Melanie Macias
- 👤 deleted-U06AYDQ4WVA , Malissa Phillips
- 👤 Julie-Margaret Johnson , Melanie Macias
- 👤 luke , Malissa Phillips
- 👤 Luis Cortes , deleted-U06KK7QLM55
- 👤 darrell , Malissa Phillips
- 👤 Maximus , deleted-U04R23BEW3V
- 👤 Tony , deleted-U055HQT39PC
- 👤 Nick Ward , Anthony Soboleski
- 👤 Luis Cortes , deleted-U04HFGHL4RW
- 👤 Anthony Soboleski , Anthony Soboleski
- 👤 deleted-U06C7A8PVLJ , ahsan
- 👤 Cameron Rentch , deleted-U06N28XTLE7
- 👤 Caleb Peters , craig
- 👤 deleted-U04R23BEW3V , Malissa Phillips
- 👤 Nick Ward , Daniel Schussler
- 👤 Greg Owen , Melanie Macias
- 👤 Daniel Schussler , Daniel Schussler
- 👤 Nicholas McFadden , Daniel Schussler
- 👤 ahsan , Malissa Phillips
- 👤 David Evans , Malissa Phillips
- 👤 Daniel Schussler , slackbot
- 👤 Mark Maniora , Daniel Schussler
- 👤 Google Calendar , Daniel Schussler
- 👤 Mark Maniora , ahsan
- 👤 Dwight Thomas , Daniel Schussler
- 👤 ahsan , Daniel Schussler
- 👤 Ryan Vaspra , deleted-U06GD22CLDC
- 👤 Lee Zafra , Melanie Macias
- 👤 Andy Rogers , David Evans
- 👤 Mike Everhart , Daniel Schussler
- 👤 Maximus , ahsan
- 👤 Dwight Thomas , darrell
- 👤 Malissa Phillips , Sean Marshall
- 👤 Melanie Macias , Jennifer Durnell
- 👤 Dustin Surwill , Dustin Surwill
- 👤 Google Calendar , Jennifer Durnell
- 👤 deleted-U069G4WMMD4 , Melanie Macias
- 👤 Joe Santana , Jennifer Durnell
- 👤 Google Calendar , Dustin Surwill
- 👤 Nicholas McFadden , Dustin Surwill
- 👤 Nick Ward , Dustin Surwill
- 👤 Dwight Thomas , Dustin Surwill
- 👤 Jennifer Durnell , Jennifer Durnell
- 👤 Mark Maniora , Melanie Macias
- 👤 Dustin Surwill , slackbot
- 👤 Joe Santana , Dustin Surwill
- 👤 Cameron Rentch , Joe Santana
- 👤 Brian Hirst , Malissa Phillips
- 👤 Nicholas McFadden , deleted-U06NZP17L83
- 👤 deleted-U05QUSWUJA2 , Greg Owen
- 👤 Ryan Vaspra , Dustin Surwill
- 👤 Daniel Schussler , Dustin Surwill
- 👤 James Turner , Zekarias Haile
- 👤 Dustin Surwill , James Turner
- 👤 Daniel Schussler , James Turner
- 👤 ahsan , Dustin Surwill
- 👤 Google Calendar , Zekarias Haile
- 👤 Nicholas McFadden , James Turner
- 👤 Malissa Phillips , Daniel Schussler
- 👤 James Turner , slackbot
- 👤 Nick Ward , James Turner
- 👤 Dwight Thomas , Zekarias Haile
- 👤 Mark Maniora , James Turner
- 👤 Nick Ward , Zekarias Haile
- 👤 Google Calendar , craig630
- 👤 Zekarias Haile , Zekarias Haile
- 👤 James Turner , James Turner
- 👤 Daniel Schussler , Zekarias Haile
- 👤 Mark Maniora , Zekarias Haile
- 👤 ahsan , Zekarias Haile
- 👤 ahsan , James Turner
- 👤 Ryan Vaspra , David Evans
- 👤 Andy Rogers , James Scott
- 👤 Zekarias Haile , slackbot
- 👤 Google Calendar , James Turner
- 👤 Ryan Vaspra , James Turner
- 👤 Anthony Soboleski , James Turner
- 👤 Adrienne Hester , Joe Santana
- 👤 darrell , Anthony Soboleski
- 👤 darrell , Dustin Surwill
- 👤 MediaBuyerTools_TEST , slackbot
- 👤 Ralecia Marks , James Turner
- 👤 Google Calendar , jsantana707
- 👤 Maximus , brian580
- 👤 Dustin Surwill , Zekarias Haile
- 👤 Malissa Phillips , James Turner
- 👤 deleted-U05DY7UGM2L , brian580
- 👤 Nicholas McFadden , Zekarias Haile
- 👤 Rose Fleming , Michelle Cowan
- 👤 deleted-U05DY7UGM2L , Dwight Thomas
- 👤 James Turner , sian
- 👤 Brian Hirst , deleted-U05DY7UGM2L
- 👤 deleted-U04R23BEW3V , Dustin Surwill
- 👤 Dwight Thomas , James Turner
- 👤 deleted-U04GZ79CPNG , Nicholas McFadden
- 👤 deleted-U05CTUBCP7E , James Turner
- 👤 deleted-U055HQT39PC , James Turner
- 👤 Dorshan Millhouse , Melanie Macias
- 👤 Mike Everhart , Dustin Surwill
- 👤 sean , Malissa Phillips
- 👤 darrell , ahsan
- 👤 deleted-U055HQT39PC , Daniel Schussler
- 👤 Mark Hines , Malissa Phillips
- 👤 Joe Santana , Dwight Thomas
- 👤 deleted-U04GZ79CPNG , Joe Santana
- 👤 Sean Marshall , James Turner
- 👤 deleted-U05CTUBCP7E , Nicholas McFadden
- 👤 deleted-U04GZ79CPNG , James Turner
- 👤 Joe Santana , Michelle Cowan
- 👤 sean , brian580
- 👤 deleted-U06C7A8PVLJ , Zekarias Haile
- 👤 deleted-U055HQT39PC , Dustin Surwill
- 👤 Cameron Rentch , Dustin Surwill
- 👤 Kelly C. Richardson, EdS , brian580
- 👤 Google Calendar , Lee Zafra
- 👤 Brian Hirst , James Turner
- 👤 Henri Engle , slackbot
- 👤 Beau Kallas , slackbot
- 👤 Amanda Hembree , Amanda Hembree
- 👤 craig , James Turner
- 👤 David Temmesfeld , Melanie Macias
- 👤 James Turner , Amanda Hembree
- 👤 James Turner , Beau Kallas
- 👤 VernonEvans , slackbot
- 👤 James Turner , Henri Engle
- 👤 Yan Ashrapov , Yan Ashrapov
- 👤 deleted-U05496RCQ9M , Daniel Schussler
- 👤 Aidan Celeste , Zekarias Haile
- 👤 darrell , Daniel Schussler
- 👤 Amanda Hembree , slackbot
- 👤 James Turner , VernonEvans
- 👤 Yan Ashrapov , slackbot
- 👤 deleted-U04GZ79CPNG , Dustin Surwill
- 👤 Google Calendar , Yan Ashrapov
- 👤 Malissa Phillips , Dustin Surwill
- 👤 deleted-U06C7A8PVLJ , Malissa Phillips
- 👤 Joe Santana , Yan Ashrapov
- 👤 Maximus , Yan Ashrapov
- 👤 Caleb Peters , Yan Ashrapov
- 👤 Brian Hirst , Dustin Surwill
- 👤 Ryan Vaspra , Zekarias Haile
- 👤 Jack Altunyan , Yan Ashrapov
- 👤 Maximus , Melanie Macias
- 👤 deleted-U06F9N9PB2A , Malissa Phillips
- 👤 Google Drive , Yan Ashrapov
- 👤 brian580 , Yan Ashrapov
- 👤 Joe Santana , James Turner
- 👤 Cameron Rentch , Yan Ashrapov
- 👤 Dustin Surwill , sian
- 👤 Dorshan Millhouse , Yan Ashrapov
- 👤 Mark Maniora , Dustin Surwill
- 👤 Melanie Macias , Yan Ashrapov
- 👤 deleted-U06GD22CLDC , Malissa Phillips
- 👤 Cameron Rentch , James Turner
- 👤 Adrienne Hester , James Turner
- 👤 James Scott , James Turner
- 👤 Dorshan Millhouse , Jennifer Durnell
- 👤 Ryan Vaspra , Yan Ashrapov
- 👤 deleted-U06AYDQ4WVA , Daniel Schussler
- 👤 deleted-U04GZ79CPNG , Daniel Schussler
- 👤 deleted-U05496RCQ9M , Dwight Thomas
- 👤 Joe Santana , Zekarias Haile
- 👤 Aidan Celeste , James Turner
- 👤 Aidan Celeste , Dustin Surwill
- 👤 Nsay Y , ahsan
- 👤 Quint , James Turner
- 👤 craig , Nsay Y
- 👤 Nicholas McFadden , deleted-U06F9N9PB2A
- 👤 Malissa Phillips , Melanie Macias
- 👤 Malissa Phillips , Zekarias Haile
- 👤 David Temmesfeld , Yan Ashrapov
- 👤 Greg Owen , Zekarias Haile
- 👤 brian580 , James Turner
- 👤 Nsay Y , Jennifer Durnell
- 👤 IT SUPPORT - Dennis Shaull , slackbot
- 👤 Luis Cortes , Nicholas McFadden
- 👤 Google Calendar , IT SUPPORT - Dennis Shaull
- 👤 Cameron Rentch , Jennifer Durnell
- 👤 James Scott , Nsay Y
- 👤 deleted-U04TA486SM6 , Dustin Surwill
- 👤 Brian Hirst , Zekarias Haile
- 👤 darrell , James Turner
- 👤 deleted-U06GD22CLDC , James Turner
- 👤 Kelly C. Richardson, EdS , Melanie Macias
- 👤 deleted-U05F548NU5V , Yan Ashrapov
- 👤 Kelly C. Richardson, EdS , Lee Zafra
- 👤 deleted-U062D2YJ15Y , James Turner
- 👤 deleted-U06VDQGHZLL , James Turner
- 👤 Yan Ashrapov , deleted-U084U38R8DN
- 👤 David Evans , Sean Marshall
- 👤 Serebe , slackbot
- 👤 Ryan Vaspra , Serebe
- 👤 LaToya Palmer , Jennifer Durnell
- 👤 James Scott , brian580
- 👤 Aidan Celeste , IT SUPPORT - Dennis Shaull
- 👤 Greg Owen , deleted-U07SBM5MB32
- 👤 deleted-U06C7A8PVLJ , Dustin Surwill
- 👤 Mark Hines , IT SUPPORT - Dennis Shaull
- 👤 darrell , Zekarias Haile
- 👤 Lee Zafra , Malissa Phillips
- 👤 Dustin Surwill , IT SUPPORT - Dennis Shaull
- 👤 Mark Maniora , IT SUPPORT - Dennis Shaull
- 👤 LaToya Palmer , IT SUPPORT - Dennis Shaull
- 👤 Mike Everhart , Yan Ashrapov
- 👤 Joe Santana , darrell
- 👤 deleted-U05G9BHC4GY , Yan Ashrapov
- 👤 Joe Santana , Greg Owen
- 👤 Nicholas McFadden , Nsay Y
- 👤 deleted-U05CTUBCP7E , Daniel Schussler
- 👤 brian580 , IT SUPPORT - Dennis Shaull
- 👤 darrell , IT SUPPORT - Dennis Shaull
- 👤 Nsay Y , darrell
- 👤 Nicholas McFadden , Yan Ashrapov
- 👤 deleted-U04TA486SM6 , Malissa Phillips
- 👤 Joe Santana , deleted-U06VDQGHZLL
- 👤 deleted-U072B7ZV4SH , ahsan
- 👤 Joe Santana , Daniel Schussler
- 👤 Greg Owen , Dustin Surwill
- 👤 deleted-U05QUSWUJA2 , Dustin Surwill
- 👤 greg , brian580
- 👤 Melanie Macias , Daniel Schussler
- 👤 Malissa Phillips , sian
- 👤 deleted-U07097NJDA7 , Nick Ward
- 👤 James Scott , Jehoshua Josue
- 👤 Google Calendar , Jehoshua Josue
- 👤 deleted-U055HQT39PC , Zekarias Haile
- 👤 deleted-U06C7A8PVLJ , wf_bot_a0887aydgeb
- 👤 deleted-U05DY7UGM2L , Melanie Macias
- 👤 Brian Hirst , Yan Ashrapov
- 👤 Cameron Rentch , deleted-U06GD22CLDC
- 👤 Joe Santana , Jehoshua Josue
- 👤 Jehoshua Josue , Jehoshua Josue
- 👤 deleted-U04HFGHL4RW , Joe Santana
- 👤 James Scott , Dustin Surwill
- 👤 ahsan , Edward Weber
- 👤 Rose Fleming , Malissa Phillips
- 👤 Greg Owen , James Turner
- 👤 Daniel Schussler , Jehoshua Josue
- 👤 Greg Owen , deleted-U083HCG9AUR
- 👤 James Scott , Nick Ward
- 👤 Nicholas McFadden , Jehoshua Josue
- 👤 LaToya Palmer , deleted-U06K957RUGY
- 👤 deleted-U04HFGHL4RW , James Turner
- 👤 Rose Fleming , brian580
- 👤 deleted-U06CVB2MHRN , Dustin Surwill
- 👤 deleted-U04TA486SM6 , Nicholas McFadden
- 👤 Brian Hirst , Joe Santana
- 👤 deleted-U04GG7BCZ5M , Malissa Phillips
- 👤 ahsan , Jehoshua Josue
- 👤 deleted-U06F9N9PB2A , ahsan
- 👤 Nicholas McFadden , Jennifer Durnell
- 👤 deleted-U04R23BEW3V , James Turner
- 👤 deleted-U05DY7UGM2L , James Turner
- 👤 Dustin Surwill , deleted-U08E306T7SM
- 👤 ahsan , sian
- 👤 Mark Maniora , Lee Zafra
- 👤 Maximus , Nicholas McFadden
- 👤 Google Drive , James Scott
- 👤 deleted-U026DSD2R1B , Dorshan Millhouse
- 👤 Brian Hirst , Rose Fleming
- 👤 Malissa Phillips , deleted-U083HCG9AUR
- 👤 Malissa Phillips , IT SUPPORT - Dennis Shaull
- 👤 Jennifer Durnell , sian
- 👤 LaToya Palmer , Nick Ward
- 👤 James Scott , Zekarias Haile
- 👤 deleted-U04TA486SM6 , Rose Fleming
- 👤 deleted-U04GZ79CPNG , Rose Fleming
- 👤 deleted-U06F9N9PB2A , Dustin Surwill
- 👤 deleted-U06C7A8PVLJ , Jehoshua Josue
- 👤 Caleb Peters , deleted-U04R23BEW3V
- 👤 Greg Owen , deleted-U08E306T7SM
- 👤 Rose Fleming , James Turner
- 👤 ahsan , GitHub
- 👤 deleted-U072B7ZV4SH , Dustin Surwill
- 👤 deleted-U06GD22CLDC , ahsan
- 👤 deleted-U06CVB2MHRN , Zekarias Haile
- 👤 Dustin Surwill , deleted-U08FJ290LUX
- 👤 Kelly C. Richardson, EdS , John Gillespie
- 👤 Greg Owen , Lee Zafra
- 👤 David Evans , Kimberly Hubbard
- 👤 James Turner , Jehoshua Josue
- 👤 Cameron Rentch , Jehoshua Josue
- 👤 Google Calendar , john
- 👤 Dwight Thomas , Yan Ashrapov
- 👤 Joe Santana , IT SUPPORT - Dennis Shaull
- 👤 Daniel Schussler , deleted-U07PQ4H089G
- 👤 deleted-U05EFH3S2TA , Rose Fleming
- 👤 Nsay Y , Amanda Hembree
- 👤 Nick Ward , Welcome message
- 👤 deleted-U06C7A8PVLJ , Welcome message
- 👤 sean , Melanie Macias
- 👤 deleted-U04GG7BCZ5M , Dustin Surwill
- 👤 deleted-U06GD22CLDC , Welcome message
- 👤 Zekarias Haile , Jehoshua Josue
- 👤 Andy Rogers , Rose Fleming
- 👤 deleted-U059JKB35RU , Lee Zafra
- 👤 Maximus , deleted-U05F548NU5V
- 👤 Mark Maniora , Yan Ashrapov
- 👤 Nicholas McFadden , Edward Weber
- 👤 Mark Hines , Yan Ashrapov
- 👤 Dustin Surwill , Jehoshua Josue
- 👤 Luis Cortes , deleted-U04R23BEW3V
- 👤 deleted-U06C7A8PVLJ , darrell
- 👤 Cameron Rentch , deleted-U05G9BGQFBJ
- 👤 James Turner , deleted-U08E306T7SM
- 👤 Nicholas McFadden , Lee Zafra
- 👤 Nicholas McFadden , deleted-U07SBM5MB32
- 👤 Rose Fleming , Zekarias Haile
- 👤 Dustin Surwill , deleted-U07PQ4H089G
- 👤 deleted-U05EFH3S2TA , James Turner
- 👤 deleted-U06C7A8PVLJ , Daniel Schussler
- 👤 Google Calendar , CC Kitanovski
- 👤 Malissa Phillips , CC Kitanovski
- 👤 Richard Schnitzler , Richard Schnitzler
- 👤 Nick Ward , Jehoshua Josue
- 👤 Cameron Rentch , CC Kitanovski
- 👤 deleted-U055HQT39PC , Joe Santana
- 👤 Nicholas McFadden , Richard Schnitzler
- 👤 Joe Santana , Richard Schnitzler
- 👤 Google Calendar , Richard Schnitzler
- 👤 Dustin Surwill , Richard Schnitzler
- 👤 Daniel Schussler , Richard Schnitzler
- 👤 Greg Owen , deleted-U08FJ290LUX
- 👤 Nicholas McFadden , CC Kitanovski
- 👤 Ryan Vaspra , Daniel Schussler
- 👤 deleted-U06F9N9PB2A , CC Kitanovski
- 👤 Joe Santana , David Evans
- 👤 Kelly C. Richardson, EdS , Joe Woods
- 👤 Sean Marshall , Dustin Surwill
- 👤 Jira , Daniel Schussler
- 👤 Maximus , James Turner
- 👤 deleted-U05QUSWUJA2 , James Turner
- 👤 Nick Ward , Richard Schnitzler
- 👤 Jira , Richard Schnitzler
- 👤 Melanie Macias , CC Kitanovski
- 👤 Anthony Soboleski , Richard Schnitzler
- 👤 James Turner , deleted-U08N0J1U7GD
- 👤 Jira , Edward Weber
- 👤 deleted-U01AJT99FAQ , Joe Santana
- 👤 Dorshan Millhouse , deleted-U08RHDRJKP0
- 👤 Lee Zafra , Nsay Y
- 👤 deleted-U05EFH3S2TA , Dustin Surwill
- 👤 Joe Santana , deleted-U05EFH3S2TA
- 👤 James Turner , deleted-U08T4FKSC04
- 👤 Jira , Dustin Surwill
- 👤 James Turner , deleted-U08FJ290LUX
- 👤 Mark Hines , James Turner
- 👤 Nicholas McFadden , Chris Krecicki
- 👤 Richard Schnitzler , Chris Krecicki
- 👤 James Scott , Chris Krecicki
- 👤 Greg Owen , Daniel Schussler
- 👤 Dwight Thomas , Richard Schnitzler
- 👤 Tyson Green , Tyson Green
- 👤 Dustin Surwill , Tyson Green
- 👤 Google Calendar , Tyson Green
- 👤 Andy Rogers , Chris Krecicki
- 👤 Dustin Surwill , Chris Krecicki
- 👤 Tyson Green , Connie Bronowitz
- 👤 Jira , Nick Ward
- 👤 Nsay Y , Connie Bronowitz
- 👤 Joe Santana , deleted-U06F9N9PB2A
- 👤 Joe Santana , Tyson Green
- 👤 Chris Krecicki , Tyson Green
- 👤 Luis Cortes , James Turner
- 👤 Andy Rogers , Joe Santana
- 👤 Edward Weber , Chris Krecicki
- 👤 Joe Santana , Chris Krecicki
- 👤 Nick Ward , Chris Krecicki
- 👤 James Turner , deleted-U08SZHALMBM
- 👤 Jehoshua Josue , Chris Krecicki
- 👤 Ryan Vaspra , Chris Krecicki
- 👤 Nicholas McFadden , Tyson Green
- 👤 Chris Krecicki , Connie Bronowitz
- 👤 Ryan Vaspra , Edward Weber
- 👤 Henri Engle , Chris Krecicki
- 👤 James Turner , Carter Matzinger
- 👤 Joe Santana , Connie Bronowitz
- 👤 Cameron Rentch , Carter Matzinger
- 👤 Carter Matzinger , Carter Matzinger
- 👤 Connie Bronowitz , Carter Matzinger
- 👤 Confluence , Richard Schnitzler
- 👤 deleted-U06F9N9PB2A , James Turner
- 👤 deleted-U04HFGHL4RW , Dustin Surwill
- 👤 Joe Santana , Carter Matzinger
- 👤 Dustin Surwill , Carter Matzinger
- 👤 Dustin Surwill , Edward Weber
- 👤 Nick Ward , Edward Weber
- 👤 Mark Maniora , Carter Matzinger
- 👤 Daniel Schussler , Carter Matzinger
- 👤 Richard Schnitzler , Carter Matzinger
- 👤 Mark Maniora , Chris Krecicki
- 👤 deleted-UCBB2GYLR , Ryan Vaspra
- 👤 Malissa Phillips , Carter Matzinger
- 👤 Brian Hirst , deleted-U07AD5U5E6S
- 👤 Confluence , Nicholas McFadden
- 👤 Confluence , Dustin Surwill
- 👤 Nicholas McFadden , Carter Matzinger
- 👤 James Turner , Chris Krecicki
- 👤 Cameron Rentch , Chris Krecicki
- 👤 Confluence , Edward Weber
- 👤 Confluence , Joe Santana
- 👤 Edward Weber , Carter Matzinger
- 👤 Jira , Zekarias Haile
- 👤 Dwight Thomas , Chris Krecicki
- 👤 deleted-U04GG7BCZ5M , Greg Owen
- 👤 David Evans , Jennifer Durnell
- 👤 Dwight Thomas , Tyson Green
- 👤 Chris Krecicki , Carter Matzinger
- 👤 deleted-U05496RCQ9M , Carter Matzinger
- 👤 Jennifer Durnell , CC Kitanovski
- 👤 Andy Rogers , Carter Matzinger
- 👤 Joe Santana , deleted-U06C7A8PVLJ
- 👤 Jehoshua Josue , Richard Schnitzler
- 👤 James Scott , CC Kitanovski
- 👤 Maximus , Rose Fleming
- 👤 Joe Santana , Amanda Hembree
- 👤 CC Kitanovski , Chris Krecicki
- 👤 Joe Santana , Kimberly Barber
- 👤 David Evans , Connie Bronowitz
- 👤 Ryan Vaspra , CC Kitanovski
- 👤 Adrienne Hester , Kimberly Barber
- 👤 Ryan Vaspra , Carter Matzinger
- 👤 James Turner , CC Kitanovski
- 👤 Dustin Surwill , Henri Engle
- 👤 deleted-U06C7A8PVLJ , Chris Krecicki
- 👤 Dustin Surwill , CC Kitanovski
- 👤 James Turner , deleted-U08LK2U7YBW
- 👤 Brian Hirst , CC Kitanovski
- 👤 Anthony Soboleski , Chris Krecicki
- 👤 Dustin Surwill , Welcome message
- 👤 Tyson Green , Kimberly Barber
- 👤 Edward Weber , Welcome message
- 👤 Nick Ward , Welcome message
- 👤 deleted-U06VDQGHZLL , Dustin Surwill
- 👤 Google Drive , Richard Schnitzler
- 👤 Jehoshua Josue , Tyson Green
- 👤 Kris Standley , Yan Ashrapov
- 👤 Andy Rogers , CC Kitanovski
- 👤 deleted-U06C7A8PVLJ , Welcome message
- 👤 Ralecia Marks , Tyson Green
- 👤 James Turner , Item status notification
- 👤 Carter Matzinger , Welcome message
- 👤 Ryan Vaspra , deleted-U042MMWVCH2
- 👤 deleted-U042MMWVCH2 , Adrienne Hester
- 👤 deleted-U059JKB35RU , Julie-Margaret Johnson
- 👤 deleted-U042MMWVCH2 , korbin
- 👤 deleted-U059JKB35RU , Melanie Macias
- 👤 deleted-U059JKB35RU , Jennifer Durnell
- 👤 Ryan Vaspra , deleted-U02JM6UC78T
- 👤 deleted-U02JM6UC78T , Kris Standley
- 👤 Joe Santana , deleted-U08N0J1U7GD
- 👤 Joe Santana , deleted-U08SZHALMBM
- 👤 deleted-U6Z58C197 , James Turner
- 👤 Ryan Vaspra , deleted-U0410U6Q8J3
- 👤 Brian Hirst , deleted-U0410U6Q8J3
- 👤 deleted-U05G9BGQFBJ , Yan Ashrapov
- 👤 Cameron Rentch , deleted-U05G9BHC4GY
- 👤 Brian Hirst , deleted-U04KC9L4HRB
- 👤 Mike Everhart , deleted-U04KC9L4HRB
- 👤 Cameron Rentch , deleted-U04KC9L4HRB
- 👤 Brian Hirst , deleted-U04HFGHL4RW
- 👤 LaToya Palmer , deleted-U04KC9L4HRB
- 👤 Cameron Rentch , deleted-U04HFGHL4RW
- 👤 Ryan Vaspra , deleted-U04GZ79CPNG
- 👤 luke , deleted-U04GZ79CPNG
- 👤 Ryan Vaspra , deleted-U04HFGHL4RW
- 👤 Brian Hirst , deleted-U04GZ79CPNG
- 👤 Andy Rogers , deleted-U04GZ79CPNG
- 👤 Brian Hirst , deleted-U04GU9EUV9A
- 👤 Mike Everhart , deleted-U04HFGHL4RW
- 👤 LaToya Palmer , deleted-U05DY7UGM2L
- 👤 Adrienne Hester , deleted-U05DY7UGM2L
- 👤 Luis Cortes , deleted-U04KC9L4HRB
- 👤 deleted-U04GZ79CPNG , Mark Maniora
- 👤 Ryan Vaspra , deleted-U05QUSWUJA2
- 👤 deleted-U04R23BEW3V , Mark Maniora
- 👤 Ryan Vaspra , deleted-U04R23BEW3V
- 👤 luke , deleted-U05R2LQKHHR
- 👤 Tony , deleted-U05M3DME3GR
- 👤 Ryan Vaspra , deleted-U055HQT39PC
- 👤 deleted-U04GZ79CPNG , Julie-Margaret Johnson
- 👤 brettmichael , deleted-U04GWKX1RKM
- 👤 Cameron Rentch , deleted-U04GU9EUV9A
- 👤 Cameron Rentch , deleted-U05EFH3S2TA
- 👤 deleted-U04GZ79CPNG , Dwight Thomas
- 👤 Mark Maniora , deleted-U05R2LQKHHR
- 👤 Ryan Vaspra , deleted-U04GU9EUV9A
- 👤 Ryan Vaspra , deleted-U06AYDQ4WVA
- 👤 Andy Rogers , deleted-U06AYDQ4WVA
- 👤 luke , deleted-U06C7A8PVLJ
- 👤 Andy Rogers , deleted-U04R23BEW3V
- 👤 luke , deleted-U06AYDQ4WVA
- 👤 deleted-U04GZ79CPNG , debora
- 👤 Tony , deleted-U06AYDQ4WVA
- 👤 John Gillespie , deleted-U06AYDQ4WVA
- 👤 Adrienne Hester , deleted-U05QUSWUJA2
- 👤 Mike Everhart , deleted-U06GKHHCDNF
- 👤 ian , deleted-U06AYDQ4WVA
- 👤 debora , deleted-U06AYDQ4WVA
- 👤 Mike Everhart , deleted-U055HQT39PC
- 👤 deleted-U04HFGHL4RW , Altonese Neely
- 👤 deleted-U04GU9EUV9A , Altonese Neely
- 👤 Andy Rogers , deleted-U04GU9EUV9A
- 👤 Adrienne Hester , deleted-U04TA486SM6
- 👤 deleted-U06AYDQ4WVA , Altonese Neely
- 👤 Nicholas McFadden , deleted-U06AYDQ4WVA
- 👤 John Gillespie , deleted-U054PFD3Q6N
- 👤 deleted-U04R23BEW3V , korbin
- 👤 deleted-U04GZ79CPNG , Adrienne Hester
- 👤 Greg Owen , deleted-U06N28XTLE7
- 👤 Nicholas McFadden , deleted-U06N28XTLE7
- 👤 Tony , deleted-U06GKHHCDNF
- 👤 Mike Everhart , deleted-U06AYDQ4WVA
- 👤 luke , deleted-U06N28XTLE7
- 👤 John Gillespie , deleted-U05D70MB62W
- 👤 deleted-U04GZ79CPNG , brian580
- 👤 Ryan Vaspra , deleted-U06N28XTLE7
- 👤 deleted-U04HFGHL4RW , brian580
- 👤 John Gillespie , deleted-U06S99AE6C9
- 👤 Luis Cortes , deleted-U072JS2NHRQ
- 👤 Greg Owen , deleted-U072JS2NHRQ
- 👤 LaToya Palmer , deleted-U06AYDQ4WVA
- 👤 Cameron Rentch , deleted-U055HQT39PC
- 👤 Cameron Rentch , deleted-U05ANA2ULDD
- 👤 Cameron Rentch , deleted-U071ST51P18
- 👤 Dwight Thomas , deleted-U05QUSWUJA2
- 👤 korbin , deleted-U06GD22CLDC
- 👤 deleted-U04HFGHL4RW , Nicholas McFadden
- 👤 deleted-U04R23BEW3V , ahsan
- 👤 deleted-U05DY7UGM2L , korbin
- 👤 Brittany Barnett , deleted-U05EFH3S2TA
- 👤 Cameron Rentch , deleted-U072JS2NHRQ
- 👤 Ryan Vaspra , deleted-U072B7ZV4SH
- 👤 Andy Rogers , deleted-U072JS2NHRQ
- 👤 Nicholas McFadden , deleted-U06C7A8PVLJ
- 👤 deleted-U05496RCQ9M , Mark Maniora
- 👤 deleted-U072JS2NHRQ , Malissa Phillips
- 👤 brian580 , deleted-U072JS2NHRQ
- 👤 Ryan Vaspra , deleted-U05PM8ZHCF4
- 👤 Mike Everhart , deleted-U05PM8ZHCF4
- 👤 deleted-U05EFH3S2TA , Vilma Farrar
- 👤 deleted-U04GZ79CPNG , Ralecia Marks
- 👤 Tony Jones , deleted-U06N28XTLE7
- 👤 Nicholas McFadden , deleted-U072B7ZV4SH
- 👤 deleted-U06NZP17L83 , Daniel Schussler
- 👤 deleted-U05EFH3S2TA , Malissa Phillips
- 👤 deleted-U06N28XTLE7 , ahsan
- 👤 deleted-U05496RCQ9M , Nick Ward
- 👤 deleted-U05496RCQ9M , James Turner
- 👤 deleted-U05496RCQ9M , Zekarias Haile
- 👤 deleted-U06NZP17L83 , James Turner
- 👤 deleted-U04GZ79CPNG , ahsan
- 👤 deleted-U06C7A8PVLJ , James Turner
- 👤 deleted-U05496RCQ9M , ahsan
- 👤 Nick Ward , deleted-U072JS2NHRQ
- 👤 deleted-U05496RCQ9M , Dustin Surwill
- 👤 deleted-U06C7A8PVLJ , Nick Ward
- 👤 deleted-U05DY7UGM2L , Malissa Phillips
- 👤 Nicholas McFadden , deleted-U072JS2NHRQ
- 👤 deleted-U072JS2NHRQ , James Turner
- 👤 Dwight Thomas , deleted-U0679HSE82K
- 👤 deleted-U05ANA2ULDD , Nick Ward
- 👤 Brian Hirst , deleted-U072JS2NHRQ
- 👤 deleted-U04HFGHL4RW , Nsay Y
- 👤 deleted-U06AYDQ4WVA , VernonEvans
- 👤 Tony , deleted-U05EFH3S2TA
- 👤 Cameron Rentch , deleted-U07JFNH9C7P
- 👤 Ryan Vaspra , deleted-U06C7A8PVLJ
- 👤 deleted-U04R23BEW3V , Yan Ashrapov
- 👤 deleted-U072JS2NHRQ , Dustin Surwill
- 👤 Dwight Thomas , deleted-U072JS2NHRQ
- 👤 brian580 , deleted-U071ST51P18
- 👤 Nsay Y , deleted-U06AYDQ4WVA
- 👤 Nicholas McFadden , deleted-U06GD22CLDC
- 👤 deleted-U05496RCQ9M , Greg Owen
- 👤 Nsay Y , deleted-U081KUX6TKM
- 👤 deleted-U05496RCQ9M , Malissa Phillips
- 👤 deleted-U05QUSWUJA2 , brian580
- 👤 deleted-U06N28XTLE7 , Dustin Surwill
- 👤 Cameron Rentch , deleted-U04TA486SM6
- 👤 Cameron Rentch , deleted-U07097NJDA7
- 👤 Dustin Surwill , deleted-U07SBM5MB32
- 👤 Cameron Rentch , deleted-U06F9N9PB2A
- 👤 deleted-U06GD22CLDC , Dustin Surwill
- 👤 Nick Ward , deleted-U07SBM5MB32
- 👤 Andy Rogers , deleted-U062D2YJ15Y
- 👤 deleted-U05QUSWUJA2 , ahsan
- 👤 Mike Everhart , deleted-U05QUSWUJA2
- 👤 Mark Maniora , deleted-U062D2YJ15Y
- 👤 deleted-U04GZ79CPNG , darrell
- 👤 Mark Hines , deleted-U07JFNH9C7P
- 👤 deleted-U06GD22CLDC , Daniel Schussler
- 👤 deleted-U062D2YJ15Y , Dustin Surwill
- 👤 Cameron Rentch , deleted-U083HCG9AUR
- 👤 Ryan Vaspra , deleted-U083HCG9AUR
- 👤 Nicholas McFadden , deleted-U083HCG9AUR
- 👤 deleted-U04GG7BCZ5M , Nicholas McFadden
- 👤 Malissa Phillips , deleted-U07SBM5MB32
- 👤 deleted-U07SBM5MB32 , IT SUPPORT - Dennis Shaull
- 👤 Nicholas McFadden , deleted-U06CVB2MHRN
- 👤 deleted-U072B7ZV4SH , Malissa Phillips
- 👤 Nsay Y , deleted-U06MDMJ4X96
- 👤 ahsan , deleted-U07SBM5MB32
- 👤 deleted-U072JS2NHRQ , Aidan Celeste
- 👤 Vilma Farrar , deleted-U077J4CPUCC
- 👤 darrell , deleted-U072JS2NHRQ
- 👤 Mike Everhart , deleted-U04J34Q7V4H
- 👤 deleted-U04GG7BCZ5M , ahsan
- 👤 Aidan Celeste , deleted-U08FJ290LUX
- 👤 IT SUPPORT - Dennis Shaull , deleted-U08E306T7SM
- 👤 Aidan Celeste , deleted-U083HCG9AUR
- 👤 deleted-U04R23BEW3V , Greg Owen
- 👤 Dwight Thomas , deleted-U07LSBPN6D8
- 👤 deleted-U06CVB2MHRN , James Turner
- 👤 Dustin Surwill , deleted-U08GMHAPRK2
- 👤 Nick Ward , deleted-U08LK2U7YBW
- 👤 deleted-U04GZ79CPNG , Zekarias Haile
- 👤 Zekarias Haile , deleted-U07SBM5MB32
- 👤 deleted-U06K9EUEPLY , darrell
- 👤 deleted-U04HTA3157W , Amanda Hembree
- 👤 Joe Santana , deleted-U083HCG9AUR
- 👤 Brian Hirst , deleted-U06C7A8PVLJ
- 👤 Cameron Rentch , deleted-U05QUSWUJA2
- 👤 Nicholas McFadden , deleted-U07JFNH9C7P
- 👤 deleted-U04GZ79CPNG , Jehoshua Josue
- 👤 deleted-U072JS2NHRQ , Jehoshua Josue
- 👤 deleted-U06C7A8PVLJ , Richard Schnitzler
- 👤 deleted-U05EFH3S2TA , Richard Schnitzler
- 👤 Mark Maniora , deleted-U06C7A8PVLJ
- 👤 Andy Rogers , deleted-U06F9N9PB2A
- 👤 Ryan Vaspra , deleted-U07CRGCBVJA
- 👤 Andy Rogers , deleted-U06C7A8PVLJ
- 👤 Andy Rogers , deleted-U05EFH3S2TA
- 👤 deleted-U04GZ79CPNG , Chris Krecicki
- 👤 Nicholas McFadden , deleted-U095QBJFFME
- 👤 deleted-U05EFH3S2TA , Carter Matzinger
- 👤 Aidan Celeste , deleted-U08GMHAPRK2
- 👤 deleted-U04GZ79CPNG , Carter Matzinger
- 👤 deleted-U06CR5MH88H , Malissa Phillips
- 👤 deleted-U06C7A8PVLJ , Carter Matzinger
- 👤 Cameron Rentch , deleted-U056TJH4KUL
- 👤 Tony , deleted-U056TJH4KUL
- 👤 Ryan Vaspra , deleted-U056TJH4KUL
- 👤 Ryan Vaspra , deleted-U05CTUBCP7E
- 👤 Ryan Vaspra , deleted-U05CXRE6TBK
- 👤 Adrienne Hester , deleted-U05CTUBCP7E
- 👤 Nicholas McFadden , deleted-U07PQ4H089G
- 👤 Ryan Vaspra , deleted-U069G4WMMD4
- 👤 Dorshan Millhouse , deleted-U08RRDQCPU2
Group Direct Messages
- 👥 Jack Altunyan, Cameron Rentch, Maximus,
- 👥 Cameron Rentch, Ryan Vaspra, Maximus,
- 👥 Cameron Rentch, Ryan Vaspra, Mark Hines,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra,
- 👥 Cameron Rentch, Ryan Vaspra, Tony,
- 👥 Cameron Rentch, john, Caleb Peters,
- 👥 Cameron Rentch, Ryan Vaspra, Kelly C. Richardson, EdS,
- 👥 Cameron Rentch, Ryan Vaspra, Brian Hirst,
- 👥 Cameron Rentch, Ryan Vaspra, Kris Standley,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers,
- 👥 Cameron Rentch, Tony, brettmichael, deleted-U04GU9EUV9A,
- 👥 Ryan Vaspra, Maximus, Mark Hines,
- 👥 Chris, David Temmesfeld, Dorshan Millhouse,
- 👥 Ryan Vaspra, Mark Hines, LaToya Palmer,
- 👥 Mike Everhart, Ryan Vaspra, Maximus,
- 👥 Ryan Vaspra, Kelly C. Richardson, EdS, LaToya Palmer,
- 👥 Mike Everhart, Cameron Rentch, Mark Hines,
- 👥 Cameron Rentch, Andy Rogers, craig,
- 👥 Mike Everhart, Cameron Rentch, john,
- 👥 Jack Altunyan, Ryan Vaspra, Maximus, Caleb Peters,
- 👥 Mike Everhart, Mark Hines, LaToya Palmer,
- 👥 Ryan Vaspra, Andy Rogers, luke,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, luke,
- 👥 Mike Everhart, Ryan Vaspra, LaToya Palmer,
- 👥 Cameron Rentch, Mark Hines, Andy Rogers,
- 👥 Tony, Andy Rogers, craig,
- 👥 Ryan Vaspra, Andy Rogers, Adrienne Hester,
- 👥 Ryan Vaspra, Kelly C. Richardson, EdS, LaToya Palmer, Adrienne Hester,
- 👥 Ryan Vaspra, LaToya Palmer, Adrienne Hester,
- 👥 Mike Everhart, Ryan Vaspra, Andy Rogers,
- 👥 sean, Cameron Rentch, Andy Rogers,
- 👥 Mike Everhart, deleted-U04GZ79CPNG, deleted-U04KC9L4HRB,
- 👥 Cameron Rentch, Ryan Vaspra, luke,
- 👥 Mike Everhart, Cameron Rentch, deleted-U056TJH4KUL,
- 👥 Mike Everhart, Cameron Rentch, Mark Maniora,
- 👥 Cameron Rentch, Ryan Vaspra, deactivateduser594162, Caleb Peters, deactivateduser497326,
- 👥 Cameron Rentch, Brian Hirst, Mark Maniora,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, Adrienne Hester,
- 👥 Mike Everhart, Cameron Rentch, Brian Hirst,
- 👥 Ryan Vaspra, Brian Hirst, luke,
- 👥 Cameron Rentch, Tony, deleted-U056TJH4KUL,
- 👥 Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U04KC9L4HRB,
- 👥 silvia, Cameron Rentch, Tony, deleted-U056TJH4KUL, deleted-U05DY7UGM2L,
- 👥 Jack Altunyan, Cameron Rentch, Maximus, Caleb Peters,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U05DY7UGM2L,
- 👥 deleted-U042MMWVCH2, Adrienne Hester, deleted-U059JKB35RU,
- 👥 Ryan Vaspra, luke, Adrienne Hester,
- 👥 Cameron Rentch, luke, deleted-U05DY7UGM2L,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, LaToya Palmer, Adrienne Hester,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, LaToya Palmer,
- 👥 Cameron Rentch, Ryan Vaspra, LaToya Palmer,
- 👥 Cameron Rentch, Tony, Andy Rogers, brettmichael,
- 👥 Cameron Rentch, Andy Rogers, Adrienne Hester,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U056TJH4KUL,
- 👥 Mike Everhart, Brian Hirst, Dwight Thomas,
- 👥 Cameron Rentch, Andy Rogers, LaToya Palmer, Adrienne Hester,
- 👥 Cameron Rentch, Andy Rogers, LaToya Palmer,
- 👥 Ryan Vaspra, Andy Rogers, deleted-U05DY7UGM2L,
- 👥 Ryan Vaspra, Caleb Peters, Andy Rogers, LaToya Palmer, Adrienne Hester, Lee Zafra,
- 👥 Andy Rogers, LaToya Palmer, Adrienne Hester,
- 👥 Andy Rogers, deleted-U04GZ79CPNG, Greg Owen,
- 👥 Cameron Rentch, Ryan Vaspra, luke, deleted-U05DY7UGM2L,
- 👥 silvia, Cameron Rentch, deactivateduser717106, Rose Fleming, debora,
- 👥 Cameron Rentch, Andy Rogers, debora,
- 👥 Cameron Rentch, Tony, deleted-U05DY7UGM2L,
- 👥 Cameron Rentch, Maximus, Caleb Peters,
- 👥 LaToya Palmer, Adrienne Hester, Greg Owen, Julie-Margaret Johnson,
- 👥 Cameron Rentch, Andy Rogers, Greg Owen,
- 👥 LaToya Palmer, Adrienne Hester, Greg Owen,
- 👥 Cameron Rentch, Ryan Vaspra, Nicholas McFadden,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, Andy Rogers,
- 👥 Ryan Vaspra, Tony, Andy Rogers, deleted-U04KC9L4HRB,
- 👥 Mike Everhart, Caleb Peters, Dwight Thomas,
- 👥 Cameron Rentch, Andy Rogers, Mark Maniora,
- 👥 Ryan Vaspra, luke, Mark Maniora,
- 👥 Mike Everhart, Ryan Vaspra, deleted-U05DY7UGM2L,
- 👥 Mike Everhart, Jack Altunyan, Dwight Thomas,
- 👥 Cameron Rentch, deleted-U05DY7UGM2L, michaelbrunet,
- 👥 Cameron Rentch, Tony, deleted-U04GU9EUV9A, deleted-U05DY7UGM2L, deleted-U05EFH3S2TA, michaelbrunet,
- 👥 Cameron Rentch, deleted-U056TJH4KUL, deleted-U05DY7UGM2L,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04GZ79CPNG, deleted-U04KC9L4HRB, deleted-U06C7A8PVLJ,
- 👥 Ryan Vaspra, luke, Quint Underwood,
- 👥 Cameron Rentch, Ryan Vaspra, debora,
- 👥 Cameron Rentch, Ryan Vaspra, luke, Mark Maniora, debora,
- 👥 LaToya Palmer, Adrienne Hester, Julie-Margaret Johnson,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, Michael McKinney,
- 👥 Cameron Rentch, Andy Rogers, deleted-U05DY7UGM2L, debora, Nsay Y, brian580, Altonese Neely,
- 👥 Ryan Vaspra, Tony, debora,
- 👥 Cameron Rentch, Tony, brettmichael,
- 👥 Mike Everhart, Ryan Vaspra, Michael McKinney,
- 👥 Cameron Rentch, Ryan Vaspra, Chris, debora,
- 👥 Cameron Rentch, deleted-U04GU9EUV9A, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA,
- 👥 Cameron Rentch, debora, brian580, Altonese Neely,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U04KC9L4HRB, michaelbrunet, deleted-U067A4KAB9U, rachel,
- 👥 Jack Altunyan, Cameron Rentch, Caleb Peters,
- 👥 debora, brian580, Altonese Neely,
- 👥 Cameron Rentch, deleted-U04GU9EUV9A, deleted-U04HFGHL4RW, deleted-U04KC9L4HRB, deleted-U05EFH3S2TA, michaelbrunet,
- 👥 Ryan Vaspra, Nicholas McFadden, James Scott,
- 👥 Cameron Rentch, Andy Rogers, debora, brian580, Altonese Neely,
- 👥 Cameron Rentch, michaelbrunet, deleted-U067A4KAB9U,
- 👥 Tony, debora, brian580, Altonese Neely,
- 👥 Cameron Rentch, deleted-U04KC9L4HRB, michaelbrunet, deleted-U067A4KAB9U, rachel,
- 👥 Ryan Vaspra, debora, Lee Zafra, Nsay Y,
- 👥 Cameron Rentch, Maximus, Andy Rogers,
- 👥 Cameron Rentch, Joe Santana, michaelbrunet,
- 👥 Ryan Vaspra, Caleb Peters, debora, Nsay Y,
- 👥 Cameron Rentch, Tony, Andy Rogers, deleted-U04GU9EUV9A,
- 👥 Ryan Vaspra, Andy Rogers, deleted-U069G4WMMD4,
- 👥 Mike Everhart, Dwight Thomas, Michael McKinney,
- 👥 Ryan Vaspra, Andy Rogers, Adrienne Hester, Julie-Margaret Johnson, Lee Zafra,
- 👥 Jack Altunyan, Cameron Rentch, Michael McKinney,
- 👥 Cameron Rentch, Andy Rogers, debora, Altonese Neely,
- 👥 Ryan Vaspra, Tony, deleted-U04KC9L4HRB, deleted-U05EFH3S2TA,
- 👥 Ryan Vaspra, luke, deleted-U04GZ79CPNG, deleted-U04KC9L4HRB,
- 👥 Adrienne Hester, korbin, Lee Zafra,
- 👥 Cameron Rentch, Ryan Vaspra, debora, Nsay Y, brian580, Altonese Neely,
- 👥 Ryan Vaspra, Brian Hirst, luke, Nicholas McFadden,
- 👥 Ryan Vaspra, Andy Rogers, luke, Altonese Neely,
- 👥 Mike Everhart, Ryan Vaspra, Brian Hirst, luke, Nicholas McFadden, Quint Underwood, James Scott,
- 👥 Cameron Rentch, Ryan Vaspra, luke, Michael McKinney,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U04KC9L4HRB,
- 👥 Tony, deleted-U05M3DME3GR, debora,
- 👥 Mike Everhart, Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U04KC9L4HRB, michaelbrunet, deleted-U067A4KAB9U, rachel,
- 👥 Mark Maniora, Dwight Thomas, Nicholas McFadden, Greg Owen,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04KC9L4HRB, michaelbrunet,
- 👥 Ryan Vaspra, Tony, Andy Rogers, luke, deleted-U04GU9EUV9A, deleted-U04KC9L4HRB,
- 👥 Andy Rogers, deleted-U05DY7UGM2L, Nsay Y,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04GU9EUV9A, deleted-U04GZ79CPNG, deleted-U04KC9L4HRB, deleted-U06AYDQ4WVA,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, michaelbrunet,
- 👥 Cameron Rentch, Ryan Vaspra, parsa,
- 👥 Mark Maniora, Nicholas McFadden, Greg Owen,
- 👥 Cameron Rentch, debora, Nsay Y,
- 👥 Cameron Rentch, deleted-U05DY7UGM2L, michaelbrunet, deleted-U067A4KAB9U, Nsay Y,
- 👥 Cameron Rentch, Ryan Vaspra, Tony, Andy Rogers, LaToya Palmer, deleted-U04GU9EUV9A,
- 👥 Cameron Rentch, Andy Rogers, patsy,
- 👥 LaToya Palmer, Adrienne Hester, Dwight Thomas,
- 👥 Cameron Rentch, debora, Altonese Neely,
- 👥 Cameron Rentch, Ryan Vaspra, Kelly C. Richardson, EdS, Andy Rogers, LaToya Palmer, Adrienne Hester, korbin, deleted-U069G4WMMD4,
- 👥 Cameron Rentch, Ryan Vaspra, Tony, debora, brian580, Altonese Neely,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, parsa,
- 👥 Ryan Vaspra, Andy Rogers, korbin,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, Dwight Thomas,
- 👥 Cameron Rentch, Dorshan Millhouse, Michael McKinney,
- 👥 Ryan Vaspra, Adrienne Hester, korbin,
- 👥 Ryan Vaspra, LaToya Palmer, Adrienne Hester, korbin,
- 👥 Ryan Vaspra, Tony, deleted-U04R23BEW3V, korbin,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, Fabian De Simone,
- 👥 Nsay Y, brian580, Altonese Neely,
- 👥 Jack Altunyan, Cameron Rentch, Ryan Vaspra, Maximus, Caleb Peters, debora, Altonese Neely,
- 👥 Jack Altunyan, Cameron Rentch, Ryan Vaspra, debora, Altonese Neely,
- 👥 Ryan Vaspra, Andy Rogers, deleted-U05CTUBCP7E,
- 👥 brian580, Altonese Neely, parsa,
- 👥 Cameron Rentch, Ryan Vaspra, michaelbrunet, James Scott,
- 👥 Ryan Vaspra, Andy Rogers, patsy,
- 👥 Mike Everhart, Jack Altunyan, Ryan Vaspra, parsa,
- 👥 Andy Rogers, brian580, Altonese Neely,
- 👥 deleted-U04HFGHL4RW, brian580, Altonese Neely,
- 👥 Mike Everhart, Dwight Thomas, Greg Owen,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, deleted-U04KC9L4HRB, Adrienne Hester, korbin, deleted-U067A4KAB9U,
- 👥 Ryan Vaspra, Andy Rogers, Adrienne Hester, korbin,
- 👥 Adrienne Hester, deleted-U05CTUBCP7E, deleted-U069G4WMMD4,
- 👥 Ryan Vaspra, Tony, Andy Rogers, deleted-U04GZ79CPNG, deleted-U04KC9L4HRB, Adrienne Hester, deleted-U067A4KAB9U,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04R23BEW3V,
- 👥 Ryan Vaspra, brian580, Altonese Neely,
- 👥 Cameron Rentch, Mark Hines, deleted-U04GU9EUV9A,
- 👥 Cameron Rentch, Rose Fleming, brian580, Altonese Neely,
- 👥 sean, Ryan Vaspra, luke,
- 👥 Cameron Rentch, Ryan Vaspra, Lee Zafra,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, Nicholas McFadden,
- 👥 Andy Rogers, Adrienne Hester, deleted-U04R23BEW3V, Greg Owen, patsy,
- 👥 Ryan Vaspra, Brian Hirst, luke, Mark Maniora,
- 👥 David Temmesfeld, Dorshan Millhouse, LaToya Palmer, Adrienne Hester,
- 👥 Cameron Rentch, deleted-U04GU9EUV9A, deleted-U04HFGHL4RW, deleted-U04R23BEW3V,
- 👥 Mark Hines, LaToya Palmer, Adrienne Hester,
- 👥 deleted-U04GZ79CPNG, Greg Owen, deleted-U06AYDQ4WVA, deleted-U06C7A8PVLJ, deleted-U06N28XTLE7,
- 👥 LaToya Palmer, Adrienne Hester, Mark Maniora, Dwight Thomas, Nicholas McFadden, Julie-Margaret Johnson, korbin, Lee Zafra,
- 👥 Ryan Vaspra, luke, parsa,
- 👥 Cameron Rentch, Chris, Andy Rogers, Adrienne Hester,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, deleted-U05DY7UGM2L,
- 👥 Mark Maniora, Dwight Thomas, Greg Owen,
- 👥 Ryan Vaspra, deleted-U055HQT39PC, James Scott,
- 👥 Brian Hirst, luke, Mark Maniora,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, deleted-U067A4KAB9U,
- 👥 deleted-U04GZ79CPNG, deleted-U04KC9L4HRB, korbin,
- 👥 Mike Everhart, deleted-U055HQT39PC, Dwight Thomas,
- 👥 Ryan Vaspra, Brian Hirst, Nicholas McFadden,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U05EFH3S2TA, michaelbrunet, deleted-U067A4KAB9U,
- 👥 Cameron Rentch, Tony, brettmichael, deleted-U04GU9EUV9A, deleted-U05EFH3S2TA,
- 👥 Cameron Rentch, Tony, Andy Rogers, debora,
- 👥 Cameron Rentch, Brian Hirst, luke, Mark Maniora,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U05EFH3S2TA,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, michaelbrunet, deleted-U067A4KAB9U,
- 👥 Ryan Vaspra, LaToya Palmer, Adrienne Hester, Julie-Margaret Johnson, Lee Zafra, Melanie Macias,
- 👥 Cameron Rentch, Maximus, Dorshan Millhouse,
- 👥 Ryan Vaspra, Brian Hirst, Andy Rogers, luke, Mark Maniora, brian580, Altonese Neely, patsy,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U056TJH4KUL, deleted-U05DY7UGM2L, James Scott,
- 👥 LaToya Palmer, Adrienne Hester, Mark Maniora, Dwight Thomas, Greg Owen, Julie-Margaret Johnson, korbin, Lee Zafra,
- 👥 Cameron Rentch, deleted-U04GU9EUV9A, deleted-U04HFGHL4RW, michaelbrunet, deleted-U067A4KAB9U,
- 👥 Ryan Vaspra, Mark Maniora, brian580, Altonese Neely,
- 👥 Andy Rogers, LaToya Palmer, Adrienne Hester, Mark Maniora, Dwight Thomas, Greg Owen, Julie-Margaret Johnson, korbin, Lee Zafra,
- 👥 Ryan Vaspra, Brian Hirst, luke, Nicholas McFadden, brian580, Altonese Neely,
- 👥 Cameron Rentch, Ryan Vaspra, brian580, Altonese Neely,
- 👥 Cameron Rentch, Ryan Vaspra, Tony, deleted-U04GZ79CPNG, Lee Zafra,
- 👥 Cameron Rentch, Andy Rogers, brian580, Altonese Neely,
- 👥 Ryan Vaspra, Tony, Adrienne Hester, Joe Santana, korbin,
- 👥 Dorshan Millhouse, brian580, Altonese Neely,
- 👥 deleted-U04GZ79CPNG, deleted-U04R23BEW3V, Nicholas McFadden,
- 👥 Cameron Rentch, Kelly C. Richardson, EdS, deleted-U05DY7UGM2L, brian580, Altonese Neely,
- 👥 Mike Everhart, Dwight Thomas, michaelbrunet,
- 👥 Cameron Rentch, Ryan Vaspra, Chris, Rose Fleming, brian580, Altonese Neely,
- 👥 deleted-U04GU9EUV9A, deleted-U055HQT39PC, Mark Maniora,
- 👥 Greg Owen, deleted-U06AYDQ4WVA, deleted-U06N28XTLE7,
- 👥 Cameron Rentch, deleted-U05DY7UGM2L, Nicholas McFadden,
- 👥 Cameron Rentch, Andy Rogers, deleted-U06AYDQ4WVA,
- 👥 Cameron Rentch, Ryan Vaspra, Nicholas McFadden, James Scott,
- 👥 Cameron Rentch, luke, deleted-U04GZ79CPNG, deleted-U06N28XTLE7,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04GU9EUV9A, deleted-U04HFGHL4RW, deleted-U055HQT39PC,
- 👥 Cameron Rentch, Mark Maniora, deleted-U05DY7UGM2L,
- 👥 Cameron Rentch, Andy Rogers, craig, brian580,
- 👥 Mike Everhart, Ryan Vaspra, Nicholas McFadden,
- 👥 Cameron Rentch, Tony, Andy Rogers, deleted-U04GU9EUV9A, deleted-U04GZ79CPNG,
- 👥 Ryan Vaspra, Tony, deleted-U04GU9EUV9A,
- 👥 Nicholas McFadden, darrell, Nick Ward,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, Brian Hirst, luke, Nicholas McFadden,
- 👥 Cameron Rentch, Ryan Vaspra, James Scott,
- 👥 deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, Nicholas McFadden, deleted-U06AYDQ4WVA, deleted-U06C7A8PVLJ, deleted-U06N28XTLE7,
- 👥 Adrienne Hester, Julie-Margaret Johnson, patsy,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, brian580,
- 👥 Cameron Rentch, michaelbrunet, deleted-U067A4KAB9U, myjahnee739, deleted-U071ST51P18,
- 👥 Adrienne Hester, Mark Maniora, Greg Owen,
- 👥 Cameron Rentch, Andy Rogers, brian580, Malissa Phillips,
- 👥 Mike Everhart, Ryan Vaspra, Nicholas McFadden, James Scott,
- 👥 Adrienne Hester, Mark Maniora, Dwight Thomas, Greg Owen,
- 👥 Cameron Rentch, craig, patsy,
- 👥 Cameron Rentch, Ryan Vaspra, Tony, Nicholas McFadden,
- 👥 Cameron Rentch, Tony, brettmichael, deleted-U04GU9EUV9A, deleted-U04R23BEW3V,
- 👥 Cameron Rentch, Andy Rogers, Nsay Y, brian580,
- 👥 Cameron Rentch, Ryan Vaspra, Tony, deleted-U04GU9EUV9A,
- 👥 Cameron Rentch, Ryan Vaspra, brian580,
- 👥 Cameron Rentch, brian580, myjahnee739,
- 👥 Greg Owen, brian580, Altonese Neely,
- 👥 Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U06AYDQ4WVA,
- 👥 Cameron Rentch, Ryan Vaspra, Tony, deleted-U04GU9EUV9A, brian580,
- 👥 Ryan Vaspra, Nicholas McFadden, deactivateduser168066,
- 👥 Cameron Rentch, michaelbrunet, brian580, myjahnee739,
- 👥 Cameron Rentch, michaelbrunet, myjahnee739,
- 👥 Greg Owen, deleted-U06AYDQ4WVA, deleted-U06N28XTLE7, deleted-U072JS2NHRQ,
- 👥 Tony, Brian Hirst, deleted-U04GU9EUV9A, deleted-U055HQT39PC, Mark Maniora,
- 👥 Ryan Vaspra, Andy Rogers, Adrienne Hester, deleted-U05DY7UGM2L, korbin,
- 👥 Ryan Vaspra, Andy Rogers, Adrienne Hester, deleted-U05DY7UGM2L,
- 👥 Ryan Vaspra, deleted-U05EFH3S2TA, brian580,
- 👥 Ryan Vaspra, LaToya Palmer, Nicholas McFadden,
- 👥 Chris, brian580, Altonese Neely,
- 👥 Mike Everhart, Dwight Thomas, Nicholas McFadden,
- 👥 Ryan Vaspra, Nicholas McFadden, Nick Ward,
- 👥 LaToya Palmer, Adrienne Hester, deleted-U05CTUBCP7E,
- 👥 deleted-U05CTUBCP7E, Dwight Thomas, deleted-U06K957RUGY,
- 👥 Ryan Vaspra, Tony, deleted-U04GU9EUV9A, deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, deleted-U06AYDQ4WVA,
- 👥 Cameron Rentch, Ryan Vaspra, Brian Hirst, Andy Rogers, luke, Mark Maniora, Greg Owen, patsy,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nicholas McFadden, michaelbrunet, myjahnee739, Nick Ward,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, deleted-U06C7A8PVLJ,
- 👥 Cameron Rentch, deleted-U05DY7UGM2L, deleted-U05EFH3S2TA,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, brian580,
- 👥 Andy Rogers, craig, brian580,
- 👥 Cameron Rentch, deleted-U04GU9EUV9A, deleted-U04HFGHL4RW, deleted-U05ANA2ULDD, deleted-U064HEU0MDJ, Nick Ward,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, john, Chris, David Temmesfeld,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, michaelbrunet, deleted-U067A4KAB9U, myjahnee739, deleted-U071ST51P18,
- 👥 Mike Everhart, Maximus, Dwight Thomas, ahsan,
- 👥 Adrienne Hester, Julie-Margaret Johnson, David Evans,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05DY7UGM2L, deleted-U05EFH3S2TA,
- 👥 Mike Everhart, Dwight Thomas, ahsan,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, Andy Rogers, Dwight Thomas,
- 👥 Cameron Rentch, Nicholas McFadden, darrell,
- 👥 Mark Hines, Brian Hirst, luke,
- 👥 Cameron Rentch, michaelbrunet, Nick Ward, Ralecia Marks,
- 👥 Cameron Rentch, michaelbrunet, Ralecia Marks,
- 👥 Cameron Rentch, Tony, deleted-U05EFH3S2TA, Nicholas McFadden, michaelbrunet, deleted-U067A4KAB9U, Nick Ward, deleted-U071ST51P18,
- 👥 Cameron Rentch, Andy Rogers, deleted-U05EFH3S2TA, Ralecia Marks,
- 👥 Mike Everhart, Caleb Peters, Dwight Thomas, ahsan,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U05EFH3S2TA, Ralecia Marks,
- 👥 Cameron Rentch, Tony, Andy Rogers, deleted-U055HQT39PC,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, michaelbrunet, deleted-U067A4KAB9U, deleted-U071ST51P18,
- 👥 Cameron Rentch, Ryan Vaspra, Tony Jones, Joe Santana, Nicholas McFadden, darrell, Nick Ward, Malissa Phillips,
- 👥 Cameron Rentch, michaelbrunet, darrell, Nick Ward,
- 👥 Cameron Rentch, michaelbrunet, deleted-U067A4KAB9U, deleted-U071ST51P18,
- 👥 Mike Everhart, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, Nicholas McFadden, Nick Ward,
- 👥 Mike Everhart, deleted-U055HQT39PC, Dwight Thomas, Nicholas McFadden, Nick Ward, ahsan,
- 👥 deleted-U055HQT39PC, Nicholas McFadden, Nick Ward,
- 👥 luke, Nicholas McFadden, deleted-U06N28XTLE7,
- 👥 Cameron Rentch, Ryan Vaspra, Brian Hirst, Mark Maniora,
- 👥 Ryan Vaspra, deleted-U055HQT39PC, Nick Ward,
- 👥 Jack Altunyan, Cameron Rentch, Ryan Vaspra, brian580,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, Brian Hirst, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Mark Maniora, Nicholas McFadden, Greg Owen, Nick Ward, Malissa Phillips,
- 👥 Cameron Rentch, brian580, Malissa Phillips,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Nicholas McFadden,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Nicholas McFadden, michaelbrunet, Nick Ward,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Nick Ward,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nicholas McFadden, michaelbrunet, Nick Ward,
- 👥 Cameron Rentch, Andy Rogers, Nicholas McFadden,
- 👥 Cameron Rentch, Greg Owen, brian580, Malissa Phillips,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW, Nicholas McFadden,
- 👥 LaToya Palmer, Adrienne Hester, David Evans,
- 👥 deleted-U04R23BEW3V, darrell, Nick Ward,
- 👥 Dwight Thomas, Nick Ward, ahsan,
- 👥 Cameron Rentch, Ryan Vaspra, Chris, Andy Rogers, Nicholas McFadden,
- 👥 Ryan Vaspra, Andy Rogers, brian580,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U055HQT39PC,
- 👥 Tony Jones, Luis Cortes, deleted-U055HQT39PC, Nicholas McFadden,
- 👥 Ryan Vaspra, luke, Nicholas McFadden,
- 👥 Ryan Vaspra, luke, Nicholas McFadden, deleted-U06N28XTLE7,
- 👥 Mike Everhart, Cameron Rentch, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04TA486SM6,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, craig, Adrienne Hester, Greg Owen, patsy, David Evans, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, michaelbrunet, deleted-U067A4KAB9U, deleted-U071ST51P18, Ralecia Marks,
- 👥 Cameron Rentch, john, Julie-Margaret Johnson,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Nicholas McFadden,
- 👥 Cameron Rentch, deleted-U06AYDQ4WVA, deleted-U06N28XTLE7,
- 👥 Ryan Vaspra, luke, deleted-U05DY7UGM2L,
- 👥 Cameron Rentch, Andy Rogers, Malissa Phillips,
- 👥 Ryan Vaspra, Brian Hirst, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Nicholas McFadden, michaelbrunet, deleted-U067A4KAB9U, Nick Ward, deleted-U071ST51P18,
- 👥 Mike Everhart, Ryan Vaspra, Tony, Brian Hirst, luke, LaToya Palmer, Adrienne Hester, korbin, brian580,
- 👥 Ryan Vaspra, Mark Maniora, deleted-U05DY7UGM2L, Nicholas McFadden, Lee Zafra, James Scott, Nick Ward,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW, Nicholas McFadden, Nick Ward,
- 👥 Ryan Vaspra, brian580, Malissa Phillips,
- 👥 Cameron Rentch, Tony, Andy Rogers, Nicholas McFadden,
- 👥 Ryan Vaspra, Nicholas McFadden, ahsan,
- 👥 Ryan Vaspra, Tony, deleted-U04GZ79CPNG, Nicholas McFadden, brian580, Nick Ward, deleted-U072JS2NHRQ, Malissa Phillips,
- 👥 Dwight Thomas, Nicholas McFadden, ahsan,
- 👥 Ryan Vaspra, Greg Owen, brian580, Malissa Phillips,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nicholas McFadden, Nick Ward,
- 👥 Dwight Thomas, Nicholas McFadden, Nick Ward, ahsan,
- 👥 Andy Rogers, Greg Owen, Malissa Phillips,
- 👥 Andy Rogers, patsy, Malissa Phillips,
- 👥 Ryan Vaspra, Tony Jones, luke, deleted-U04GZ79CPNG, deleted-U055HQT39PC, Nicholas McFadden, deleted-U06N28XTLE7, deleted-U072JS2NHRQ,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, brian580, deleted-U071ST51P18,
- 👥 deleted-U055HQT39PC, Mark Maniora, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, Mark Maniora, Greg Owen, brian580, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05CTUBCP7E, deleted-U05EFH3S2TA,
- 👥 Ryan Vaspra, Greg Owen, Malissa Phillips,
- 👥 Ryan Vaspra, Mark Maniora, Greg Owen, brian580, Malissa Phillips,
- 👥 Tony Jones, deleted-U04HFGHL4RW, Adrienne Hester,
- 👥 Mike Everhart, Ryan Vaspra, Tony, Brian Hirst, luke, Dwight Thomas, Greg Owen, brian580, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, Mark Maniora, Greg Owen, Malissa Phillips,
- 👥 Cameron Rentch, Chris, Andy Rogers,
- 👥 Ryan Vaspra, Andy Rogers, Greg Owen, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Nicholas McFadden, Nick Ward,
- 👥 Andy Rogers, craig, Greg Owen, Malissa Phillips,
- 👥 Andy Rogers, Greg Owen, brian580, Malissa Phillips,
- 👥 Mark Maniora, Greg Owen, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, deleted-U071ST51P18, Ralecia Marks,
- 👥 LaToya Palmer, Adrienne Hester, Melanie Macias,
- 👥 LaToya Palmer, Adrienne Hester, Mark Maniora, Greg Owen, Lee Zafra, David Evans, Melanie Macias,
- 👥 Adrienne Hester, Joe Santana, Melanie Macias,
- 👥 Mike Everhart, Dwight Thomas, Nicholas McFadden, ahsan,
- 👥 deleted-U055HQT39PC, Dwight Thomas, Nicholas McFadden,
- 👥 Cameron Rentch, Andy Rogers, Greg Owen, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, Ralecia Marks,
- 👥 Ryan Vaspra, Tony, Tony Jones, deleted-U04GZ79CPNG, Mark Maniora, deleted-U05EFH3S2TA, Nick Ward, deleted-U072JS2NHRQ,
- 👥 deleted-U04GZ79CPNG, deleted-U06AYDQ4WVA, deleted-U06N28XTLE7, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, Nicholas McFadden, Nick Ward, Malissa Phillips,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW,
- 👥 deleted-U055HQT39PC, Mark Maniora, Dwight Thomas, Nick Ward, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, Joe Santana,
- 👥 Mike Everhart, LaToya Palmer, Adrienne Hester,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, brian580, Malissa Phillips,
- 👥 Nick Ward, ahsan, Malissa Phillips,
- 👥 deleted-U05EFH3S2TA, Nick Ward, Vilma Farrar,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nick Ward,
- 👥 Cameron Rentch, Mark Hines, Brian Hirst, Mark Maniora,
- 👥 Cameron Rentch, Andy Rogers, Greg Owen, brian580, Malissa Phillips,
- 👥 brian580, deleted-U072JS2NHRQ, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nicholas McFadden, deleted-U067A4KAB9U, Nick Ward, deleted-U071ST51P18,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, Nicholas McFadden, deleted-U067A4KAB9U,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, deleted-U04HFGHL4RW, deleted-U05DY7UGM2L,
- 👥 Cameron Rentch, Caleb Peters, David Temmesfeld,
- 👥 Cameron Rentch, Tony, Andy Rogers, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, Tony, craig, Nick Ward,
- 👥 Cameron Rentch, Andy Rogers, greg, craig, Greg Owen, patsy, Malissa Phillips,
- 👥 Jack Altunyan, Ryan Vaspra, Maximus, john, Caleb Peters,
- 👥 Dwight Thomas, Nicholas McFadden, darrell, ahsan, Malissa Phillips,
- 👥 deleted-U04HFGHL4RW, Greg Owen, Malissa Phillips,
- 👥 Jack Altunyan, Cameron Rentch, Ryan Vaspra, Maximus, Mark Hines, Caleb Peters,
- 👥 deleted-U06C7A8PVLJ, ahsan, Aidan Celeste,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, deleted-U067A4KAB9U, deleted-U071ST51P18, Ralecia Marks,
- 👥 Cameron Rentch, craig, Malissa Phillips,
- 👥 Andy Rogers, brian580, Malissa Phillips,
- 👥 Ryan Vaspra, Mark Maniora, Greg Owen, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, Tony Jones, Andy Rogers, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U056TJH4KUL, Nicholas McFadden,
- 👥 Dwight Thomas, Nicholas McFadden, darrell, Nick Ward, ahsan, Malissa Phillips,
- 👥 deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nicholas McFadden,
- 👥 deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nicholas McFadden,
- 👥 Cameron Rentch, Ryan Vaspra, Tony, Andy Rogers, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, Nicholas McFadden, Nick Ward,
- 👥 Andy Rogers, LaToya Palmer, Adrienne Hester, David Evans, Melanie Macias,
- 👥 LaToya Palmer, Adrienne Hester, David Evans, Melanie Macias,
- 👥 deleted-U04R23BEW3V, Greg Owen, Malissa Phillips,
- 👥 deleted-U04R23BEW3V, deleted-U055HQT39PC, Greg Owen, Malissa Phillips,
- 👥 Andy Rogers, deleted-U04HFGHL4RW, Malissa Phillips,
- 👥 deleted-U04GZ79CPNG, brian580, Malissa Phillips,
- 👥 Cameron Rentch, Mark Maniora, Malissa Phillips,
- 👥 Cameron Rentch, Andy Rogers, Nicholas McFadden, Nick Ward,
- 👥 Andy Rogers, deleted-U04HFGHL4RW, Greg Owen, Malissa Phillips,
- 👥 craig, ahsan, Malissa Phillips,
- 👥 Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U069G4WMMD4,
- 👥 Dwight Thomas, Nicholas McFadden, ahsan, Malissa Phillips,
- 👥 Dwight Thomas, Nicholas McFadden, darrell, Nick Ward, ahsan, Malissa Phillips, Daniel Schussler,
- 👥 Greg Owen, brian580, Malissa Phillips,
- 👥 Andy Rogers, LaToya Palmer, Adrienne Hester, Mark Maniora, Greg Owen, Lee Zafra, David Evans, Melanie Macias,
- 👥 Dwight Thomas, Nicholas McFadden, Nick Ward, ahsan, Daniel Schussler, Dustin Surwill,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U05DY7UGM2L, Nicholas McFadden,
- 👥 Cameron Rentch, Chris, David Temmesfeld, Melanie Macias, Jennifer Durnell,
- 👥 Dwight Thomas, ahsan, Daniel Schussler,
- 👥 Ryan Vaspra, Brian Hirst, deleted-U055HQT39PC, Mark Maniora, Nicholas McFadden, Nick Ward,
- 👥 Nicholas McFadden, darrell, Nick Ward, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, brian580, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA,
- 👥 deleted-U04HFGHL4RW, brian580, Malissa Phillips,
- 👥 Dwight Thomas, Nicholas McFadden, Nick Ward,
- 👥 David Evans, Melanie Macias, Jennifer Durnell,
- 👥 Nicholas McFadden, Nick Ward, Malissa Phillips,
- 👥 ahsan, Daniel Schussler, Dustin Surwill,
- 👥 deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, brian580, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U06N28XTLE7,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05DY7UGM2L, deleted-U05EFH3S2TA, Ralecia Marks,
- 👥 Ryan Vaspra, Melanie Macias, Jennifer Durnell,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, Nicholas McFadden,
- 👥 Cameron Rentch, Ryan Vaspra, Tony, Andy Rogers, Nicholas McFadden,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U05EFH3S2TA, brian580, Malissa Phillips,
- 👥 Greg Owen, deleted-U06N28XTLE7, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, deleted-U04HFGHL4RW, Nicholas McFadden,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, brian580, Malissa Phillips,
- 👥 Nicholas McFadden, Nick Ward, Dustin Surwill,
- 👥 Dwight Thomas, ahsan, Dustin Surwill,
- 👥 Ryan Vaspra, Lee Zafra, brian580,
- 👥 Andy Rogers, LaToya Palmer, Adrienne Hester, Melanie Macias,
- 👥 Cameron Rentch, Ryan Vaspra, Joe Santana, Nicholas McFadden, Nick Ward, ahsan, Dustin Surwill,
- 👥 Cameron Rentch, Tony Jones, deleted-U05EFH3S2TA, brian580, Malissa Phillips,
- 👥 Cameron Rentch, craig, deleted-U04HFGHL4RW, Malissa Phillips,
- 👥 Cameron Rentch, craig, deleted-U05EFH3S2TA, Malissa Phillips,
- 👥 Chris, David Temmesfeld, Melanie Macias, Jennifer Durnell,
- 👥 Ryan Vaspra, deleted-U055HQT39PC, deleted-U05EFH3S2TA, Malissa Phillips,
- 👥 Andy Rogers, Adrienne Hester, David Evans,
- 👥 craig, deleted-U05EFH3S2TA, Malissa Phillips,
- 👥 Cameron Rentch, Joe Santana, Nick Ward,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, Greg Owen, Malissa Phillips,
- 👥 Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U06GD22CLDC,
- 👥 Cameron Rentch, Nicholas McFadden, Malissa Phillips,
- 👥 Andy Rogers, LaToya Palmer, Adrienne Hester, David Evans,
- 👥 ahsan, James Turner, Zekarias Haile,
- 👥 Cameron Rentch, Andy Rogers, Melanie Macias,
- 👥 deleted-U04R23BEW3V, Anthony Soboleski, James Turner,
- 👥 Cameron Rentch, Nicholas McFadden, Dustin Surwill,
- 👥 Nicholas McFadden, ahsan, Malissa Phillips,
- 👥 Dwight Thomas, Nicholas McFadden, Nick Ward, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U04R23BEW3V,
- 👥 Ryan Vaspra, Andy Rogers, Mark Maniora, Greg Owen, Malissa Phillips,
- 👥 deleted-U05CTUBCP7E, Dwight Thomas, deleted-U0679HSE82K,
- 👥 Nicholas McFadden, ahsan, Dustin Surwill,
- 👥 Daniel Schussler, Dustin Surwill, James Turner, Zekarias Haile,
- 👥 Ryan Vaspra, Andy Rogers, Malissa Phillips,
- 👥 Cameron Rentch, Mark Hines, Melanie Macias,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Joe Santana, deleted-U05EFH3S2TA, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, Greg Owen, Malissa Phillips,
- 👥 Ryan Vaspra, Brian Hirst, deleted-U055HQT39PC, Mark Maniora, Nicholas McFadden, deleted-U06GD22CLDC, Nick Ward, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, brian580,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, brian580,
- 👥 deleted-U05DY7UGM2L, Dwight Thomas, Nick Ward,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nick Ward, deleted-U071ST51P18,
- 👥 Brian Hirst, darrell, Nick Ward,
- 👥 Dwight Thomas, Nicholas McFadden, Nick Ward, ahsan, Daniel Schussler, Dustin Surwill, James Turner, Zekarias Haile,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, brian580, Malissa Phillips,
- 👥 Nicholas McFadden, ahsan, Daniel Schussler, Dustin Surwill, James Turner, Zekarias Haile,
- 👥 Mark Maniora, Nick Ward, Malissa Phillips,
- 👥 Dwight Thomas, Nicholas McFadden, Nick Ward, ahsan, Malissa Phillips, Dustin Surwill,
- 👥 Nick Ward, Malissa Phillips, Dustin Surwill,
- 👥 deleted-U05496RCQ9M, deleted-U062D2YJ15Y, James Turner,
- 👥 Cameron Rentch, deleted-U05DY7UGM2L, brian580,
- 👥 craig, brian580, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, Joe Santana, Malissa Phillips,
- 👥 Cameron Rentch, Tony Jones, Joe Santana,
- 👥 Ryan Vaspra, deleted-U05EFH3S2TA, brian580, Malissa Phillips,
- 👥 Mike Everhart, Jack Altunyan, Maximus, Caleb Peters, Dwight Thomas,
- 👥 Nicholas McFadden, Dustin Surwill, James Turner,
- 👥 Dwight Thomas, Malissa Phillips, Dustin Surwill,
- 👥 Cameron Rentch, Ryan Vaspra, Brian Hirst, deleted-U05DY7UGM2L,
- 👥 Dwight Thomas, ahsan, Daniel Schussler, James Turner, Zekarias Haile,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nicholas McFadden, Dustin Surwill,
- 👥 Ryan Vaspra, Nicholas McFadden, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U05EFH3S2TA,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, Joe Santana,
- 👥 Nicholas McFadden, Nick Ward, ahsan, Dustin Surwill,
- 👥 Dwight Thomas, Daniel Schussler, James Turner,
- 👥 Nicholas McFadden, darrell, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U06C7A8PVLJ, deleted-U06N28XTLE7,
- 👥 Cameron Rentch, Ryan Vaspra, Adrienne Hester, deleted-U067A4KAB9U,
- 👥 Cameron Rentch, craig, Dustin Surwill,
- 👥 Cameron Rentch, Tony, craig,
- 👥 Cameron Rentch, craig, deleted-U06N28XTLE7, deleted-U072JS2NHRQ,
- 👥 Cameron Rentch, Ryan Vaspra, Mark Hines, Caleb Peters, Dwight Thomas, Nicholas McFadden,
- 👥 Tony, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U05DY7UGM2L, Nicholas McFadden, James Scott,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, Nicholas McFadden, Melanie Macias,
- 👥 Cameron Rentch, Ryan Vaspra, Nicholas McFadden, Melanie Macias,
- 👥 Tony, deleted-U05EFH3S2TA, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U05DY7UGM2L, Nicholas McFadden, Nick Ward,
- 👥 Ryan Vaspra, deleted-U04HFGHL4RW, Mark Maniora, Greg Owen, Nick Ward, Malissa Phillips, Dustin Surwill,
- 👥 Cameron Rentch, Chris, David Temmesfeld, Dorshan Millhouse,
- 👥 Ryan Vaspra, Brian Hirst, Nicholas McFadden, James Scott, deleted-U06VDQGHZLL, Dustin Surwill,
- 👥 Cameron Rentch, Andy Rogers, Mark Maniora, Greg Owen, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05DY7UGM2L, Nicholas McFadden,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, Nicholas McFadden,
- 👥 Dwight Thomas, Nicholas McFadden, Daniel Schussler, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Joe Santana, Nicholas McFadden, Nick Ward, Dustin Surwill,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U05DY7UGM2L, Nicholas McFadden,
- 👥 Dwight Thomas, Nicholas McFadden, Nick Ward, Dustin Surwill,
- 👥 Cameron Rentch, Mark Hines, Dwight Thomas, Nicholas McFadden,
- 👥 Nicholas McFadden, deleted-U05QUSWUJA2, Malissa Phillips, Dustin Surwill,
- 👥 ahsan, Dustin Surwill, James Turner,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04R23BEW3V, Joe Santana, deleted-U05EFH3S2TA, deleted-U06F9N9PB2A, Ralecia Marks,
- 👥 deleted-U055HQT39PC, Mark Maniora, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Ralecia Marks,
- 👥 Cameron Rentch, Nicholas McFadden, Nick Ward, Dustin Surwill,
- 👥 Mark Maniora, Greg Owen, Melanie Macias,
- 👥 Ryan Vaspra, Mark Maniora, Malissa Phillips,
- 👥 Malissa Phillips, Dustin Surwill, James Turner,
- 👥 deleted-U04R23BEW3V, deleted-U06C7A8PVLJ, Malissa Phillips,
- 👥 Jack Altunyan, Cameron Rentch, Maximus, Caleb Peters, Yan Ashrapov,
- 👥 Cameron Rentch, Ryan Vaspra, Yan Ashrapov,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, Yan Ashrapov,
- 👥 Cameron Rentch, Maximus, Yan Ashrapov,
- 👥 deleted-U05EFH3S2TA, deleted-U06F9N9PB2A, Malissa Phillips,
- 👥 Cameron Rentch, Joe Santana, Ralecia Marks,
- 👥 Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U055HQT39PC, brian580, Malissa Phillips,
- 👥 Ryan Vaspra, Brian Hirst, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Malissa Phillips,
- 👥 Ryan Vaspra, Brian Hirst, deleted-U06GD22CLDC, Malissa Phillips,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW, Malissa Phillips,
- 👥 Ryan Vaspra, deleted-U06GD22CLDC, Malissa Phillips,
- 👥 Nick Ward, Malissa Phillips, James Turner,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U05EFH3S2TA, Nicholas McFadden, Ralecia Marks,
- 👥 deleted-U055HQT39PC, deleted-U06GD22CLDC, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U05DY7UGM2L, brian580, Yan Ashrapov,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW, Greg Owen, Malissa Phillips,
- 👥 deleted-U04GZ79CPNG, deleted-U072JS2NHRQ, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Joe Santana,
- 👥 Ryan Vaspra, Joe Santana, Zekarias Haile,
- 👥 Cameron Rentch, Caleb Peters, Yan Ashrapov,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, brian580, Malissa Phillips,
- 👥 Cameron Rentch, Melanie Macias, Yan Ashrapov,
- 👥 deleted-U04GZ79CPNG, Malissa Phillips, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, deleted-U067A4KAB9U,
- 👥 Cameron Rentch, deleted-U04R23BEW3V, Yan Ashrapov,
- 👥 Cameron Rentch, Chris, David Temmesfeld, Dorshan Millhouse, Yan Ashrapov,
- 👥 Mike Everhart, Cameron Rentch, Joe Santana, Yan Ashrapov,
- 👥 Jack Altunyan, Cameron Rentch, Yan Ashrapov,
- 👥 craig, Malissa Phillips, Dustin Surwill,
- 👥 Nicholas McFadden, Nick Ward, James Turner,
- 👥 Ryan Vaspra, Mark Hines, Zekarias Haile,
- 👥 Dwight Thomas, ahsan, Aidan Celeste, Daniel Schussler, Zekarias Haile,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Joe Santana, Nick Ward,
- 👥 Dwight Thomas, ahsan, Daniel Schussler, Dustin Surwill, James Turner, Zekarias Haile,
- 👥 Ryan Vaspra, James Scott, Anthony Soboleski,
- 👥 Marc Barmazel, Cameron Rentch, Ryan Vaspra,
- 👥 Ryan Vaspra, Brian Hirst, brian580, James Turner,
- 👥 Cameron Rentch, Andy Rogers, David Evans,
- 👥 Cameron Rentch, Fabian De Simone, brian580,
- 👥 Ryan Vaspra, Chris, James Scott,
- 👥 Ryan Vaspra, James Scott, Nsay Y,
- 👥 Ryan Vaspra, Joe Santana, deleted-U06C7A8PVLJ, Dustin Surwill, James Turner, Zekarias Haile,
- 👥 Ryan Vaspra, Joe Santana, deleted-U06C7A8PVLJ, James Turner, Zekarias Haile,
- 👥 deleted-U055HQT39PC, deleted-U06GD22CLDC, James Turner,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04TA486SM6, Nick Ward,
- 👥 Mike Everhart, Cameron Rentch, Mark Hines, Joe Santana, deleted-U07JFNH9C7P,
- 👥 Maximus, deleted-U05F548NU5V, deleted-U05G9BHC4GY, Yan Ashrapov,
- 👥 Nicholas McFadden, deleted-U06C7A8PVLJ, deleted-U06GD22CLDC, Nick Ward, James Turner,
- 👥 Jack Altunyan, deleted-U05F548NU5V, deleted-U05G9BHC4GY, Yan Ashrapov,
- 👥 Nicholas McFadden, Nick Ward, Dustin Surwill, James Turner,
- 👥 Caleb Peters, deleted-U05F548NU5V, deleted-U05G9BHC4GY, Yan Ashrapov,
- 👥 deleted-U04GZ79CPNG, deleted-U06C7A8PVLJ, James Turner,
- 👥 Cameron Rentch, Chris, David Temmesfeld, Dorshan Millhouse, deleted-U05F548NU5V, deleted-U05G9BHC4GY, Yan Ashrapov, deleted-U084U38R8DN,
- 👥 Ryan Vaspra, Nicholas McFadden, Nick Ward, Dustin Surwill,
- 👥 Ryan Vaspra, deleted-U06C7A8PVLJ, Nick Ward, James Turner, Zekarias Haile,
- 👥 deleted-U04HFGHL4RW, Nicholas McFadden, deleted-U06VDQGHZLL, Malissa Phillips, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04R23BEW3V, Nick Ward,
- 👥 deleted-U04HFGHL4RW, deleted-U055HQT39PC, Malissa Phillips,
- 👥 Ryan Vaspra, deleted-U06C7A8PVLJ, deleted-U06N28XTLE7,
- 👥 Cameron Rentch, Melanie Macias, Jennifer Durnell,
- 👥 Ryan Vaspra, deleted-U055HQT39PC, Mark Maniora, Malissa Phillips,
- 👥 Ryan Vaspra, Nicholas McFadden, Dustin Surwill, James Turner,
- 👥 Jack Altunyan, Maximus, Caleb Peters, deleted-U05F548NU5V, Yan Ashrapov,
- 👥 LaToya Palmer, Adrienne Hester, Mark Maniora, Greg Owen, Lee Zafra, David Evans, Malissa Phillips, Melanie Macias, Jennifer Durnell,
- 👥 Anthony Soboleski, Dustin Surwill, James Turner,
- 👥 Cameron Rentch, Mark Hines, Joe Santana, deleted-U07JFNH9C7P,
- 👥 Mark Maniora, Greg Owen, Malissa Phillips, Melanie Macias,
- 👥 Mike Everhart, Ryan Vaspra, Mark Hines, Lee Zafra, Yan Ashrapov,
- 👥 Joe Santana, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, Joe Santana, Nicholas McFadden, deleted-U06C7A8PVLJ, Nick Ward, Dustin Surwill,
- 👥 Cameron Rentch, Joe Santana, deleted-U07JFNH9C7P,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW, Joe Santana, deleted-U07JFNH9C7P,
- 👥 Jack Altunyan, Cameron Rentch, Ryan Vaspra, Maximus, Caleb Peters,
- 👥 deleted-U04HFGHL4RW, Nick Ward, Malissa Phillips, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, Joe Santana, Nicholas McFadden, deleted-U06C7A8PVLJ, Nick Ward, Aidan Celeste, Dustin Surwill,
- 👥 Dwight Thomas, Nick Ward, ahsan, Malissa Phillips, Daniel Schussler, Dustin Surwill, James Turner, Zekarias Haile,
- 👥 Dwight Thomas, ahsan, Daniel Schussler, Zekarias Haile,
- 👥 Cameron Rentch, Melanie Macias, Jennifer Durnell, Yan Ashrapov,
- 👥 Cameron Rentch, Ryan Vaspra, Joe Santana, darrell, James Turner,
- 👥 deleted-U04GZ79CPNG, darrell, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U05DY7UGM2L, Melanie Macias,
- 👥 Ryan Vaspra, Mark Hines, Chris, LaToya Palmer, Adrienne Hester, brian580, Melanie Macias,
- 👥 deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Nicholas McFadden, deleted-U06GD22CLDC, deleted-U06VDQGHZLL, Dustin Surwill, James Turner,
- 👥 Ryan Vaspra, deleted-U06C7A8PVLJ, James Turner,
- 👥 Cameron Rentch, Maximus, Chris, David Temmesfeld, Dorshan Millhouse, Yan Ashrapov,
- 👥 craig, Greg Owen, Malissa Phillips,
- 👥 Ryan Vaspra, Brian Hirst, Nicholas McFadden, deleted-U06C7A8PVLJ, Nick Ward, James Turner, Zekarias Haile,
- 👥 Nicholas McFadden, deleted-U07EH86AAN9, Dustin Surwill,
- 👥 Nicholas McFadden, ahsan, Malissa Phillips, Dustin Surwill,
- 👥 Ryan Vaspra, deleted-U06C7A8PVLJ, Zekarias Haile,
- 👥 Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U06C7A8PVLJ, deleted-U06GD22CLDC, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, Malissa Phillips,
- 👥 Ryan Vaspra, Maximus, Dustin Surwill,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, Nicholas McFadden, Yan Ashrapov,
- 👥 deleted-U06F9N9PB2A, Malissa Phillips, Dustin Surwill,
- 👥 LaToya Palmer, deleted-U04HFGHL4RW, Adrienne Hester,
- 👥 Nicholas McFadden, Malissa Phillips, deleted-U07EH86AAN9, Dustin Surwill,
- 👥 deleted-U06C7A8PVLJ, Nick Ward, James Turner,
- 👥 ahsan, Malissa Phillips, Dustin Surwill,
- 👥 Cameron Rentch, Caleb Peters, deleted-U04R23BEW3V, Yan Ashrapov,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, deleted-U06C7A8PVLJ,
- 👥 deleted-U055HQT39PC, Malissa Phillips, Dustin Surwill,
- 👥 Cameron Rentch, Rose Fleming, brian580, Yan Ashrapov,
- 👥 deleted-U05EFH3S2TA, Nicholas McFadden, Nick Ward, ahsan, Malissa Phillips, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, Nicholas McFadden, deleted-U07JFNH9C7P,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, Joe Santana, deleted-U05EFH3S2TA, Nick Ward,
- 👥 Cameron Rentch, Tony, Andy Rogers, Joe Santana,
- 👥 deleted-U04GZ79CPNG, deleted-U06F9N9PB2A, ahsan, Malissa Phillips, Dustin Surwill,
- 👥 Nicholas McFadden, Nick Ward, ahsan, Malissa Phillips, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Joe Santana, deleted-U05EFH3S2TA, Nick Ward,
- 👥 Dorshan Millhouse, Melanie Macias, Jennifer Durnell,
- 👥 deleted-U06C7A8PVLJ, Nick Ward, James Turner,
- 👥 Ryan Vaspra, deleted-U06C7A8PVLJ, James Turner, Zekarias Haile,
- 👥 Ryan Vaspra, Maximus, brian580,
- 👥 deleted-U04GZ79CPNG, Nick Ward, Dustin Surwill,
- 👥 Cameron Rentch, Ryan Vaspra, Nicholas McFadden, Nick Ward, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U04R23BEW3V,
- 👥 Cameron Rentch, Mark Hines, Joe Santana,
- 👥 Joe Santana, Nick Ward, Dustin Surwill,
- 👥 Rose Fleming, brian580, Malissa Phillips,
- 👥 Cameron Rentch, Mark Hines, deleted-U04HFGHL4RW, Joe Santana, deleted-U07JFNH9C7P,
- 👥 deleted-U055HQT39PC, Nicholas McFadden, Malissa Phillips,
- 👥 Ryan Vaspra, Joe Santana, James Scott,
- 👥 Cameron Rentch, Ryan Vaspra, Rose Fleming, brian580,
- 👥 Mike Everhart, deleted-U05F548NU5V, Yan Ashrapov,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, Dustin Surwill,
- 👥 Cameron Rentch, Ryan Vaspra, Mark Maniora, Malissa Phillips,
- 👥 Jack Altunyan, Maximus, Caleb Peters, Dwight Thomas, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U072B7ZV4SH, deleted-U072JS2NHRQ,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05DY7UGM2L, Nick Ward, deleted-U07JFNH9C7P,
- 👥 deleted-U05496RCQ9M, Nicholas McFadden, deleted-U06C7A8PVLJ, deleted-U06VDQGHZLL, Malissa Phillips, Anthony Soboleski, James Turner,
- 👥 deleted-U04HFGHL4RW, deleted-U055HQT39PC, Nicholas McFadden, Greg Owen, Nick Ward, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U072JS2NHRQ,
- 👥 Mike Everhart, Cameron Rentch, deleted-U05F548NU5V, deleted-U05G9BHC4GY, Nicholas McFadden, Yan Ashrapov,
- 👥 Cameron Rentch, Mark Hines, Joe Santana, Yan Ashrapov,
- 👥 Cameron Rentch, Ryan Vaspra, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, Nicholas McFadden,
- 👥 Cameron Rentch, Mark Hines, Tony, Brian Hirst, deleted-U055HQT39PC, Mark Maniora, Nicholas McFadden,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, Mark Maniora, deleted-U062D2YJ15Y, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, Lee Zafra, Yan Ashrapov,
- 👥 Mark Maniora, Dwight Thomas, Malissa Phillips,
- 👥 Cameron Rentch, Adrienne Hester, Joe Santana,
- 👥 Cameron Rentch, Rose Fleming, Yan Ashrapov,
- 👥 Mike Everhart, Mark Hines, Dwight Thomas,
- 👥 Ryan Vaspra, deleted-U06C7A8PVLJ, Malissa Phillips,
- 👥 Marc Barmazel, Cameron Rentch, Malissa Phillips,
- 👥 Mike Everhart, Cameron Rentch, Nicholas McFadden, Yan Ashrapov,
- 👥 Nicholas McFadden, deleted-U06C7A8PVLJ, James Turner,
- 👥 Rose Fleming, Greg Owen, Malissa Phillips,
- 👥 Ryan Vaspra, James Scott, James Turner,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U06C7A8PVLJ, Malissa Phillips,
- 👥 Kelly C. Richardson, EdS, Adrienne Hester, Lee Zafra,
- 👥 Cameron Rentch, Ryan Vaspra, Joe Santana, James Scott,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U055HQT39PC,
- 👥 Jack Altunyan, Cameron Rentch, Maximus, Mark Hines, Brian Hirst, Caleb Peters, Mark Maniora,
- 👥 Andy Rogers, craig, Greg Owen,
- 👥 Joe Santana, deleted-U05QUSWUJA2, deleted-U06VDQGHZLL, Dustin Surwill,
- 👥 Greg Owen, deleted-U06C7A8PVLJ, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nicholas McFadden, deleted-U067A4KAB9U, deleted-U071ST51P18,
- 👥 deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, darrell, Nick Ward,
- 👥 Cameron Rentch, deleted-U05DY7UGM2L, darrell,
- 👥 Cameron Rentch, Ryan Vaspra, Joe Santana, Nicholas McFadden,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Malissa Phillips,
- 👥 Cameron Rentch, Nicholas McFadden, darrell, Nick Ward, Dustin Surwill,
- 👥 Cameron Rentch, Mark Hines, deleted-U05DY7UGM2L, brian580,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, deleted-U06C7A8PVLJ, deleted-U06CVB2MHRN, deleted-U06VDQGHZLL, Daniel Schussler, Dustin Surwill,
- 👥 Mark Maniora, Nicholas McFadden, Nick Ward,
- 👥 Dwight Thomas, Nicholas McFadden, Nick Ward, Malissa Phillips, Dustin Surwill,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, deleted-U06F9N9PB2A, Nick Ward, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nicholas McFadden,
- 👥 Cameron Rentch, Ryan Vaspra, Rose Fleming, Nsay Y, brian580,
- 👥 Cameron Rentch, Andy Rogers, Mark Maniora, Malissa Phillips,
- 👥 deleted-U04R23BEW3V, Daniel Schussler, Dustin Surwill,
- 👥 deleted-U04HFGHL4RW, deleted-U055HQT39PC, Nicholas McFadden, deleted-U062D2YJ15Y, deleted-U06GD22CLDC, James Turner,
- 👥 Maximus, Mark Hines, Brian Hirst, Dwight Thomas, Nicholas McFadden, Nick Ward, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, Nick Ward,
- 👥 Cameron Rentch, Rose Fleming, brian580, Malissa Phillips,
- 👥 deleted-U04TA486SM6, Rose Fleming, brian580, Malissa Phillips,
- 👥 Cameron Rentch, Andy Rogers, Yan Ashrapov,
- 👥 Cameron Rentch, Andy Rogers, deleted-U055HQT39PC, Mark Maniora, Malissa Phillips,
- 👥 deleted-U02E2EXSJJC, LaToya Palmer, deleted-U042MMWVCH2, Adrienne Hester, deleted-U059JKB35RU,
- 👥 Nicholas McFadden, deleted-U05QUSWUJA2, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, Mark Maniora, deleted-U06C7A8PVLJ, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, Nsay Y, brian580,
- 👥 Ryan Vaspra, Joe Santana, James Turner,
- 👥 Ryan Vaspra, Brian Hirst, Mark Maniora, Nicholas McFadden, Malissa Phillips,
- 👥 Ryan Vaspra, Caleb Peters, deleted-U06C7A8PVLJ,
- 👥 Ryan Vaspra, Rose Fleming, Lee Zafra, Nsay Y, brian580,
- 👥 LaToya Palmer, deleted-U04FQ65M8MC, Adrienne Hester,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U056TJH4KUL, deleted-U05DY7UGM2L, Nicholas McFadden,
- 👥 deleted-U04TA486SM6, deleted-U05EFH3S2TA, Rose Fleming, brian580, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U072JS2NHRQ,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05DY7UGM2L, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, Ryan Vaspra, Zekarias Haile,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U06C7A8PVLJ, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U04R23BEW3V, deleted-U06C7A8PVLJ,
- 👥 Cameron Rentch, Rose Fleming, brian580, Altonese Neely, Michelle Cowan,
- 👥 Cameron Rentch, deleted-U05DY7UGM2L, Nick Ward,
- 👥 Cameron Rentch, deleted-U055HQT39PC, Malissa Phillips,
- 👥 Ryan Vaspra, Tony, deleted-U04HFGHL4RW,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04R23BEW3V, deleted-U05EFH3S2TA,
- 👥 Cameron Rentch, Ryan Vaspra, Brian Hirst, deleted-U04GZ79CPNG,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, deleted-U06F9N9PB2A, Malissa Phillips, Dustin Surwill, deleted-U07SBM5MB32,
- 👥 deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, Nicholas McFadden,
- 👥 Cameron Rentch, Mark Hines, LaToya Palmer,
- 👥 Nicholas McFadden, James Scott, James Turner,
- 👥 Nicholas McFadden, deleted-U06F9N9PB2A, Malissa Phillips,
- 👥 Ryan Vaspra, James Scott, Zekarias Haile,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Mark Maniora, Greg Owen, Malissa Phillips,
- 👥 deleted-U06CVB2MHRN, deleted-U072JS2NHRQ, ahsan,
- 👥 darrell, Daniel Schussler, Dustin Surwill,
- 👥 Ryan Vaspra, Rose Fleming, Malissa Phillips,
- 👥 Chris, David Temmesfeld, Dorshan Millhouse, Melanie Macias, Jennifer Durnell,
- 👥 deleted-U04TA486SM6, deleted-U055HQT39PC, Malissa Phillips,
- 👥 Nicholas McFadden, Daniel Schussler, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, deleted-U07JFNH9C7P,
- 👥 Cameron Rentch, Rose Fleming, Malissa Phillips,
- 👥 Brian Hirst, Rose Fleming, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, deleted-U06F9N9PB2A,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Joe Santana, deleted-U06VDQGHZLL, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04R23BEW3V, deleted-U055HQT39PC,
- 👥 Mark Maniora, deleted-U06GD22CLDC, Nick Ward, James Turner,
- 👥 Cameron Rentch, Ryan Vaspra, Rose Fleming, Lee Zafra, Nsay Y, Malissa Phillips,
- 👥 Mike Everhart, Cameron Rentch, Caleb Peters, Mark Maniora, Yan Ashrapov,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Joe Santana, deleted-U06VDQGHZLL, Malissa Phillips,
- 👥 Mike Everhart, Jack Altunyan, Cameron Rentch, Nicholas McFadden, Yan Ashrapov,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, Rose Fleming, Nsay Y, Malissa Phillips,
- 👥 Ryan Vaspra, deleted-U05DY7UGM2L, Rose Fleming,
- 👥 Ryan Vaspra, Tony, Nick Ward,
- 👥 Mike Everhart, Cameron Rentch, Caleb Peters, Yan Ashrapov,
- 👥 deleted-U06GD22CLDC, Dustin Surwill, James Turner,
- 👥 Cameron Rentch, Andy Rogers, deleted-U05EFH3S2TA, deleted-U06F9N9PB2A,
- 👥 Mark Maniora, Greg Owen, Lee Zafra, David Evans, Malissa Phillips, Melanie Macias,
- 👥 deleted-U04GZ79CPNG, Malissa Phillips, deleted-U07SBM5MB32,
- 👥 Greg Owen, ahsan, Malissa Phillips, Dustin Surwill,
- 👥 deleted-U04GG7BCZ5M, deleted-U04R23BEW3V, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, Kelly C. Richardson, EdS, Andy Rogers, LaToya Palmer, Lee Zafra,
- 👥 deleted-U04GZ79CPNG, Greg Owen, deleted-U06C7A8PVLJ, Malissa Phillips,
- 👥 Daniel Schussler, Dustin Surwill, Zekarias Haile,
- 👥 Dwight Thomas, Nicholas McFadden, ahsan, Daniel Schussler, Dustin Surwill, Zekarias Haile,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, deleted-U067A4KAB9U, deleted-U071ST51P18, deleted-U07JFNH9C7P,
- 👥 deleted-U06GD22CLDC, Nick Ward, Anthony Soboleski, James Turner,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, deleted-U06F9N9PB2A, Ralecia Marks,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, Ralecia Marks, deleted-U07SBM5MB32,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Joe Santana, Nick Ward,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, Greg Owen,
- 👥 deleted-U06C7A8PVLJ, deleted-U072JS2NHRQ, Dustin Surwill,
- 👥 Cameron Rentch, Ralecia Marks, deleted-U07JFNH9C7P,
- 👥 Andy Rogers, deleted-U05496RCQ9M, deleted-U055HQT39PC, Mark Maniora, Greg Owen, Lee Zafra, David Evans, Malissa Phillips,
- 👥 Ryan Vaspra, Joe Santana, Nick Ward,
- 👥 Joe Santana, Nicholas McFadden, darrell,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, Joe Santana, Nicholas McFadden, darrell, Nick Ward,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, Joe Santana, Nick Ward,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04R23BEW3V, Yan Ashrapov,
- 👥 Ryan Vaspra, Joe Santana, Nicholas McFadden, Nick Ward, Dustin Surwill,
- 👥 Cameron Rentch, Nick Ward, James Turner,
- 👥 Cameron Rentch, Ryan Vaspra, James Turner,
- 👥 deleted-U06C7A8PVLJ, Aidan Celeste, James Turner, Zekarias Haile,
- 👥 Andy Rogers, Melanie Macias, Jennifer Durnell,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, deleted-U062D2YJ15Y, ahsan,
- 👥 Greg Owen, Melanie Macias, Jennifer Durnell,
- 👥 Kelly C. Richardson, EdS, deleted-U02E2EXSJJC, deleted-U042MMWVCH2, Adrienne Hester, deleted-U059JKB35RU, Lee Zafra,
- 👥 deleted-U055HQT39PC, Nicholas McFadden, Nick Ward, James Turner,
- 👥 Joe Santana, Dwight Thomas, Nicholas McFadden, ahsan, Daniel Schussler, Dustin Surwill, James Turner, Zekarias Haile,
- 👥 Cameron Rentch, Joe Santana, deleted-U05DY7UGM2L,
- 👥 Cameron Rentch, Andy Rogers, deleted-U05EFH3S2TA, Nick Ward,
- 👥 LaToya Palmer, Melanie Macias, Jennifer Durnell,
- 👥 deleted-U04HFGHL4RW, Rose Fleming, Malissa Phillips,
- 👥 deleted-U04GZ79CPNG, darrell, Malissa Phillips,
- 👥 deleted-U05496RCQ9M, deleted-U062D2YJ15Y, Dustin Surwill,
- 👥 Mike Everhart, Cameron Rentch, Mark Hines, deleted-U04HFGHL4RW, Joe Santana,
- 👥 Cameron Rentch, Joe Santana, deleted-U05DY7UGM2L, Melanie Macias,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, Nicholas McFadden, Nick Ward,
- 👥 Ryan Vaspra, Nicholas McFadden, deleted-U06C7A8PVLJ, James Turner, Zekarias Haile,
- 👥 Cameron Rentch, deleted-U05DY7UGM2L, deleted-U05EFH3S2TA, Ralecia Marks,
- 👥 Joe Santana, Rose Fleming, Malissa Phillips,
- 👥 Ryan Vaspra, Brian Hirst, Rose Fleming,
- 👥 Dwight Thomas, Nicholas McFadden, Dustin Surwill,
- 👥 Mike Everhart, Cameron Rentch, Ryan Vaspra, Mark Hines, Joe Santana,
- 👥 Jack Altunyan, Ryan Vaspra, Maximus, john, Brian Hirst, Caleb Peters, Nicholas McFadden, Zekarias Haile,
- 👥 Nicholas McFadden, darrell, Malissa Phillips, Dustin Surwill,
- 👥 Dwight Thomas, deleted-U06F9N9PB2A, ahsan, Malissa Phillips, Daniel Schussler, Dustin Surwill, Zekarias Haile,
- 👥 Ryan Vaspra, Joe Santana, Nicholas McFadden, Dustin Surwill,
- 👥 Ryan Vaspra, Brian Hirst, Nicholas McFadden, James Scott, deleted-U06C7A8PVLJ, James Turner, Zekarias Haile,
- 👥 Cameron Rentch, Ryan Vaspra, Nicholas McFadden, Yan Ashrapov,
- 👥 Cameron Rentch, Ryan Vaspra, Mark Maniora, Yan Ashrapov,
- 👥 Ryan Vaspra, deleted-U06C7A8PVLJ, Nick Ward, James Turner,
- 👥 Ryan Vaspra, Nicholas McFadden, Dustin Surwill,
- 👥 Jack Altunyan, Cameron Rentch, Ryan Vaspra, Maximus, john, Caleb Peters,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, Nick Ward, James Turner,
- 👥 Ryan Vaspra, Andy Rogers, Nicholas McFadden, Daniel Schussler,
- 👥 Cameron Rentch, deleted-U05G9BGQFBJ, deleted-U05G9BHC4GY, Yan Ashrapov,
- 👥 deleted-U04GG7BCZ5M, deleted-U055HQT39PC, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U05DY7UGM2L, Nicholas McFadden, Nick Ward,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, Ralecia Marks,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, deleted-U06F9N9PB2A, Ralecia Marks,
- 👥 deleted-U05F548NU5V, deleted-U05G9BHC4GY, Yan Ashrapov,
- 👥 deleted-U06GD22CLDC, Nick Ward, James Turner,
- 👥 Cameron Rentch, Mark Maniora, Dwight Thomas, Dustin Surwill, Yan Ashrapov,
- 👥 Ryan Vaspra, Nicholas McFadden, Zekarias Haile,
- 👥 Cameron Rentch, Andy Rogers, LaToya Palmer, Adrienne Hester, David Evans,
- 👥 Ryan Vaspra, deleted-U05DY7UGM2L, Nicholas McFadden,
- 👥 Ryan Vaspra, Lee Zafra, Malissa Phillips,
- 👥 Cameron Rentch, Tony Jones, deleted-U05DY7UGM2L, Melanie Macias, Jennifer Durnell,
- 👥 Cameron Rentch, Ryan Vaspra, Rose Fleming, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, Rose Fleming,
- 👥 deleted-U05496RCQ9M, deleted-U062D2YJ15Y, ahsan,
- 👥 deleted-U06C7A8PVLJ, James Turner, Zekarias Haile,
- 👥 Jack Altunyan, Maximus, Brian Hirst, Caleb Peters,
- 👥 Nicholas McFadden, James Turner, Zekarias Haile,
- 👥 deleted-U04HFGHL4RW, Nicholas McFadden, Malissa Phillips,
- 👥 Ryan Vaspra, Nick Ward, James Turner,
- 👥 Andy Rogers, David Evans, Melanie Macias,
- 👥 Cameron Rentch, David Evans, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, Nicholas McFadden, darrell, Nick Ward, Anthony Soboleski,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, Malissa Phillips, Aidan Celeste, James Turner, Zekarias Haile,
- 👥 Cameron Rentch, Mark Hines, Mark Maniora, Malissa Phillips,
- 👥 deleted-U04GG7BCZ5M, deleted-U04HFGHL4RW, Malissa Phillips,
- 👥 Dustin Surwill, James Turner, deleted-U08E306T7SM,
- 👥 Nicholas McFadden, Malissa Phillips, Daniel Schussler,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U08LK2U7YBW,
- 👥 Nicholas McFadden, Dustin Surwill, Zekarias Haile,
- 👥 Ryan Vaspra, Malissa Phillips, Zekarias Haile,
- 👥 Cameron Rentch, Nicholas McFadden, darrell, Nick Ward,
- 👥 Cameron Rentch, Andy Rogers, Rose Fleming,
- 👥 deleted-U04GG7BCZ5M, deleted-U04GZ79CPNG, Dustin Surwill,
- 👥 Adrienne Hester, Melanie Macias, Jennifer Durnell,
- 👥 Cameron Rentch, Rose Fleming, Nicholas McFadden,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U05EFH3S2TA, Nicholas McFadden, deleted-U06C7A8PVLJ, Malissa Phillips,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Mark Maniora, Greg Owen, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Mark Maniora, Malissa Phillips, Zekarias Haile,
- 👥 Mark Maniora, Dwight Thomas, Nicholas McFadden,
- 👥 deleted-U062D2YJ15Y, Nick Ward, Dustin Surwill,
- 👥 Nicholas McFadden, darrell, Nick Ward, Daniel Schussler,
- 👥 Cameron Rentch, deleted-U05G9BGQFBJ, deleted-U05G9BHC4GY,
- 👥 Nicholas McFadden, deleted-U0679HSAMSB, Zekarias Haile, deleted-U07PQ4H089G,
- 👥 Joe Santana, Nicholas McFadden, deleted-U06VDQGHZLL,
- 👥 Mike Everhart, Ryan Vaspra, Mark Hines,
- 👥 deleted-U055HQT39PC, deleted-U06VDQGHZLL, Dustin Surwill,
- 👥 Ryan Vaspra, Joe Santana, Nicholas McFadden,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, deleted-U062D2YJ15Y, Dustin Surwill,
- 👥 Melanie Macias, Jennifer Durnell, Yan Ashrapov,
- 👥 Nicholas McFadden, darrell, Daniel Schussler, Dustin Surwill,
- 👥 deleted-U04HFGHL4RW, deleted-U055HQT39PC, Greg Owen, Malissa Phillips,
- 👥 deleted-U04GZ79CPNG, deleted-U04R23BEW3V, James Turner,
- 👥 Nicholas McFadden, deleted-U0679HSAMSB, Dustin Surwill, Zekarias Haile, deleted-U07PQ4H089G,
- 👥 Nicholas McFadden, ahsan, Dustin Surwill, Edward Weber,
- 👥 Ryan Vaspra, Rose Fleming, Nicholas McFadden, Zekarias Haile,
- 👥 Ryan Vaspra, Brian Hirst, deleted-U04GZ79CPNG, Mark Maniora, Malissa Phillips,
- 👥 Joe Santana, Nicholas McFadden, Daniel Schussler,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, Malissa Phillips, Dustin Surwill,
- 👥 deleted-U04GZ79CPNG, darrell, Malissa Phillips, Daniel Schussler,
- 👥 deleted-U04GZ79CPNG, Daniel Schussler, Dustin Surwill,
- 👥 deleted-U04GZ79CPNG, Joe Santana, deleted-U08E306T7SM,
- 👥 Dwight Thomas, Dustin Surwill, Zekarias Haile,
- 👥 Jack Altunyan, Cameron Rentch, Ryan Vaspra, Maximus, Caleb Peters, Rose Fleming,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U05EFH3S2TA, deleted-U06F9N9PB2A, Ralecia Marks,
- 👥 deleted-U04GZ79CPNG, Mark Maniora, Malissa Phillips,
- 👥 Ryan Vaspra, Lee Zafra, Melanie Macias,
- 👥 Luis Cortes, deleted-U055HQT39PC, Malissa Phillips,
- 👥 Mike Everhart, Dwight Thomas, Daniel Schussler,
- 👥 Cameron Rentch, Mark Maniora, Joe Santana, Nicholas McFadden,
- 👥 Cameron Rentch, Joe Santana, Nicholas McFadden, CC Kitanovski,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Joe Santana, deleted-U05DY7UGM2L,
- 👥 deleted-U06C7A8PVLJ, Dustin Surwill, Jehoshua Josue, Richard Schnitzler,
- 👥 deleted-U055HQT39PC, deleted-U062D2YJ15Y, James Turner,
- 👥 Ryan Vaspra, Joe Santana, Nick Ward, James Turner,
- 👥 Mike Everhart, Cameron Rentch, Mark Maniora, Joe Santana,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Mark Maniora, Malissa Phillips,
- 👥 Mark Hines, Mark Maniora, Malissa Phillips,
- 👥 Ryan Vaspra, Andy Rogers, Rose Fleming,
- 👥 Ryan Vaspra, Brian Hirst, Nicholas McFadden, Zekarias Haile,
- 👥 Cameron Rentch, Andy Rogers, deleted-U05DY7UGM2L, Malissa Phillips,
- 👥 Marc Barmazel, Cameron Rentch, Ryan Vaspra, Andy Rogers, Joe Santana, Greg Owen, Malissa Phillips,
- 👥 Ryan Vaspra, Nick Ward, Dustin Surwill, James Turner,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U06C7A8PVLJ, Zekarias Haile, deleted-U08LK2U7YBW,
- 👥 Cameron Rentch, Nicholas McFadden, deleted-U06C7A8PVLJ,
- 👥 Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U055HQT39PC, Mark Maniora, Nicholas McFadden, Greg Owen, deleted-U06C7A8PVLJ, Malissa Phillips, Zekarias Haile,
- 👥 Ryan Vaspra, Nicholas McFadden, Nick Ward, James Turner, Zekarias Haile,
- 👥 Mark Maniora, Nicholas McFadden, Greg Owen, Malissa Phillips,
- 👥 Daniel Schussler, Dustin Surwill, Richard Schnitzler,
- 👥 Tony, Andy Rogers, Malissa Phillips,
- 👥 Ryan Vaspra, deleted-U06C7A8PVLJ, Malissa Phillips, Zekarias Haile,
- 👥 deleted-U04GG7BCZ5M, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Malissa Phillips,
- 👥 Nick Ward, Daniel Schussler, Dustin Surwill,
- 👥 Joe Santana, Nick Ward, James Turner,
- 👥 Ryan Vaspra, deleted-U04GZ79CPNG, Nicholas McFadden, Dustin Surwill, James Turner, Zekarias Haile,
- 👥 Cameron Rentch, Fabian De Simone, Yan Ashrapov,
- 👥 Ryan Vaspra, Nicholas McFadden, deleted-U06C7A8PVLJ, Zekarias Haile,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U08LK2U7YBW,
- 👥 Ryan Vaspra, Brian Hirst, Joe Santana, Nicholas McFadden, deleted-U06C7A8PVLJ, Nick Ward, Dustin Surwill, James Turner, Zekarias Haile,
- 👥 Ryan Vaspra, Rose Fleming, deleted-U06C7A8PVLJ, Malissa Phillips, Zekarias Haile,
- 👥 Cameron Rentch, Mark Hines, Mark Maniora, Greg Owen,
- 👥 deleted-U6Z58C197, James Turner, deleted-U08T4FKSC04,
- 👥 Cameron Rentch, Ryan Vaspra, Nicholas McFadden, Zekarias Haile,
- 👥 Nicholas McFadden, deleted-U06C7A8PVLJ, Daniel Schussler, Richard Schnitzler,
- 👥 Jack Altunyan, Cameron Rentch, Ryan Vaspra, Maximus, Caleb Peters, Mark Maniora, Joe Santana, Nicholas McFadden, Yan Ashrapov,
- 👥 Nick Ward, Dustin Surwill, James Turner,
- 👥 Dwight Thomas, Nicholas McFadden, deleted-U06C7A8PVLJ, Daniel Schussler, Zekarias Haile, Jehoshua Josue, Richard Schnitzler,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, Nick Ward, Dustin Surwill, James Turner,
- 👥 Cameron Rentch, Joe Santana, deleted-U05F548NU5V, deleted-U05G9BGQFBJ, deleted-U05G9BHC4GY, Nicholas McFadden, Yan Ashrapov,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04R23BEW3V, Nicholas McFadden, deleted-U06C7A8PVLJ, Richard Schnitzler,
- 👥 Mike Everhart, Jack Altunyan, Cameron Rentch, Ryan Vaspra, Maximus, Caleb Peters, Joe Santana, Nicholas McFadden, Yan Ashrapov,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04R23BEW3V, Malissa Phillips,
- 👥 LaToya Palmer, deleted-U05CTUBCP7E, deleted-U069G4WMMD4,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, Rose Fleming,
- 👥 Ryan Vaspra, Joe Santana, Nicholas McFadden, James Scott,
- 👥 deleted-U06CVB2MHRN, James Turner, deleted-U08FJ290LUX,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04R23BEW3V, deleted-U08LK2U7YBW,
- 👥 Cameron Rentch, Ryan Vaspra, Joe Santana, deleted-U05DY7UGM2L, Nicholas McFadden,
- 👥 deleted-U04GZ79CPNG, deleted-U055HQT39PC, Nicholas McFadden,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW, deleted-U05DY7UGM2L, deleted-U05EFH3S2TA,
- 👥 deleted-U05EFH3S2TA, Nicholas McFadden, Malissa Phillips,
- 👥 deleted-U04GZ79CPNG, Joe Santana, deleted-U05EFH3S2TA, Nicholas McFadden, Nick Ward,
- 👥 Dustin Surwill, Chris Krecicki, Tyson Green,
- 👥 Cameron Rentch, Ryan Vaspra, Joe Santana, Nick Ward,
- 👥 Ryan Vaspra, Brian Hirst, Zekarias Haile,
- 👥 Nicholas McFadden, Dustin Surwill, Chris Krecicki, Tyson Green,
- 👥 Joe Santana, deleted-U05QUSWUJA2, Nick Ward, Dustin Surwill,
- 👥 Mike Everhart, Mark Hines, Dwight Thomas, Nicholas McFadden, Dustin Surwill, Yan Ashrapov,
- 👥 deleted-U05EFH3S2TA, Nicholas McFadden, Dustin Surwill,
- 👥 Cameron Rentch, Andy Rogers, deleted-U055HQT39PC, Mark Maniora, Greg Owen, Malissa Phillips,
- 👥 Nicholas McFadden, deleted-U06F9N9PB2A, Daniel Schussler, Dustin Surwill, Edward Weber, Richard Schnitzler,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04R23BEW3V, deleted-U05EFH3S2TA, deleted-U06C7A8PVLJ, deleted-U06F9N9PB2A,
- 👥 Nicholas McFadden, Daniel Schussler, Dustin Surwill, Edward Weber,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, Nicholas McFadden, Edward Weber,
- 👥 deleted-U04GG7BCZ5M, deleted-U055HQT39PC, Malissa Phillips,
- 👥 Jack Altunyan, Ryan Vaspra, Zekarias Haile,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, Nicholas McFadden, deleted-U06C7A8PVLJ, deleted-U07CRGCBVJA, Zekarias Haile,
- 👥 Cameron Rentch, Ryan Vaspra, Malissa Phillips, Zekarias Haile,
- 👥 deleted-U06CVB2MHRN, deleted-U072B7ZV4SH, deleted-U072JS2NHRQ, Dustin Surwill, deleted-U08FJ290LUX,
- 👥 Dwight Thomas, Daniel Schussler, Dustin Surwill, Zekarias Haile,
- 👥 deleted-U055HQT39PC, Mark Maniora, deleted-U06F9N9PB2A, Malissa Phillips,
- 👥 Malissa Phillips, Daniel Schussler, Dustin Surwill,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Malissa Phillips, deleted-U08LK2U7YBW,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, Dustin Surwill, Carter Matzinger,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, Mark Maniora, Joe Santana, Greg Owen, Malissa Phillips, Zekarias Haile,
- 👥 deleted-U055HQT39PC, Greg Owen, deleted-U062D2YJ15Y, Malissa Phillips, James Turner,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U05EFH3S2TA,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Mark Maniora, Yan Ashrapov,
- 👥 Ryan Vaspra, Mark Maniora, Malissa Phillips, Zekarias Haile,
- 👥 deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U062D2YJ15Y, James Turner, Carter Matzinger,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, Joe Santana, deleted-U05EFH3S2TA, deleted-U06C7A8PVLJ,
- 👥 Mike Everhart, Dwight Thomas, Nicholas McFadden, Dustin Surwill,
- 👥 deleted-U055HQT39PC, Greg Owen, Malissa Phillips,
- 👥 deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U062D2YJ15Y, James Turner,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, deleted-U08LK2U7YBW, Carter Matzinger,
- 👥 Cameron Rentch, Joe Santana, Melanie Macias,
- 👥 Ryan Vaspra, Nicholas McFadden, James Scott, Chris Krecicki,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U08LK2U7YBW,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, Zekarias Haile, deleted-U08LK2U7YBW,
- 👥 Cameron Rentch, Andy Rogers, Mark Maniora, Joe Santana, Greg Owen, Malissa Phillips,
- 👥 Nicholas McFadden, Daniel Schussler, Dustin Surwill, Zekarias Haile, Richard Schnitzler,
- 👥 Cameron Rentch, Ryan Vaspra, Joe Santana, Melanie Macias, Jennifer Durnell,
- 👥 Marc Barmazel, Cameron Rentch, Joe Santana, Nicholas McFadden, Dustin Surwill, Carter Matzinger,
- 👥 Greg Owen, Malissa Phillips, deleted-U08LK2U7YBW,
- 👥 Nicholas McFadden, Chris Krecicki, Carter Matzinger,
- 👥 deleted-U04GZ79CPNG, Joe Santana, deleted-U06C7A8PVLJ, Carter Matzinger,
- 👥 deleted-U05496RCQ9M, Mark Maniora, Malissa Phillips,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, Malissa Phillips, Carter Matzinger,
- 👥 Nick Ward, Dustin Surwill, Chris Krecicki, Carter Matzinger,
- 👥 deleted-U05DY7UGM2L, Melanie Macias, Jennifer Durnell,
- 👥 David Evans, Sean Marshall, Melanie Macias,
- 👥 deleted-U04HFGHL4RW, Malissa Phillips, deleted-U08LK2U7YBW,
- 👥 Mark Maniora, Malissa Phillips, Dustin Surwill,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, James Turner,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, Nicholas McFadden, deleted-U06C7A8PVLJ, James Turner, deleted-U07UDKM724B,
- 👥 Ryan Vaspra, Joe Santana, James Scott, Nick Ward, Dustin Surwill, James Turner, Chris Krecicki,
- 👥 Cameron Rentch, Andy Rogers, Carter Matzinger,
- 👥 Joe Santana, Nick Ward, Richard Schnitzler, Carter Matzinger,
- 👥 Dustin Surwill, James Turner, Chris Krecicki,
- 👥 Cameron Rentch, Andy Rogers, Mark Maniora, deleted-U05R2LQKHHR, Malissa Phillips,
- 👥 deleted-U04GZ79CPNG, Mark Maniora, Malissa Phillips, Dustin Surwill,
- 👥 Greg Owen, Malissa Phillips, CC Kitanovski,
- 👥 Ryan Vaspra, Lee Zafra, Melanie Macias, Jennifer Durnell,
- 👥 Cameron Rentch, Tony, Andy Rogers, deleted-U055HQT39PC, Carter Matzinger,
- 👥 Andy Rogers, Mark Maniora, Malissa Phillips,
- 👥 Tony Jones, deleted-U04GG7BCZ5M, deleted-U055HQT39PC, deleted-U05EFH3S2TA, Malissa Phillips,
- 👥 deleted-U04HFGHL4RW, deleted-U04R23BEW3V, Malissa Phillips,
- 👥 deleted-U06VDQGHZLL, Nick Ward, James Turner, Carter Matzinger,
- 👥 deleted-U05496RCQ9M, Greg Owen, Malissa Phillips,
- 👥 Nick Ward, James Turner, Carter Matzinger,
- 👥 Ryan Vaspra, deleted-U04GG7BCZ5M, Dustin Surwill, James Turner,
- 👥 deleted-U04GZ79CPNG, deleted-U06F9N9PB2A, Dustin Surwill,
- 👥 Mike Everhart, Mark Hines, Caleb Peters,
- 👥 Marc Barmazel, Cameron Rentch, Ryan Vaspra, Andy Rogers, Joe Santana, James Scott, CC Kitanovski, Chris Krecicki,
- 👥 Nick Ward, Dustin Surwill, Carter Matzinger,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04G7CGMBPC, Mark Maniora, Greg Owen, Malissa Phillips,
- 👥 Ryan Vaspra, Nick Ward, James Turner, Edward Weber,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04GZ79CPNG,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, deleted-U06F9N9PB2A, deleted-U07JFNH9C7P,
- 👥 Ryan Vaspra, Andy Rogers, deleted-U06C7A8PVLJ, James Turner,
- 👥 Ryan Vaspra, Caleb Peters, Adrienne Hester, Lee Zafra,
- 👥 Henri Engle, VernonEvans, Chris Krecicki,
- 👥 Dustin Surwill, Richard Schnitzler, Carter Matzinger,
- 👥 Ryan Vaspra, Andy Rogers, Nick Ward, Malissa Phillips, Carter Matzinger,
- 👥 Ryan Vaspra, Andy Rogers, Nick Ward, Malissa Phillips,
- 👥 Cameron Rentch, Ryan Vaspra, Andy Rogers, Joe Santana, CC Kitanovski, Chris Krecicki,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, Joe Santana, Nicholas McFadden, deleted-U06C7A8PVLJ, Carter Matzinger,
- 👥 Ryan Vaspra, Greg Owen, deleted-U06VDQGHZLL, Nick Ward, Malissa Phillips, James Turner, Carter Matzinger,
- 👥 Cameron Rentch, Joe Santana, Nicholas McFadden, Yan Ashrapov,
- 👥 Cameron Rentch, Joe Santana, Nicholas McFadden, Carter Matzinger,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04HFGHL4RW, Nick Ward, Malissa Phillips, Carter Matzinger,
- 👥 deleted-U05496RCQ9M, Mark Maniora, Nick Ward, Malissa Phillips, Carter Matzinger,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Carter Matzinger,
- 👥 Ryan Vaspra, Greg Owen, Malissa Phillips, Zekarias Haile,
- 👥 Ryan Vaspra, Luis Cortes, Mark Maniora, Nicholas McFadden, Malissa Phillips, Zekarias Haile, Edward Weber,
- 👥 Ryan Vaspra, Joe Santana, Nick Ward, Carter Matzinger,
- 👥 deleted-U05496RCQ9M, Mark Maniora, deleted-U06VDQGHZLL, Nick Ward, Malissa Phillips, James Turner, Carter Matzinger,
- 👥 deleted-U05F548NU5V, Nicholas McFadden, Yan Ashrapov,
- 👥 Greg Owen, Malissa Phillips, Dustin Surwill,
- 👥 deleted-U05496RCQ9M, Malissa Phillips, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, Joe Santana, deleted-U05EFH3S2TA, deleted-U06C7A8PVLJ, Carter Matzinger,
- 👥 Ryan Vaspra, Joe Santana, James Scott, Dustin Surwill, CC Kitanovski, Chris Krecicki, Tyson Green,
- 👥 deleted-U04R23BEW3V, Malissa Phillips, Carter Matzinger,
- 👥 Ryan Vaspra, Tony, Nick Ward, Malissa Phillips, James Turner,
- 👥 Ryan Vaspra, Nick Ward, Carter Matzinger,
- 👥 Ryan Vaspra, deleted-U04HFGHL4RW, Nick Ward, James Turner, deleted-U08LK2U7YBW, Carter Matzinger,
- 👥 Dustin Surwill, Edward Weber, Richard Schnitzler,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW, deleted-U04R23BEW3V, deleted-U05EFH3S2TA, deleted-U06F9N9PB2A, Malissa Phillips,
- 👥 deleted-U06F9N9PB2A, Dustin Surwill, CC Kitanovski,
- 👥 James Turner, CC Kitanovski, Chris Krecicki,
- 👥 deleted-U04HFGHL4RW, deleted-U04R23BEW3V, Greg Owen, Malissa Phillips,
- 👥 Ryan Vaspra, James Scott, CC Kitanovski,
- 👥 deleted-U05496RCQ9M, Dustin Surwill, Chris Krecicki,
- 👥 deleted-U04R23BEW3V, deleted-U06F9N9PB2A, Malissa Phillips,
- 👥 Ryan Vaspra, Greg Owen, Zekarias Haile,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U055HQT39PC, Mark Maniora, Joe Santana, Nicholas McFadden, Malissa Phillips, Carter Matzinger,
- 👥 Nick Ward, Malissa Phillips, Carter Matzinger,
- 👥 deleted-U04GG7BCZ5M, deleted-U04HFGHL4RW, deleted-U055HQT39PC, Malissa Phillips, Carter Matzinger,
- 👥 Cameron Rentch, deleted-U055HQT39PC, Mark Maniora,
- 👥 Cameron Rentch, Kris Standley, Yan Ashrapov,
- 👥 Cameron Rentch, deleted-U055HQT39PC, deleted-U06F9N9PB2A,
- 👥 James Scott, Dustin Surwill, Chris Krecicki,
- 👥 Ryan Vaspra, Rose Fleming, Malissa Phillips, James Turner,
- 👥 deleted-U04R23BEW3V, Nick Ward, Malissa Phillips, Carter Matzinger,
- 👥 Nicholas McFadden, Dustin Surwill, Zekarias Haile, Edward Weber,
- 👥 Cameron Rentch, Ryan Vaspra, Joe Santana, James Scott, James Turner, CC Kitanovski,
- 👥 Cameron Rentch, Ryan Vaspra, James Scott, CC Kitanovski,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U04GZ79CPNG, Joe Santana, Nicholas McFadden, deleted-U06C7A8PVLJ, Zekarias Haile, Carter Matzinger,
- 👥 deleted-U04GG7BCZ5M, Nicholas McFadden, deleted-U06C7A8PVLJ,
- 👥 Joe Santana, Nick Ward, Daniel Schussler, Carter Matzinger,
- 👥 Ryan Vaspra, deleted-U04GZ79CPNG, CC Kitanovski,
- 👥 Cameron Rentch, Joe Santana, deleted-U05EFH3S2TA, Carter Matzinger,
- 👥 Dustin Surwill, James Turner, CC Kitanovski,
- 👥 Nicholas McFadden, Dustin Surwill, Edward Weber,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04KC9L4HRB,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04KC9L4HRB,
- 👥 Cameron Rentch, deleted-U04GU9EUV9A, deleted-U04HFGHL4RW,
- 👥 Ryan Vaspra, luke, deleted-U04GZ79CPNG,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW,
- 👥 Cameron Rentch, Andy Rogers, deleted-U05DY7UGM2L,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05DY7UGM2L,
- 👥 Ryan Vaspra, deleted-U05CTUBCP7E, deleted-U05CXRE6TBK,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04KC9L4HRB, michaelbrunet, deleted-U067A4KAB9U,
- 👥 deleted-U04H9CHDJL9, deleted-U04HFGHL4RW, deleted-U04KC9L4HRB, michaelbrunet, deleted-U067A4KAB9U, deleted-U0686RGAEJC,
- 👥 Greg Owen, deleted-U06AYDQ4WVA, deleted-U06C7A8PVLJ,
- 👥 ian, deleted-U04GU9EUV9A, deleted-U04H9CHDJL9,
- 👥 Andy Rogers, deleted-U04GU9EUV9A, deleted-U06AYDQ4WVA,
- 👥 Cameron Rentch, Tony, deleted-U04KC9L4HRB, michaelbrunet, deleted-U067A4KAB9U, deleted-U0686RGAEJC,
- 👥 Cameron Rentch, deleted-U04KC9L4HRB, deleted-U0686RGAEJC,
- 👥 Cameron Rentch, Tony, deleted-U04GZ79CPNG, deleted-U04KC9L4HRB, michaelbrunet, deleted-U067A4KAB9U, deleted-U0686RGAEJC,
- 👥 Cameron Rentch, deleted-U04KC9L4HRB, deleted-U05M3DME3GR,
- 👥 Ryan Vaspra, Andy Rogers, LaToya Palmer, deleted-U04GZ79CPNG, deleted-U04KC9L4HRB, Adrienne Hester,
- 👥 LaToya Palmer, deleted-U042MMWVCH2, Adrienne Hester, deleted-U059JKB35RU, Julie-Margaret Johnson,
- 👥 Cameron Rentch, deleted-U04GU9EUV9A, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U04KC9L4HRB, deleted-U04R23BEW3V, michaelbrunet, deleted-U067A4KAB9U, deleted-U0686RGAEJC,
- 👥 LaToya Palmer, deleted-U04GZ79CPNG, deleted-U04KC9L4HRB,
- 👥 Ryan Vaspra, luke, deleted-U06AYDQ4WVA,
- 👥 deleted-U04KC9L4HRB, michaelbrunet, deleted-U067A4KAB9U, deleted-U0686RGAEJC,
- 👥 Tony, deleted-U04GZ79CPNG, deleted-U04KC9L4HRB, deleted-U06AYDQ4WVA, deleted-U06C7A8PVLJ,
- 👥 ian, deleted-U04GU9EUV9A, deleted-U06CKF9DKND,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U04KC9L4HRB, michaelbrunet, deleted-U067A4KAB9U,
- 👥 deleted-U02394YD4GY, deleted-U02E2EXSJJC, deleted-U042MMWVCH2, deleted-U059JKB35RU, korbin,
- 👥 deleted-U02E2EXSJJC, deleted-U042MMWVCH2, deleted-U059JKB35RU, korbin,
- 👥 LaToya Palmer, Adrienne Hester, deleted-U069G4WMMD4,
- 👥 Cameron Rentch, Tony, deleted-U04GU9EUV9A, deleted-U04KC9L4HRB, michaelbrunet, deleted-U067A4KAB9U,
- 👥 Cameron Rentch, Tony, deleted-U04GU9EUV9A, deleted-U04GZ79CPNG, deleted-U04KC9L4HRB,
- 👥 deleted-U04GZ79CPNG, deleted-U04KC9L4HRB, michaelbrunet, deleted-U067A4KAB9U,
- 👥 deleted-U04KC9L4HRB, michaelbrunet, deleted-U067A4KAB9U,
- 👥 deleted-U02E2EXSJJC, LaToya Palmer, deleted-U042MMWVCH2, deleted-U059JKB35RU, deleted-U069G4WMMD4,
- 👥 deleted-U04GZ79CPNG, deleted-U04KC9L4HRB, Mark Maniora, deleted-U06AYDQ4WVA, deleted-U06C7A8PVLJ,
- 👥 LaToya Palmer, deleted-U059JKB35RU, deleted-U069G4WMMD4,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U056TJH4KUL, deleted-U05DY7UGM2L,
- 👥 deleted-U02E2EXSJJC, LaToya Palmer, deleted-U042MMWVCH2, Adrienne Hester, deleted-U059JKB35RU, Melanie Macias, Jennifer Durnell,
- 👥 deleted-U05DY7UGM2L, michaelbrunet, deleted-U067A4KAB9U,
- 👥 Tony, deleted-U04GU9EUV9A, deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, deleted-U06AYDQ4WVA,
- 👥 Ryan Vaspra, Tony, Brian Hirst, luke, deleted-U04GZ79CPNG, deleted-U05QUSWUJA2, deleted-U06AYDQ4WVA,
- 👥 Ryan Vaspra, Joe Santana, deleted-U0679HSE82K, deleted-U06JMNZ6HQE, deleted-U06M9VC79A5,
- 👥 Luis Cortes, deleted-U04TA486SM6, deleted-U06AYDQ4WVA, deleted-U06KK7QLM55,
- 👥 deleted-U02JM6UC78T, Kris Standley, deleted-U05R3DS0AGL,
- 👥 Cameron Rentch, deleted-U04GU9EUV9A, deleted-U04HFGHL4RW, deleted-U05ANA2ULDD,
- 👥 Mike Everhart, deleted-U04GZ79CPNG, deleted-U04TA486SM6,
- 👥 Ryan Vaspra, deleted-U02JM6UC78T, Kris Standley,
- 👥 deleted-U3H80B3FH, deleted-U02JM6UC78T, Kris Standley, deleted-U05R3DS0AGL,
- 👥 Luis Cortes, deleted-U06KK7QLM55, deleted-U06VDQGHZLL,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04R23BEW3V, deleted-U055HQT39PC,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, Nicholas McFadden,
- 👥 Nicholas McFadden, deleted-U06N28XTLE7, deactivateduser168066,
- 👥 Ryan Vaspra, luke, deleted-U06N28XTLE7,
- 👥 Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U072B7ZV4SH,
- 👥 Ryan Vaspra, luke, deleted-U04GZ79CPNG, deleted-U072B7ZV4SH,
- 👥 Ryan Vaspra, luke, deleted-U04GZ79CPNG, deleted-U06N28XTLE7,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05QUSWUJA2,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, deleted-U06N28XTLE7,
- 👥 Ryan Vaspra, deleted-U02JM6UC78T, Kris Standley, deleted-U05R3DS0AGL,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U05ANA2ULDD, deleted-U07097NJDA7, Nick Ward, deleted-U08J0GK8QG7, deleted-U08LK2U7YBW,
- 👥 Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U05QUSWUJA2,
- 👥 Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U06N28XTLE7, deleted-U072JS2NHRQ,
- 👥 Brian Hirst, deleted-U04G7CGMBPC, deleted-U06GD22CLDC,
- 👥 Brittany Barnett, deleted-U04GZ79CPNG, deleted-U04R23BEW3V, deleted-U06C7A8PVLJ, deleted-U06N28XTLE7, deleted-U072B7ZV4SH, deleted-U072JS2NHRQ, deleted-U07SBM5MB32, IT SUPPORT - Dennis Shaull,
- 👥 Cameron Rentch, Ryan Vaspra, Brian Hirst, deleted-U04HFGHL4RW, deleted-U06CR5MH88H,
- 👥 Brittany Barnett, deleted-U05EFH3S2TA, deleted-U077J4CPUCC,
- 👥 Ryan Vaspra, deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U05EFH3S2TA,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Malissa Phillips,
- 👥 deleted-U06NZP17L83, Daniel Schussler, Dustin Surwill,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, deleted-U062D2YJ15Y, deleted-U06NZP17L83, Dustin Surwill,
- 👥 deleted-U055HQT39PC, Mark Maniora, deleted-U05QUSWUJA2, ahsan,
- 👥 Tony Jones, deleted-U04GZ79CPNG, deleted-U055HQT39PC, deleted-U05EFH3S2TA, deleted-U06N28XTLE7,
- 👥 Tony, deleted-U06AYDQ4WVA, deleted-U06CKF9DKND,
- 👥 deleted-U05496RCQ9M, deleted-U06NZP17L83, James Turner,
- 👥 Brittany Barnett, deleted-U05EFH3S2TA, deleted-U06AYDQ4WVA,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Rose Fleming, brian580, Malissa Phillips,
- 👥 Ryan Vaspra, deleted-U055HQT39PC, deleted-U06GD22CLDC,
- 👥 deleted-U04GZ79CPNG, deleted-U05QUSWUJA2, deleted-U06VDQGHZLL, Dustin Surwill,
- 👥 deleted-U05EFH3S2TA, deleted-U0679HSAMSB, Vilma Farrar,
- 👥 deleted-U04HFGHL4RW, deleted-U05DY7UGM2L, Nick Ward,
- 👥 deleted-U04GZ79CPNG, deleted-U05QUSWUJA2, Dustin Surwill,
- 👥 deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nicholas McFadden, deleted-U05QUSWUJA2,
- 👥 LaToya Palmer, Adrienne Hester, deleted-U05DY7UGM2L, deleted-U05R2LQKHHR,
- 👥 deleted-U05DY7UGM2L, deleted-U05QUSWUJA2, Nick Ward,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, brian580, deleted-U06F9N9PB2A, Malissa Phillips,
- 👥 deleted-U04GZ79CPNG, deleted-U04TA486SM6, deleted-U055HQT39PC, Nicholas McFadden, deleted-U06BY11C2C8, deleted-U06D58FE1P0, deleted-U06F9N9PB2A, deleted-U072JS2NHRQ, deleted-U077J4CPUCC,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, deleted-U062D2YJ15Y, Malissa Phillips,
- 👥 ian, deleted-U04HQNGUHNF, deleted-U05ANA2ULDD, deleted-U0626DKP8H4,
- 👥 Ryan Vaspra, Brian Hirst, deleted-U06GD22CLDC,
- 👥 ian, deleted-U04H9CHDJL9, deleted-U04HQNGUHNF, deleted-U05ANA2ULDD,
- 👥 deleted-U04GZ79CPNG, deleted-U06AYDQ4WVA, Dustin Surwill,
- 👥 ian, deleted-U062D0RKLHZ, deleted-U07097NJDA7,
- 👥 deleted-U05DY7UGM2L, deleted-U06AYDQ4WVA, Nick Ward, deleted-U072GK8LNDS,
- 👥 deleted-U05DY7UGM2L, Nsay Y, deleted-U06MDMJ4X96,
- 👥 Nicholas McFadden, deleted-U06F9N9PB2A, deleted-U07EH86AAN9, Dustin Surwill,
- 👥 Joe Santana, deleted-U05QUSWUJA2, deleted-U06N28XTLE7,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U05DY7UGM2L, James Scott,
- 👥 Marc Barmazel, Cameron Rentch, deleted-U04HFGHL4RW,
- 👥 Ryan Vaspra, deleted-U055HQT39PC, deleted-U06C7A8PVLJ, deleted-U07UDN65C3U,
- 👥 Joe Santana, Nicholas McFadden, deleted-U06N28XTLE7, deleted-U06VDQGHZLL, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, Joe Santana, deleted-U07JFNH9C7P,
- 👥 deleted-U05QUSWUJA2, ahsan, deleted-U07LSBPN6D8,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, Dwight Thomas, deleted-U062D2YJ15Y,
- 👥 deleted-U05EFH3S2TA, deleted-U06F9N9PB2A, Malissa Phillips, deleted-U07LSBPN6D8,
- 👥 deleted-U04GZ79CPNG, ahsan, Dustin Surwill,
- 👥 Ryan Vaspra, deleted-U04GZ79CPNG, deleted-U06C7A8PVLJ,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, Mark Maniora,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, Mark Maniora, deleted-U062D2YJ15Y,
- 👥 Andy Rogers, deleted-U04GZ79CPNG, deleted-U05R2LQKHHR,
- 👥 deleted-U06F9N9PB2A, deleted-U07EH86AAN9, Dustin Surwill,
- 👥 deleted-U04GG7BCZ5M, deleted-U04HFGHL4RW, Nicholas McFadden,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, deleted-U072JS2NHRQ, Dustin Surwill,
- 👥 Dwight Thomas, deleted-U05QUSWUJA2, deleted-U07LSBPN6D8,
- 👥 deleted-U04J34Q7V4H, deleted-U06BY11C2C8, deleted-U06D58FE1P0, Vilma Farrar,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, ahsan, Dustin Surwill,
- 👥 Ryan Vaspra, deleted-U06C7A8PVLJ, deleted-U06CVB2MHRN,
- 👥 Nicholas McFadden, deleted-U06CVB2MHRN, ahsan, Dustin Surwill,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, deleted-U06VDQGHZLL, ahsan, deleted-U07LSBPN6D8,
- 👥 deleted-U04GZ79CPNG, deleted-U06VDQGHZLL, Dustin Surwill,
- 👥 deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Nicholas McFadden, deleted-U06VDQGHZLL,
- 👥 deleted-U06BY11C2C8, Vilma Farrar, deleted-U077J4CPUCC,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, deleted-U06CVB2MHRN, darrell, Dustin Surwill,
- 👥 deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Malissa Phillips,
- 👥 Nicholas McFadden, deleted-U06F9N9PB2A, Malissa Phillips, deleted-U07EH86AAN9, deleted-U07JJMDR7L3, Dustin Surwill,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, deleted-U062D2YJ15Y, darrell,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, deleted-U062D2YJ15Y, Daniel Schussler,
- 👥 LaToya Palmer, Adrienne Hester, deleted-U05CTUBCP7E, deleted-U069G4WMMD4,
- 👥 deleted-U06F9N9PB2A, ahsan, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U04R23BEW3V, deleted-U055HQT39PC, deleted-U06CR5MH88H,
- 👥 Cameron Rentch, Andy Rogers, deleted-U05EFH3S2TA, deleted-U06F9N9PB2A, Malissa Phillips,
- 👥 Ryan Vaspra, deleted-U06GD22CLDC, deleted-U06VDQGHZLL,
- 👥 Ryan Vaspra, deleted-U06GD22CLDC, deleted-U06VDQGHZLL, deleted-U084DN536J1,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, deleted-U06VDQGHZLL, deleted-U072JS2NHRQ,
- 👥 Nicholas McFadden, deleted-U06F9N9PB2A, Dustin Surwill,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, deleted-U06VDQGHZLL,
- 👥 deleted-U06F9N9PB2A, deleted-U07097NJDA7, Vilma Farrar, deleted-U077J4CPUCC,
- 👥 deleted-U04TA486SM6, deleted-U06K9EUEPLY, darrell,
- 👥 deleted-U06F9N9PB2A, deleted-U07EH86AAN9, deleted-U07JJMDR7L3, Dustin Surwill,
- 👥 Nicholas McFadden, deleted-U0679HSAMSB, deleted-U07AD5U5E6S, Dustin Surwill, deleted-U07PQ4H089G,
- 👥 Kelly C. Richardson, EdS, deleted-U02E2EXSJJC, deleted-U042MMWVCH2, deleted-U059JKB35RU, Lee Zafra,
- 👥 deleted-U04GZ79CPNG, Dwight Thomas, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, deleted-U071ST51P18, VernonEvans,
- 👥 Joe Santana, deleted-U067A4KAB9U, deleted-U06F9N9PB2A, deleted-U06QF9RVD9N,
- 👥 Nicholas McFadden, deleted-U06F9N9PB2A, darrell, deleted-U07EH86AAN9, deleted-U07JJMDR7L3, Dustin Surwill,
- 👥 Kelly C. Richardson, EdS, deleted-U059JKB35RU, Lee Zafra,
- 👥 deleted-U06C7A8PVLJ, deleted-U07EH86AAN9, Jehoshua Josue,
- 👥 deleted-U04GG7BCZ5M, deleted-U055HQT39PC, darrell, Daniel Schussler,
- 👥 deleted-U05CTUBCP7E, Nicholas McFadden, Daniel Schussler, deleted-U07PQ4H089G,
- 👥 deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, deleted-U06VDQGHZLL, deleted-U07097NJDA7, Malissa Phillips,
- 👥 deleted-U04GZ79CPNG, deleted-U06C7A8PVLJ, ahsan,
- 👥 deleted-U04HTA3157W, deleted-U07097NJDA7, Amanda Hembree, deleted-U08J0GK8QG7, deleted-U08JK7E85FE,
- 👥 deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U06VDQGHZLL, Malissa Phillips,
- 👥 Dwight Thomas, deleted-U06F9N9PB2A, ahsan, Daniel Schussler, Dustin Surwill, Zekarias Haile,
- 👥 deleted-U04GG7BCZ5M, deleted-U04R23BEW3V, deleted-U055HQT39PC, deleted-U05CSE7AN1M, Malissa Phillips,
- 👥 deleted-U04HFGHL4RW, darrell, deleted-U06VDQGHZLL,
- 👥 deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U06VDQGHZLL, James Turner,
- 👥 deleted-U072JS2NHRQ, ahsan, Dustin Surwill,
- 👥 Luis Cortes, deleted-U04GG7BCZ5M, deleted-U04HFGHL4RW, deleted-U05UUJ889C3,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, deleted-U06CVB2MHRN,
- 👥 Ryan Vaspra, deleted-U055HQT39PC, deleted-U06C7A8PVLJ, Malissa Phillips, James Turner,
- 👥 deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U05DY7UGM2L, Nicholas McFadden, deleted-U06VDQGHZLL,
- 👥 Ryan Vaspra, Brian Hirst, deleted-U06C7A8PVLJ, deleted-U06VDQGHZLL, James Turner,
- 👥 deleted-U04HFGHL4RW, deleted-U055HQT39PC, Mark Maniora,
- 👥 deleted-U04GZ79CPNG, deleted-U06C7A8PVLJ, Dustin Surwill,
- 👥 Nicholas McFadden, deleted-U06CF0G77BN, Dustin Surwill, Zekarias Haile, deleted-U07PQ4H089G,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, deleted-U062D2YJ15Y, deleted-U06VDQGHZLL,
- 👥 deleted-U04GG7BCZ5M, deleted-U055HQT39PC, Daniel Schussler,
- 👥 deleted-U04GZ79CPNG, Dustin Surwill, deleted-U08FJ290LUX,
- 👥 deleted-U04G7CGMBPC, deleted-U04GZ79CPNG, deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U05QUSWUJA2, deleted-U06VDQGHZLL, Malissa Phillips, James Turner,
- 👥 deleted-U055HQT39PC, deleted-U06F9N9PB2A, Malissa Phillips, Dustin Surwill,
- 👥 deleted-U05QUSWUJA2, deleted-U06C7A8PVLJ, deleted-U06F9N9PB2A, deleted-U07JJMDR7L3, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U05DY7UGM2L, deleted-U06VDQGHZLL, deleted-U07CRGCBVJA,
- 👥 deleted-U05MX9P0D7H, Rose Fleming, deleted-U05QUSWUJA2, deleted-U07EJ7K9HNE,
- 👥 Cameron Rentch, deleted-U04HFGHL4RW, deleted-U06F9N9PB2A,
- 👥 deleted-U04GG7BCZ5M, deleted-U04R23BEW3V, deleted-U05496RCQ9M, deleted-U055HQT39PC, deleted-U05CSE7AN1M, Malissa Phillips,
- 👥 deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U05EFH3S2TA, Nicholas McFadden,
- 👥 Andy Rogers, deleted-U06F9N9PB2A, deleted-U07EJ7K9HNE,
- 👥 deleted-U055HQT39PC, deleted-U06F9N9PB2A, Malissa Phillips,
- 👥 deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, Nicholas McFadden, deleted-U06VDQGHZLL, Dustin Surwill, deleted-U08JK7E85FE,
- 👥 deleted-U055HQT39PC, deleted-U06CR5MH88H, deleted-U06F9N9PB2A, Malissa Phillips,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, deleted-U06C7A8PVLJ, Daniel Schussler, Richard Schnitzler,
- 👥 Nicholas McFadden, deleted-U06C7A8PVLJ, deleted-U06F9N9PB2A,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, Greg Owen, deleted-U062D2YJ15Y, deleted-U06RTMNQD9T,
- 👥 deleted-U04GZ79CPNG, deleted-U055HQT39PC, Dustin Surwill,
- 👥 deleted-U04GZ79CPNG, deleted-U055HQT39PC, Nicholas McFadden, deleted-U06C7A8PVLJ,
- 👥 Nicholas McFadden, deleted-U06C7A8PVLJ, Richard Schnitzler,
- 👥 Cameron Rentch, deleted-U05EFH3S2TA, deleted-U06F9N9PB2A, Malissa Phillips,
- 👥 Andy Rogers, deleted-U05496RCQ9M, deleted-U055HQT39PC, deleted-U062D2YJ15Y,
- 👥 Nicholas McFadden, deleted-U05QUSWUJA2, deleted-U08GMHAPRK2,
- 👥 Cameron Rentch, Ryan Vaspra, Nicholas McFadden, deleted-U06C7A8PVLJ, Zekarias Haile,
- 👥 Nicholas McFadden, deleted-U06C7A8PVLJ, deleted-U06F9N9PB2A, Dustin Surwill,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U05QUSWUJA2, deleted-U06C7A8PVLJ, deleted-U07CRGCBVJA,
- 👥 deleted-U05EFH3S2TA, deleted-U06F9N9PB2A, deleted-U06VDQGHZLL, James Turner,
- 👥 deleted-U06F9N9PB2A, deleted-U07FL2UKG58, Dustin Surwill,
- 👥 deleted-U071ST51P18, deleted-U07JFNH9C7P, VernonEvans,
- 👥 Cameron Rentch, Andy Rogers, deleted-U04HFGHL4RW, deleted-U05EFH3S2TA,
- 👥 deleted-U06C7A8PVLJ, deleted-U06F9N9PB2A, Dustin Surwill,
- 👥 deleted-U02E2EXSJJC, LaToya Palmer, Adrienne Hester, deleted-U059JKB35RU,
- 👥 deleted-U04GZ79CPNG, deleted-U05EFH3S2TA, deleted-U06VDQGHZLL, Dustin Surwill,
- 👥 deleted-U04GZ79CPNG, deleted-U055HQT39PC, deleted-U06VDQGHZLL, deleted-U072JS2NHRQ, Dustin Surwill,
- 👥 deleted-U04GZ79CPNG, Nicholas McFadden, deleted-U06C7A8PVLJ, deleted-U06VDQGHZLL, deleted-U095QBJFFME,
- 👥 Andy Rogers, deleted-U06F9N9PB2A, deleted-U07EJ7K9HNE, deleted-U07LMBDDDTN,
- 👥 Cameron Rentch, Ryan Vaspra, deleted-U05QUSWUJA2, deleted-U07UDKM724B,
- 👥 Nicholas McFadden, deleted-U06C7A8PVLJ, deleted-U06VDQGHZLL, deleted-U095QBJFFME,
- 👥 Nicholas McFadden, deleted-U06C7A8PVLJ, deleted-U06VDQGHZLL, deleted-U07CRGCBVJA, deleted-U095QBJFFME,
- 👥 deleted-U04GZ79CPNG, deleted-U055HQT39PC, deleted-U06CR5MH88H, Dustin Surwill,
- 👥 Cameron Rentch, deleted-U04GZ79CPNG, Malissa Phillips,
- 👥 deleted-U072B7ZV4SH, deleted-U072JS2NHRQ, Aidan Celeste, deleted-U08GMHAPRK2,
- 👥 deleted-U06C7A8PVLJ, Daniel Schussler, deleted-U07LSBPN6D8,
- 👥 deleted-U06VDQGHZLL, James Turner, deleted-U095QBJFFME,
- 👥 Joe Santana, Nicholas McFadden, deleted-U06VDQGHZLL, Daniel Schussler, Dustin Surwill, Edward Weber, Richard Schnitzler, deleted-U095QBJFFME,
- 👥 deleted-U04GZ79CPNG, Dustin Surwill, Jehoshua Josue,
- 👥 deleted-U04GZ79CPNG, Dustin Surwill, Jehoshua Josue, deleted-U095QBJFFME,
- 👥 deleted-U05EFH3S2TA, deleted-U06VDQGHZLL, James Turner, Carter Matzinger,
- 👥 deleted-U06F9N9PB2A, CC Kitanovski, deleted-U098FUQGCMA,
- 👥 deleted-U04GG7BCZ5M, deleted-U04GZ79CPNG, deleted-U05496RCQ9M, deleted-U055HQT39PC, Mark Maniora, deleted-U062D2YJ15Y, deleted-U06C7A8PVLJ, deleted-U07LSBPN6D8,
- 👥 deleted-U04GZ79CPNG, Dustin Surwill, Chris Krecicki,
- 👥 deleted-U055HQT39PC, Nicholas McFadden, deleted-U07LSBPN6D8,
- 👥 deleted-U06F9N9PB2A, deleted-U06VDQGHZLL, Dustin Surwill, deleted-U095QBJFFME,
- 👥 deleted-U05EFH3S2TA, deleted-U06VDQGHZLL, Carter Matzinger,
- 👥 deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U05EFH3S2TA, deleted-U06F9N9PB2A, deleted-U07CRGCBVJA, Dustin Surwill, deleted-U095QBJFFME,
- 👥 deleted-U04GZ79CPNG, deleted-U05496RCQ9M, Mark Maniora, deleted-U072B7ZV4SH, deleted-U072JS2NHRQ, Dustin Surwill,
- 👥 deleted-U04HFGHL4RW, deleted-U055HQT39PC, Joe Santana, deleted-U06VDQGHZLL, deleted-U095QBJFFME,
- 👥 deleted-U05496RCQ9M, deleted-U055HQT39PC, Mark Maniora, deleted-U06VDQGHZLL, Malissa Phillips, Carter Matzinger,
- 👥 deleted-U04R23BEW3V, deleted-U06VDQGHZLL, James Turner,
- 👥 deleted-U04GG7BCZ5M, deleted-U04HFGHL4RW, deleted-U055HQT39PC, deleted-U05CSE7AN1M, deleted-U062D2YJ15Y, deleted-U06VDQGHZLL, James Turner, deleted-U095QBJFFME,
- 👥 deleted-U05496RCQ9M, deleted-U06VDQGHZLL, Dustin Surwill, deleted-U095QBJFFME,
- 👥 Cameron Rentch, Andy Rogers, deleted-U06F9N9PB2A,
- 👥 deleted-U04HFGHL4RW, deleted-U05EFH3S2TA, Anthony Soboleski,
- 👥 deleted-U04R23BEW3V, deleted-U06F9N9PB2A, Malissa Phillips, deleted-U095QBJFFME,
- 👥 Cameron Rentch, deleted-U06C7A8PVLJ, deleted-U07CRGCBVJA, deleted-U095QBJFFME,


Sending this up to you for a confirmation check and guidance on our next steps.

if you run the following command in the directory as the definitions.json, it will reformat the json to be more readable: python -c "import json;f=open('definition.json', 'r+');d=json.load(f);f.seek(0);json.dump(d,f,indent=4)"
Hey- all that sneezing yesterday turned into a nasty cough overnight. Is it alright if I work from home today? I'm happy to hop on videochat or whatever I need to go throughout the day
I'm just coughing like every 20-30 seconds and dont want to get everyone else sick
whenever you go back the report you were working on last week. take a look at the status report in the reports tab of lawruler: https://tortintakeprofessionals.lawruler.com/status-report.aspx here some example data from vga for the last week.

Thank you for allowing me to work from home today- I feel like absolute garbo
Since we got the other stuff done, I am going to work on my similarity checker
Making good progress.. running into the usual, make a fix, that breaks something else to fix but its going in the right direction
More can be done to it but I posted a quick demo in the main chat
I hit a flow with it, and just kept going through lunch so I'ma take my lunch now- Is there anything specific I should be working on when I get back?
You can help the others with what I sent you in email
Looks like I'm not getting any notifs for gmail- Is there a recommended way to set it up so it pops in slack? When I used teams previously it was all in house with outlook/microsoft so it was pretty seamless
not sure. i just sent it that way since it was an attachment. daniel is currently working on it
Can you send the instrutions/notes on gcp mapping you have to dwight?
Sure thing- Where does the monday board live for everything that needs to be mapped off of MPA?
should just be our api integrations board
I'm not seeing anything on here for what has been mapped and what has not?
Dustin?? I really want to get started on this, but without clarification on what we need to work on, we can't start...
Are we waiting for something specific?
work with the team. basicly map anything on monday that is for an integration. we may need a sheet but i thought i heard ahsan mention something
Hey there, sorry to bug ya but I'm trying to figure out an issue with this code and was wondering if you knew immedietly what it might be? If not I can keep digging but I don't want to waste any more time than I already have
I attempted to redownload off github to ensure I have a fresh and working copy but no luck

show me the end of the traceback. the bottom of the log

save the mpabody.json and lawrulerbody.txt then try again
Well damn- I enabled auto-save on vscode, and it's worked every other time except for this.
that worked- I figured it was something simple. Thank ya sir!
That should work but lemme know if there is any issue with it
I'm gonna rest for a little over lunch so I'll be away from PC but txt me if you need anything
I have not tested it, but at first glance it will need a few changes in the first 15 lines
Some of the ones that are normally in the first 15, may spread throughout- after adding the defaults, I checked for duplicates and deleted the ones that were in there already
Can you help write up a 1 page proposal for our team to have admin access / full control over our systems and how it would allow us to work much more effectively? I will send the 4 tickets I currently have open with Joe.
Sure thing' Sounds like a fun challenge - Would you like me to momentarily step away from the mapping to do that?
finish the one you are working on first
This is a hot topic- I'm gonna make this really good lol
Are you still taking tomorrow off or working from home?
Still taking tomorrow off as of now - I should be getting my tests back to figure out what's going on in the next hour or so that will let me know if I am contagious or not
I'm not sure if anyone shared with you, but that weird runny nose/ sneezy thing turned into a cough and a rash that covered my throat and made it hard to breath in like 24hrs
It was the most bizarre thing- but doctors ran a bunch of tests on me and pumped me full of steroids and other meds and it's getting better? I am just isolating until I get my tests back to make sure I don't accidently spread the next plague
So little background for ya that I'm not sure if I told you about before... When I was in school I was going for cyber sec before realizing that isn't really what I wanted to do, but I got decently far
I also spoke to my GF about the proposal because she ran privacy and security for her team at her last company
Little over a page, but it's about a page of actual content without the header and references.
https://docs.google.com/document/d/1X475cydwjIpE9dt6Y4L0k1FeeBJ2cEJlNlSpAiSSlQ0/edit?usp=sharing
I gotta hop on a quick virtual drs call so there may be a delay in my responses but I am still here
I am not sure they would like a rotation of responsibility
Would you like me to pose it as you being the manager of it? I originally went for a single leader, and when I had it reviewed it got brought up as a potential issue for if that individual leader is out
me and Mcfadden, then there are 2. less likely for both to be out
Done and Dustin
there is line 3 of paragraph 2 in introduction that also says rotation
The other comment is to focus more on containers (docker) than vms if possible. i like your references. could we find something that recommends minimum hardware (32gb, etc...)?
everyone is putting them in the integrations drive/campaigns/completed mappings
Good morning! For 602- looks like acts-dl-flatirons... I sent that to you earlier direct because there was some oddness in it that needed to be tested, but lemme grab that~
I can make those changees for 32gigs now

Ah yeah that was the one I sent you earlier- it was done prior to there being a written process so it just exists as the actual mapping
Went ahead and converted it over
{\"Error:\":\"Nullable object must have a value.\"}
{\"Error:\":\"Index was outside the bounds of the array.\"}
[
{
"contactid": 531752,
"leadid": 603431,
"casetypeid": 602,
"storageurl": "https://console.cloud.google.com/storage/browser/shield-legal-602/531752/intake",
"externalid": "246615",
"intakeprocessedat": "2024-10-15 21:30:26.425367",
"secondaryprocessedat": null,
"intakeresponse": "
Run this in the vscode powershell terminal:
python -c "import sys;print(sys.executable)"
python -c "import json;f=open('definition.json', 'r+');d=json.load(f);f.seek(0);json.dump(d,f,indent=4)"
Push it to github and make a pull request. I will look at it there
https://documenter.getpostman.com/view/5921778/UVeJM5kQ#5459b434-513f-4e96-b3e9-721b07a9d5d1 PUT Update UDFs https://app.smartadvocate.com/CaseSyncAPI/case/udf
I would not call it a lunch and learn unless lunch is provided
https://www.bome.com/products/mtclassic


https://www.youtube.com/watch?v=4xDzrJKXOOY

https://www.youtube.com/watch?v=-ailhp8kRzE

Mark Mina <mmina@actslaw.com> Chloe Gelpieryn <cgelpieryn@actslaw.com>
I redid the Priority tab on the API Integrations Board. It only shows the status of "In Progress", "On Deck", "Backlog", "On Hold". And it sorts by "Priority" (High to Low) then "Target Date (Original)" (Oldest to Newest) then "Date Requested" (Oldest to Newest)
What are your thoughts on removing the following columns in the API Integrations Board: Automation Platform, Followers, Ticket, Request Notes, Date (At the very end)
I like the idea- my only concern would be if theres any MPA stuff left that's hiding in the cracks but since we are moving everything to GCP anyway..
I'm also building a process to prevent the "well I wasn't told to do that specifically.. "\


Process looks good. Lets implement for new campaigns
Add column for if campaign is open/closed

for sean kelly with bay point. It almost seems like he does not care about pfas and only the sexual abuse case. @Zekarias Haile has most of the mapping done but sean only asked for a connection test by end of last week (which we did). also we have other cases to integrate not just his. maybe we should loop in meghan?
requirements: • API Concurrency • API Page Limit • Need lead update date time and search by update time • Need to be able to keep our DB up to date with LR Trying to dump all lead data and keep up to date. Can use DB access.
Sure thing' any word back on that email?
> Thank you for the context. I'll review this information with upper management to determine how we can assist you with resources. I've also scheduled a call with our teams for tomorrow to discuss your needs and explore possible solutions.
I saw the new campaigns came in so I started working on a rudimentary mapping for Chowchilla Womens Prison Abuse - ACTS - Crump - Shield Legal
When you get some time can we update the progress column in Monday with the sub-items?
Also does the "Test Integration - 10/29" need to stay on the board?
Sure thing' Can you please throw that on there as a task for me?
I use the test integration for automation stuff- I would like to keep it there if we can so I don't keep spamming the chat with making new ones lol
Does this link work for you? |https://tortintakeprofessionals.monday.com/docs/7745372257

Can I get edit access to the dashboard?
Can we filter out the blocked status from the Workload Chart
edit access given, blocked/waiting has been removed from the workload chart
https://github.com/Nuitka/Nuitka May need joe to allow a c compiler, if we want to use it.
with our pipeline changing, we should probably do some digging on CCPA law, and GDPR law and build out our standards now rather than having to rebuild from scratch later https://www.youtube.com/watch?v=24Ki4Ck4Y2E

Is there a way to make a copy of these so I can work on the copies, fact check results and then move results over?
On the lead page Action Menu > Create a Copy. Use different contact, one that we use for testing, to prevent issues on live leads
Heyo- I want to create some test leads for that coding project, but I'm not seeing where to create new leads for an existing case on Lawruler
The "New Intake" button on the left side or you can clone from an existing the instructions: https://themedialaboratory.slack.com/archives/D07NEK10NTZ/p1730827498976749

cool- I think I was looking around in the wrong place


So just to confirm, we want to pull questions 25-31?
like we find the lead with the same ID and just move those fields over?
or we move the whole lead over to the new campaign?
The leads will have different lead ids but should have the same contact id. it is possible that we will have to match on name / phone / email when contact id does not match. We need to move the answers from Firefighting Foam MED - Nations - Levinson - Nations Q25-31 to Firefighting Foam - Nations - Levinson (TC) - Shield Legal Q71-77. It looks like some are already copied over, will need logic to check that.
Cool, thank you for the clarification! I appreciate it
Do you have any pre-existing code for similar cases I can look at to get an idea where to start? So far I made a test lead on one, but it looks like I'll have to make test leads on both to make sure it moves over correctly
This is what I have for talking to the API which about all i have: https://github.com/shield-legal/lawruler-ui/blob/main/func_fill_db/lawruler.py
*Thread Reply:* All good it's a place to start, thank you!
Do you know anything about the Milestone tracking tab that is now on all case types?
I do not- I was actually wondering about that myself.
Where does this tab exist? Is it a lawruler tab on the leads??
Yes, on the form page with all the questions
Hm- weird. I'm not familiar with it. I wonder if it got created by Aiden on the reporting team when he was editing fields for that Flatiron fire the other day
Let me know if you end up figuring it out
So I'm looking over the lawruler API docs and I'm running into some issues.. What I was thinking was..
- Pull a list of all Lead IDs and Contact IDs from campaign A..
Do the same for campaign B.
Pull all of the Question and Answers from each lead with a for loop and store that info in a dictionary.. (One dictionary per campaign, like campaignafulldict and campaignbfulldict)
Go through the dictionary for campaign B and find all leads missing values for questions 71-77
Make a list of those Lead IDs.. campaignbmissingvalueslist
Use that list to Run some kind of logic to find the matches between Campaign A and B on name/phone/email, and make that into a json file or a dictionary, not sure which would work best..
Now that I know what lead IDs are associated with eachother, and I have all the information I need stored in dictionaries, I should in theory be able to tell it to refer to the key in campaignafulldict and move that information to campaignbfulldict
but I'm not seeing a way on the api to..
- Pull all lead info from case like that.
- Once I have a fully set up campaign B with the right info, upload it so only the missing pieces go in without it canceling out because of duplicates
What are your thoughts? Would there be a better way to approach this?
- ApiCases/SearchInboxItems with CaseTypes filter:
lr.search_inbox(filters={'CaseTypes':[IDs for cases to search]}) - ApiIntakeForms/SetAnswer: https://apim.lawruler.com/tortintakeprofessionals/swagger/ui/index#!/ApiIntakeForms/ApiIntakeForms_SetAnswer I would do:
- SearchInbox for both case types
- Filter into a list per case_type
{'case1': [leads], 'case2': [leads]} - Build dict for contact id to leads
{'contact': [lead from case1, lead from case2]}a. At the same time build list of leads that do not match - For the list of leads that do not match by contact id try matching by name / phone / email and add to dict in step 3
- For each contact get answers from lead (case2) to post to
- Check if need to update / push those answers a. If need to update / push get answers from lead to pull from (case1) b. Push using ApiIntakeForms/SetAnswer
This is cool- I haven't seen this swagger thing before- what is this?
swagger is 1 of the tools to make API docs more readable
.env LRAPISECRET="3RsxCggviuYBdBZQ15DT1faJFOPRJLMG"
Is there any kind of save state or rollback for campaigns? I just dont wanna break something I can't fix
so how have we tested things historically?
can we make copies of whole campaigns with all the leads?
Test leads. I do not think there is a way. But the changes might get logged in the activity log
Alrighty- I'ma try and figure out how to mod what I set up to work with individual leads so i can test but for now i'ma take lunch
Can you please look this over for me? I'm trying to test my functions independently and getting a 404 error for the url- I'm thinking I set it up wrong but I'm not sure how
in training will look afterwards
Ended up figuring at least part of the issue out.. I was using "case_type" in my params instead of leadId and I was using the name instead of the number..
I gotta build out the env file but I think i got quite a bit knocked out on it today
Is there a reason you did not use the lawruler.py I linked too?
I added a few comments marked by # TODO
Here are our case ids, case type names, acts case types. Please ask ACTS to verify: 363 | Chowchilla Abuse - ACTS - Laba Forman - Shield Legal | Sexual Abuse Chowchilla 402 | Rosemead High School Abuse - ACTS - Shield Legal | School 621 | Personal Injury - ACTS - SIL - ACTS | Pre-Lit PI Lead Docket 623 | Property Damage - ACTS - SIL - ACTS | Property Damage - Residential 626 | Construction Defect - ACTS - SIL - ACTS | Construction Defect 1670 | Birth Injury - ACTS - SIL - ACTS | Birth Injury 1686 | LA Juvenile Hall Abuse TV - ACTS - DLFlatirons - Shield Legal | Juvenile Detention 1766 | Chowchilla Womens Prison Abuse - ACTS - Levinson (TC) (TIP) - Shield Legal | Sexual Abuse Chowchilla 1767 | Chowchilla Womens Prison Abuse - ACTS - DicelloFlatirons (TIP) - Shield Legal | Sexual Abuse Chowchilla 1768 | Chowchilla - ACTS - Levinson (TC) - Long Form Interview | Sexual Abuse Chowchilla
Sry didn't mean to get pulled away- just briefly wanted to show what I made on miro
https://www.youtube.com/watch?v=H7YzrfgOcUc

working on some stuff and I'm trying to figure out- for our new systems
will we have a separation of data lake and data warehouse?
Just in case you are wondering what I mean

I assume Ryan will want a Data Warehouse but we will need a Data Lake before the Warehouse to process things. So a combination?
I agree, It makes sense for us to have both, especially because of the kind of data and different places it's going
I'm setting up a basic pipeline blueprint right now, I think this should help in the future-
What is the current proposed method of getting the info from lawruler to GCP
Cool- and outside of the main.py we don't transform or process the data in any other way?


The API that triggers python is currently email automation from lr not manual
How much do you know about Tips financial Data pipelines??
Trying to fact check myself and get an idea what's going on

I did not know that the finance stuff used cloud storage
I think it's currently using AWS but the plan is to move it all to GCP
It is better to have you data in 1 place then spread across many, in terms of permissions and access.
but that 1 place better have redundacy
I'm trying to figure out what ryans vision is first before I say it's wrong lol
Im not sure anyone knows ryans vision besides ryan
Meeting with ryan is almost 2 hours over. I gotta meet with my team once I get out of this
Good morning- if you would, Please remove me from the integrations@gmail.com ^-^
It will be done today, I want to show @Nicholas McFadden how to do it as well.
Seriously good job on the getting data over btw
Do you think some of the tasks assigned to you in the integrations task board can be marked done?
Hey there, can you give me a quick rundown of what the matter meeting is for?
I see DicelloLevitt on there, not sure if it's a carry over from being on int
Darrell and Abe talking about the integration with DL's system Litify (Salesforce)
possibly a carryover, if Darrell does not realize you changed teams.
I'm limping through this query that should be dummy simple in python, but I'm trying to get it to work in DBT or Bigquery..
If you can yeah.
I am trying to build a new table with
lrdatasourcecasetype AS ( SELECT
id AS casetypeid,
name AS case_name
FROM <a href="http://tort-intake-professionals.lr">tort-intake-professionals.lr</a>_data.case_type
simple enough - then I am trying to get each unique value within the case status column in tort-intake-professionals.lrdata.leadstatus`
For each unique value, that should be a new column in the new table..
However, DBT is being a pain in the butt because it doesn't want to support any kind of dyanmic queries from what I'm seeing
and I could in theory run it in bigquery, because Bigquery supports pivot, but bigquerys pivot requires all pivoted columns be specified
I could go through the hastle of trying to figure out dynamic sql in bigquery, but even if I do- I still need to ultimately get this running in dbt so I can make it automated without costing out the wazoo
what value goes in the status columns?
0s for now, but the plan is to import the table into re-tool and build a gui so that tony, ryan and them can easily update how many points each status change is worth per campaign
that way they can update the table, and i can refer a looker dashboard to throw up on the big tvs so people know how much things are worth
There are 113 statuses in the db. sure you dont want to filter that?
Ideally I want to build a table that shows all of the status's and if they are commissionable, billable, ect- and pull from that
Ryan actually tasked me with that as well, but he never sent me the meeting notes on what tables to pull that data from
and I haven't been able to get ahold of him today
I feel like this should be a table with the columns: casetypeid, statusid, points Then you join with casetype and lead_status to convert to names. This allows for the most flexability and expandability
That's a good idea- but one case can have multiple statues each worth a different amount, and it goes as far as different departments could get different point values and commission amounts for the same status on the same case
I guess this comes back to making that billable/commissionable status table first.. huh
True, but wouldn't it need to be a new column for each department, and the points would just go there?
for dbs think in terms of rows not columns
ah gotcha, so we just double up rows where needed- like for each case_type, it can have a whole bunch of rows, one for each variable of commissionable status and department
My concern there is if there end up being 30 commissionable status's, and 5 departments, you're going to have 150 rows for each case type..
rows are cheap and easy. columns are hard
Yeah this could work because it should never have to be manually looked through anyway..
and you can even add a commission value column and not have to change anything else..
Cam and Co inbound to check out the new integrations area!
Hey we're we ever able to get the questions imported?
I believe the GCP Integrations is exempt from the API pause
Maybe that should be a Monday Form or a Google Form?
I don't forsee a reason people wouldn't be able to type it out in a word file and send it over to us. The little bit of extra effort it takes will be a good thing because it keeps people thinking about what they actually need vs just spamming requests.
Technically still Brittany
on paper I am still a regular data engineer like everyone else on your team
Early meetings with Ryan so I'll be taking them from home and coming in a little later
Heyo~ I was tasked with coming up with a new naming convention for case types in Lawruler and I have my idea fleshed out. I wanna run it by you before I start working on it so data end can be ready
Lemme know when you're available
I'm trying to get a definitive count of the compaigns in lawruler so I can fact check my data and I'm running into some issues maybe you could clear me up on..
your lrdata.casetype shows 804 campaigns.. Ryans lrcasetypes from fivetran shows 807 The highest lawruler id is over 1900-
Do you know what you are filtering out??
Not filtering out. New campaigns not in the db. The db has not been updated since the night of Jan 6. I just learned that lr added some reatelimits. Will be implementing that to the the db dump but it will be hobbled
7 days shouldn't be a difference of 1100 campaigns though
Do you know if the LR ids don't actually mean what they are led to mean?
that would be diff of 3. between me and ryan
i think at some point some case types were deleted which is the only thing that makes sense in my head for the numbers to be close to 2k but the count be <1k
and that makes sense- I know there is a "deactivated" option so I thought people were doing that but theres only like 60 or so deactivated
Heyo~ have you connected to the gcp console via python before? Looking to set it up myself and I am not sure which service account we should be using
I use my account until it gets pushed to a function. If you use the application default credentials a lot of the auth and config is done for you
Most services have different ways to connect but they should all support the application default credentials.
Have you had issues with creating Venv since the updates?
Our pcs randomly turning off and back on on Friday
No, I created one with PyCharm Friday afternoon just fine
Interesting. Okay.. mine is all failing, and when I go to check the pip version in my old vens they show up, and can even update, but when I go to do anything in a new venv is says it fails to create it, it shows up in my file explorer , but I can't pip install anything and it when I pip version, it supposedly doesn't exist.
If you wanna swing by and take a look I would appreciate!
<https://cloud.google.com/docs/authentication/set-up-adc-local-dev-environment>
Hey what is your phone number again? For some reason my gmail isn't syncing
Hey there, what is the sql to generate this view? I see it hasn't been updated since January 30th so I want to set up a scheduled query

At the bottom of the details tab but views do not update only the data they pull from which for that view is pctiddata.leadstatustrackermaterialized, lrdata.leadquestion, lrdata.casequestion
newest lead in leadstatustracker_materialized is from 2 hours ago
If that code is in the Shield-Legal-BI Github org, I am not in that org
I'm not sure, you may need to ask Mcfadden directly

Might be able to just schedule the report in Five9, and set it to FTP direct??
https://cloud.google.com/integration-connectors/docs/connectors/ftp/configure
Just gotta figure out that pipeline info

The 2 leadspedia tables are updating every 30 minutes and takes about 8ish minutes
REPORTNAME = "Five9Bulkcalldata1" FOLDER_NAME = "My Reports"
REPORTNAME = Five9Bulkcalldata FOLDER_NAME = Shared Reports (Tort Intake Professionals)
<soapenv:Header>
<adm:Authentication>
<adm:user>{self.username}</adm:user>
<adm:password>{self.password}</adm:password>
</adm:Authentication>
</soapenv:Header>
https://documentation.five9.com/bundle/assets/page/assets/admin-pdfs.htm
Hey there, what is the refresh rate on this data?

leadspedia allleads and allsold_leads are 30 minutes
FYI: the five9 config webservices api is soap
Also, on the half hour mark or another time?
on the half hour and hour (takes about 7 minutes)
https://us8.five9.com/reporting/runReport.jsp?Id=_281&type=CustomReports Here is the report for testing btw
This is the error I am currently running into, trying to work with Christian to get the permissions fixed. I can push the code to GitHub so you can try it if you want

I wonder if we have different permissions
The changes have been pushed. Adjust the comments at the bottom of five9_recordings.py
I'll check it out tomorrow AM
Hey did you fact check to see if the leadspediaallsold_leads was coming in right after you updated it?
There's only 42,572 leads in there now, there was like 500k+ before
And theres only 53k leads on leadspediaallleads, there used to be over 800k with Mcfaddens code
it was hitting the gcp memory limit. i have doubled the memory limit. it will run again in 3 minutes
Cool thank you- a whole bunch of my stuff was showing incorrect data and I was like "what the.."
When should I expect to see the rest of the leads populate again?

Is there any way we can roll back the code temporarily to get a snapshot of what it's at now?
allleads is now up to date. updating allsold_leads. The code uses ~4GB of RAM which GCP does not like, will need to change it to upload in chunks to prevent RAM overload, or only look back and update a couple of days worth instead of all time
I have paused the GCP automation for now while we fix this
I appreciate you digging back into it- thank you!
For clarification, did you just pull the allleads, or the allsold_leads as well?
Just all leads. I was trying to do all sold leads as well but it errored and i have not had a chance to look into yet
the error for all sold leads was exceeded api rate limit
would putting it in PostgreSQL and viewing to BQ solve that?
no, the api rate limit was leadspedia. although doing postgres would solve the ram issue. (I can also give the cloud function more ram but then it would cost more)
all sold leads is now updated. I have given the function more ram and uploaded the fix. it took 22 minutes for just all sold leads so i changed the trigger to every hour on the hour instead of every half hour
I have turned back on the automation trigger. I will check the logs tonight to see if it takes over an hour, but we really should convert it to only checking the last few days of data instead of all time (easier to do when pushing into postgres)
The five9 report does not have an unique identifier. sessionid and callid are the same when the call is transfered
On the plus side, I may have found a way to make the import to postgres faster
the leadspedia automation for all leads and all sold leads is verified working. it is taking 39 minutes to run every hour
What was the issue with it? 39 minutes every hour seems like a lot
It is pull all the data for the last few years everytime it runs
Postgres (62ms, ~0.062s):
SELECT ** FROM lr_data.lead_history WHERE date >= now() - interval '11 hours' and comment like '%Send to Five9' ORDER BY date
BiqQuery (2.5s):
SELECT ** FROM tort-intake-professionals.lr_data.lead_history WHERE date >= DATETIME_SUB(CURRENT_DATETIME(), interval 11 hour) and comment like '%Send to Five9' ORDER BY date;
let me know when your meeting is over. I want to show you something cool
Sorry just got out of the meeting. Can you show me tomorrow if that's okay? I gotta get somwhere by 5
https://github.com/gristlabs/grist-core https://www.getgrist.com/
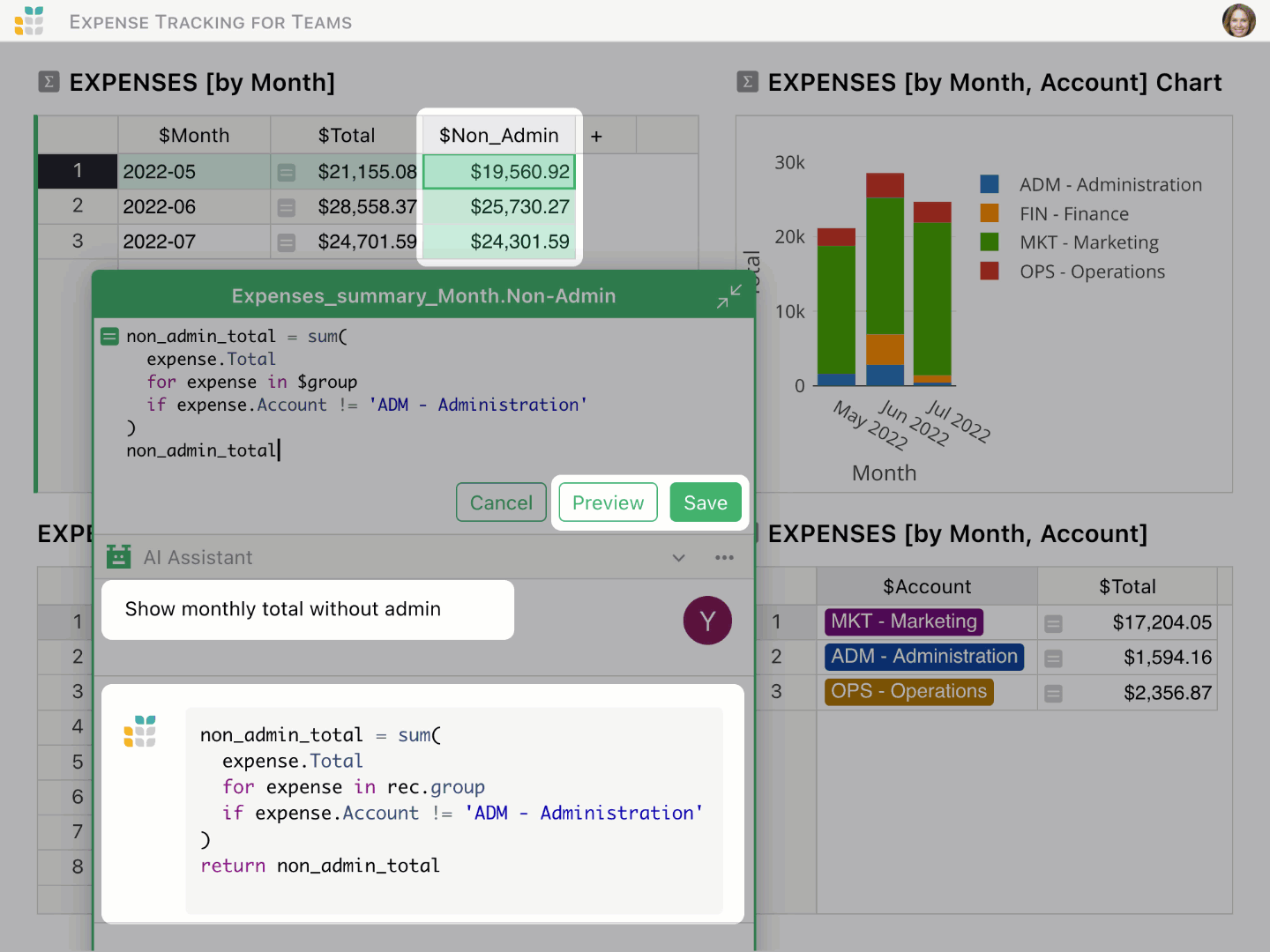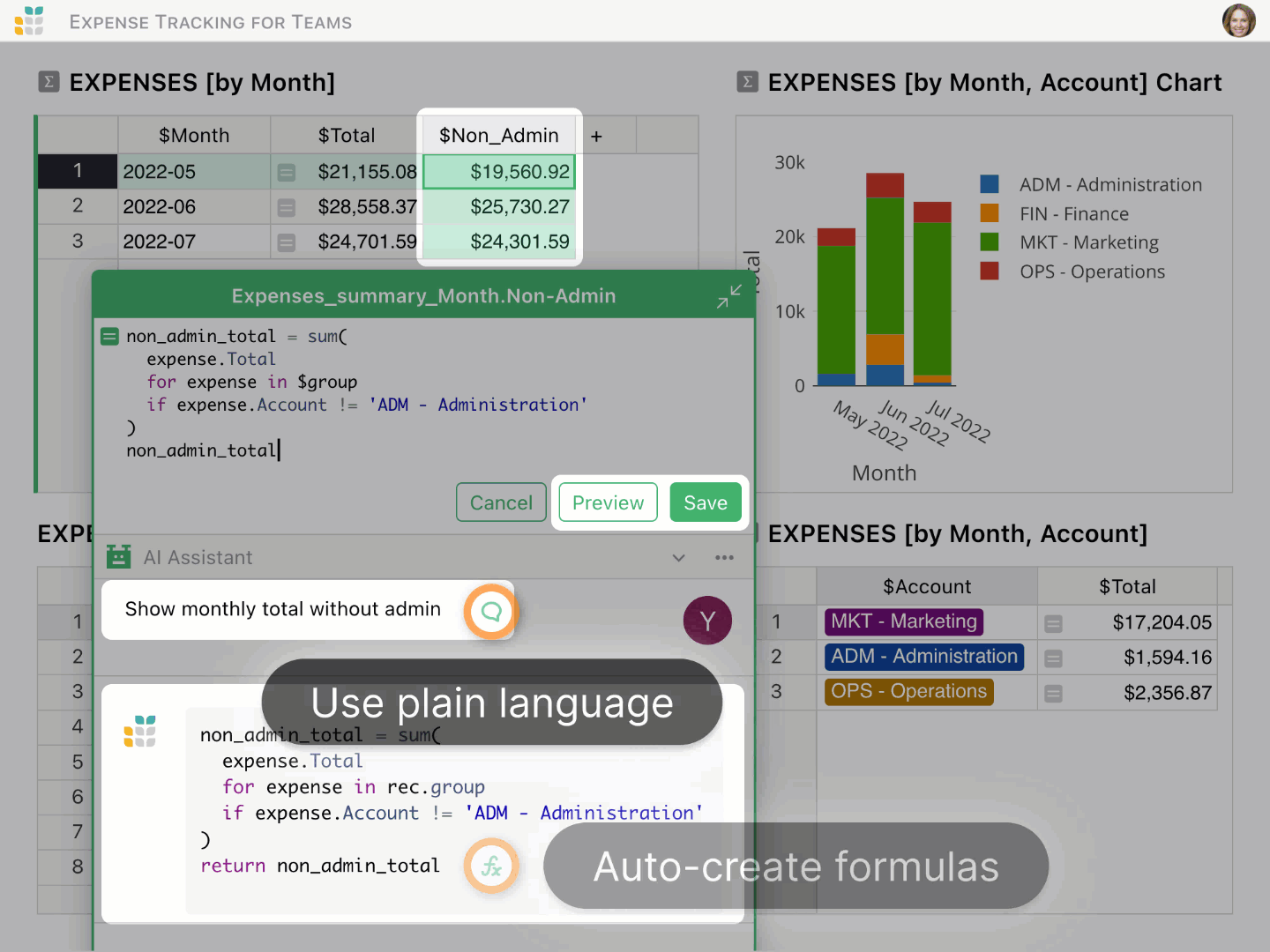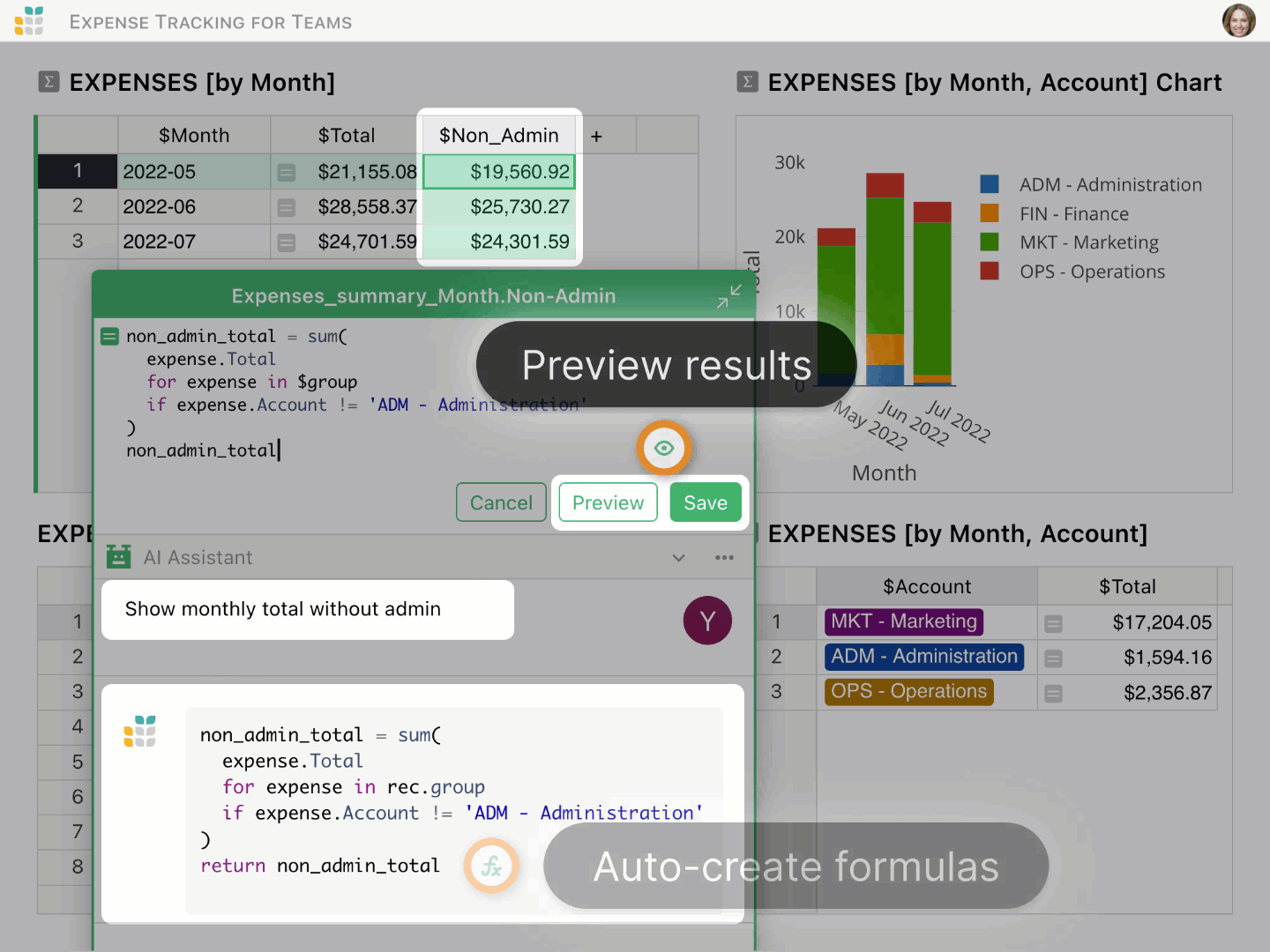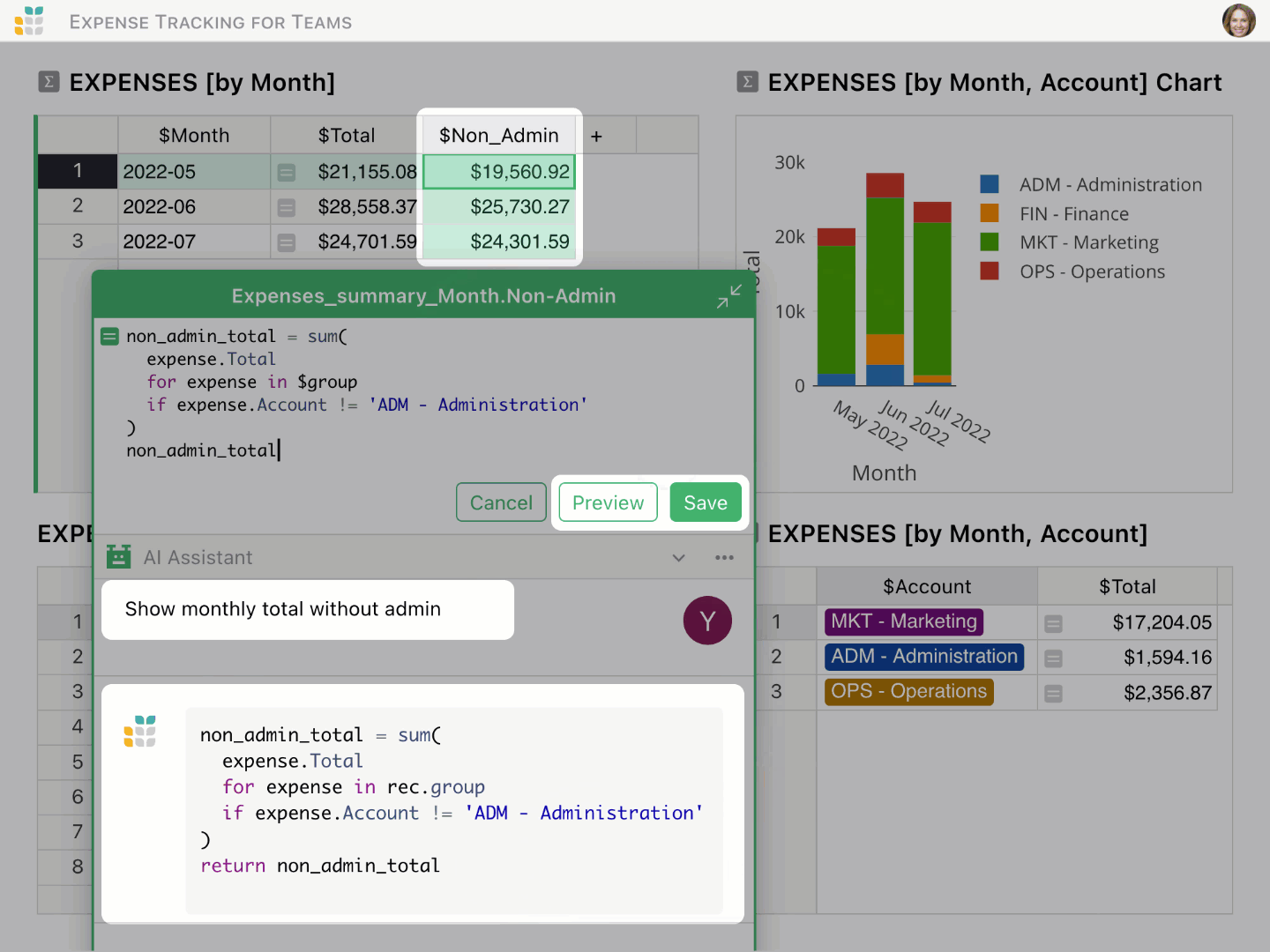
Is there a way to see the history of every query that touched a table in postgresql?
I see the query history tab, but ryan claims that's only personal doesn't know all queries
Both bq and postgres should have logs
Do you know how to access those in Postgresql? I would play around with it myself but don't have access to any and don't recall how to get into Lr_data
logs for lr-data: https://console.cloud.google.com/logs/query;query=resource.type%3D%22cloudsqldatabase%22%0Aresource.labels.databaseid%3D%22tort-intake-professionals:lrdata%22%0Aresource.labels.region%3D%22uswest4%22;cursorTimestamp=20250305T23:46:07.957600Z;startTime=20250303T23:48:31.053Z;endTime=20250305T23:48:31.053Z?project=tortintakeprofessionals|https://console.cloud.google.com/logs/query;query=resource.type%3D%22cloudsql_database%22[…]25-03-05T23:48:31.053Z?project=tort-intake-professionals anything in particular i can filter it down to?
I understand lawruler is down now, but how far along did we get on the activity status log table?
now that is down, I can run my script to populate it from the activity log table
If we can, that would be awesome. If you send me what the details of it are going to be in BQ, along with the schema, then I can start building on my end, even if I cant fully flesh it out

historical status table up to date with 1,641,311 rows
Duplicate call_ids are failed transfers according to @deleted-U062D2YJ15Y listening to the recordings
SUM(call time columns)
FROM five9_source.five9_bulk_call_data_tabularv2 f9
GROUP BY f9.date, f9.skill, f9.campaign, f9.calltype
ORDER BY f9.date DESC, f9.skill ASC, f9.campaign ASC, f9.calltype ASC
ALTER DEFAULT PRIVILEGES IN SCHEMA five9 GRANT SELECT ON TABLES TO reporting;
ALTER DEFAULT PRIVILEGES IN SCHEMA five9 GRANT SELECT ON TABLES TO ops;
ALTER DEFAULT PRIVILEGES IN SCHEMA five9 GRANT SELECT ON TABLES TO integrations;
ALTER DEFAULT PRIVILEGES IN SCHEMA five9 GRANT SELECT ON TABLES TO postgres;
ALTER DEFAULT PRIVILEGES IN SCHEMA five9 GRANT SELECT, INSERT, UPDATE, DELETE ON TABLES TO "144747688343-compute@developer";
ALTER DEFAULT PRIVILEGES IN SCHEMA five9 GRANT SELECT ON TABLES TO "service-144747688343@gcp-sa-bigqueryconnection.iam";
CREATE OR REPLACE VIEW five9.inbound_summary_per_hour AS
SELECT agent,
date_and_hour,
EXTRACT(EPOCH FROM SUM(call_time)) AS call_time_total,
EXTRACT(EPOCH FROM SUM(bill_time__rounded_)) AS bill_time_total,
SUM(calls) AS call_count_per_hour
FROM five9.five9_bulk_call_data_tabularv2
WHERE call_type = 'Inbound'
GROUP BY date_and_hour, agent
ORDER BY date_and_hour DESC, agent
Might need to drop and re-create because the columns changed from interval to int
Does the lr status change table change it to utc?
Check out the Page-3 tab in https://drive.google.com/file/d/1o-6-eOAA80iEJ_MhhObt5bBpK9zEXu2p/view?usp=drive_link
tort-intake-professionals.FinancialLogDataset tort-intake-professionals.five9measures tort-intake-professionals.five9source tort-intake-professionals.lrdata tort-intake-professionals.thecorner tort-intake-professionals.tipprodapplication
FORMAT_DATETIME(
'%M:%S',
DATETIME(
1970, 1, 1, 0,
CAST(duration / 60 AS INT64),
duration - CAST(duration / 60 AS INT64) ** 60
)
)
abari jabari1mcdonnell@gmail.com 7025730973
3/26/25
Kathleen Tort Intake Professionals 5170 Badura Ave Las Vegas, NV 89169
Subject: My Glorious Exit from the Circus
Dear Kathleen,
After much thought (and a lot of deep sighing), I have decided to formally resign from my position at Tort Intake Professionals, effective 3/28/25.
Working here has been an experience one that has sharpened my ability to navigate undocumented policies, endure impromptu photo ops without consent, and master the art of receiving feedback via office gossip instead of direct coaching. I have had the privilege of operating in an environment where veteran employees treat mistakes like career opportunities (for them, not the person who made the mistake), and where competition is less about performance and more about who's dealt the better hand in the bad-lead lottery.
Management proudly touts an open-door policy, but in reality, it's more of an open-floor policy where employee performance, concerns, and careers are openly dissected right in the middle of the office for maximum public entertainment. Why waste time on professional one-on-one conversations when you can broadcast critiques like a live workplace drama? The level of unprofessionalism is truly groundbreaking.
I have often heard the phrase, maybe this isn't the right place for you thrown around as a catch-all excuse for why things never improve. It's a convenient way to dismiss real concerns without accountability, as if the problem is that employees just don't fit in rather than the reality that the culture thrives on inconsistency, favoritism, and blurred ethical lines. If the right fit means accepting workplace gossip as professional communication, competing on an uneven playing field, and pretending that lack of documentation is a feature, not a bug then you're absolutely right. This isn't the place for me.
And let's talk about competition for a moment. True competition drives people to be better, to push themselves and their peers toward excellence in a way that benefits the entire team. It's built on skill, innovation, and hard work not on tearing others down just to get a step ahead. But what thrives here is not competition it's a 1994 crabs-in-a-bucket mentality, where the moment someone tries to climb higher, others scramble to pull them back down. Instead of fostering growth, this culture rewards those who sabotage, backstab, or manipulate their way to the top. That's not competition; that's survival at the expense of progress. And frankly, I have no interest in playing that game.
And speaking of things that should be done professionally, documentation. Or, in this case, the complete and utter absence of it. Any well-run business knows that communication between employees and management should be documented not just for clarity, but to prevent the inevitable game of corporate telephone where today's verbal agreement turns into tomorrow's I never said that. Yet here, conversations vanish into thin air faster than accountability at a leadership meeting. No records, no paper trail, just a whole lot of I don't recall saying that. It's truly a marvel how policy can shift depending on what's asking, what mood management is in, and whether Mercury is in retrograde.
Now, credit where credit is due: the pay has been solid. It's just a shame that financial compensation was the only consistent thing about this job. The real prize has been the invaluable lesson that success in some workplaces isn't about skill or integrity it's about how well you can navigate chaos with a forced smile.
So, I'll take my skills (and my sanity) elsewhere, but I do wish the best to my former coworkers especially the ones who actually believe in teamwork and not just survival of the fittest. To everyone else, may your next clandestine hallway gossip session be as productive as the coaching meetings we never had.
Sincerely (and finally, freely), Jabari
Hey there, I am attempting to set up Bigquery in Pycharm and set it up with the "New" button on the database tab, I initally tried to set it up as a google service account but got that no permissions error.
Attempted to set it up by going through google user account as authentication instead and it tested successful but it's super slow..
Like I've been waiting for it to load the tables schema for a hot minute.


How does this work without a key? It just checks if you're logged in locally?
the gcloud cli saves your creds on your device then the application default credentials uses that
Does anything need to be imitated first locally? Sorry for potentially silly questions

Well nevermind- It refused to connect and then started working on pycharm
``` 704865 IL YTC Abuse - SGGH - GLF - Shield Legal Potential issue with LR_data 3/27/2025 19:53
704349 NJ Juvenile Hall Abuse - BG - Bowersox - Shield Legal Potential issue with LR_data 3/27/2025 19:02```
No issue I can find with db for 704865
704349 has more than 1k activity log entries. LR will only give me the latest 1k. The other statuses are before all the question updates which is what generated those entries
I only have 1015 of 1877 activity log entries for 704349 because of LR
We can manually enter the status updates that you require

In the new con competition and non solicitation agreement
Inventions and Original Works.
(a) Assignment of Inventions . Employee agrees that Employee will promptly make full written disclosure to the Company, will hold in trust for the sole right and benefit of the Company or the Affiliates, and hereby assign to the Company or an Affiliate(s), or their designee, all Employee's right, title and interest in and to any and all inventions, original works of authorship, developments, concepts, improvements, designs, discoveries, ideas, trademarks or trade secrets, whether or not patentable or registrable under copyright or similar laws, which Employee may solely or jointly conceive or develop or reduce to pr actice, or cause to be conceived or developed or reduced to practice, during the period of time Employee is in the employ of the Company, Affiliates or any of them (collectively referred to as "Inventions"), except as provided below, Employee further acknowledges that all original works of authorship which are made by Employee (solely or jointly with others) within the scope of and during the period of employment with the Company and which are protectable by copyright are "works made for hire," as that term is defined in the United States Copyright Act. Employee understands and agrees that the decision whether or not to commercialize or market any Invention developed by Employee solely or jointly with others is within the Company's sole and absolute discretion and for the Company's sole benefit and that no royalty will be due to Employee as a result of the Company's efforts or non-efforts to commercialize or market any such Invention.
6
(b) Maintenance of Records. Employee agrees to keep and maintain adequate and current written records of all Inventions made by Employee (solely or jointly with others) during the term of employment with the Company. The records will be in the form of notes, sketches, drawings, and any other format that may be specified by the Company or the Affiliates or any of them. The records will be available to and remain the sole property of the Company at all times.
(c) Patent and Copyright Registrations . Employee agrees to assist the Company, Affiliates or any of them or their designee, at the Company's expense, in every proper way to secure, protect and/or transfer the Company's or Affiliate's rights in the Inventions and any copyrights, patents, mass work rights or other intellectual property rights relating thereto in any and all countries, including the disclosure to the Company or the Affiliates of all pertinent information and data with respect thereto, the execution of all applications, specifications, oaths, assignments, licenses, and all other instruments which the Company or the Affiliates shall deem necessary in order to apply for and obtain such rights and in order to assign and convey to the Company or an Affiliate(s), their successors, assigns, customers, purchasers and nominees the sole and exclusive rights, title and interest in and to such Inventions, and any copyrights, patents, mask work rights or other intellectual property rights relating thereto. Employee further agrees that Employee's obligation to execute or cause to be executed, when it is in Employee's power to do so, any such instrument or papers shall continue after the termination of this Agreement. If the Company or the Affiliates are unable because of Employee's mental or physi cal incapacity or for any other reason to secure Employee's signature to apply for or to pursue any application for any United States or foreign patents or copyright registrations covering Inventions or original works of authorship assigned to the Company or the Affiliates as above, then Employee hereby irrevocably designates and appoints the Company or the Affiliates and its duly authorized officers and agents as Employees agent and attorney in fact, to act for and in Employee's behalf and stead to execute and file any such applications and to do all other lawfully permitted acts to further the prosecution and issuance of letters patent or copyright registrations thereon with the same legal force and effect as if executed by Employee.
Question for ya:
What did I do wrong, and how can I fix it?
Explanation: The scope of this project grew past what I initially named my directory, so before manually changing my directory name and all code routes inside, I looked up to see if Pycharm had a tool for that. I saw it has a refactor ability when you rename a directory. I made a branch for safety, renamed my directory from Finlog_validation to NewFin and saw that it missed part of my python code. I changed it manually, and saved but now when I run the newly saved file, I get this error.

Wait, I think I might of actually figured it out..
The run configs next to the play button in the top right
I didn't realize it was holding onto a old thing here

Changed that to current file and it seems to work now
It does that because you can change settings per file you run and run multiple files at the same time
Now will this cause issues with the git?
Cool, and follow up Q: After the refactor I saw some oddness with my Venv that I was able to resolve, but it got me thinking. Should I be adding the Venv to the Git in case people are running different versions of python??
No. but you should add a requirements.txt with the libraries and their versions that you use.
There are better ways but I am not familiar with them
Cool- I'll dig in on it when I get the chance
The better ways require tools or libraries whereas the requirements.txt is built in to python. Here is an example: https://github.com/shield-legal/dialers/blob/main/requirements.txt
you can generate it with pip freeze > requirements.txt but it will include every library that is installed. I like to only save the libraries I need not the libraries that they need.
Hey is there any known issues with the Lawruler extract? I don't have any leads after 11:36am yesterday

I apparently did break it. I though my changes were fine. Thanks for catching it. I believe I have fixed the problem. It will probably take 1-2 hours to backfill
No worries, Postgres and Pycharm made it an easy check lol
I saw 15 leads in my billable status table for yesterday and went "uh-oh"
Thankfully today is a "get everything together from March" day
2728 leads to update. After 100, ETA for the rest is 1:41:00
The DB is working on the site: https://shieldlegal.dev/
You can also tell the results window to run the query on a timer
Working in Pycharm/postgres feels so much more like actual engineering work than working out of BQ

Didn't you mention that there was a discount code that we will need? Also how will we pay?
GCNEXT25 is the discount code, and Ryan will be sending over the CC info
I recommend filling this out until you get to the payment spot, and I'll send you the payment info once ryan gets it to me https://cloud.withgoogle.com/next/25/plan-your-trip#tickets

Should we register with our personal accounts but add the work email under business email? or only use the business email for both?
Clicked my shield Legal one like 4 times and nothing happened. Closed it, opened back up, and got that



Same thing going from browser https://shieldlegal.dev/

fixed it. there were 3 small problems

Interesting article- I'ma save that site for the future..
BTW, I know I'm making some silly mistake.
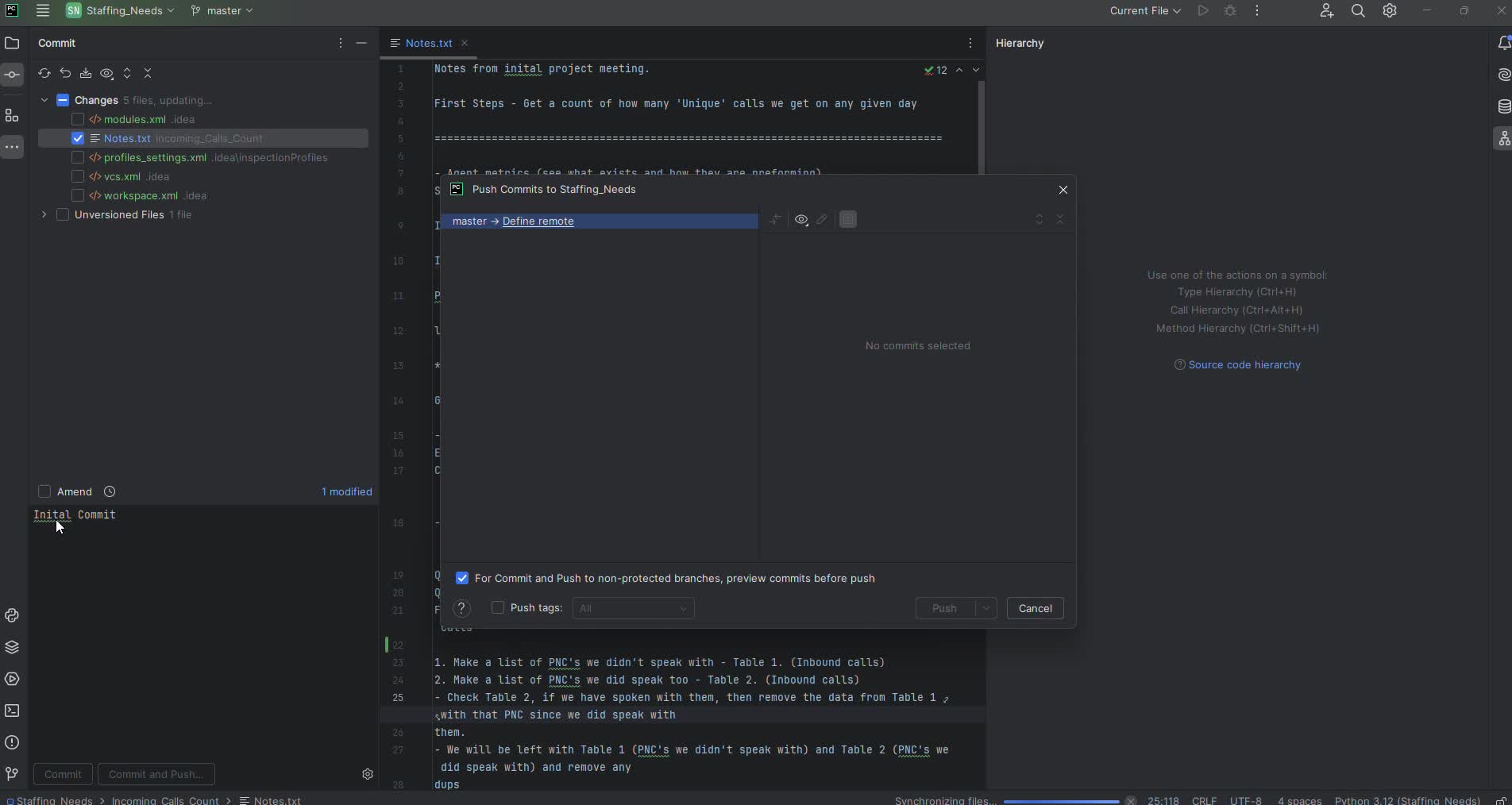
But I'm not sure where. My best guess is the link I'm grabbing

apparently I have not fully fixed the problems when LR reboots. It got stuck at 9:11 PM 4/5. It will start fixing at noon
Interesting. The latest I'm seeing as far as billable Rets are April 5th 3:50pm


apparently I have not fully fixed the problems when LR reboots. It got stuck at 9:11 PM 4/5. It will start fixing at noon
That is not UTC that is PST. which means it was fine until 9 PM 4/5 (my mistake was not paying attention to date)
~2575 leads to update. will probably be about 2 hours

I want to move more of my work into python rather than sql so I setting up the bigquery connection and my service account I set up is just not doing the thing
Ward is in a meeting btw, otherwise I would say cmon over lol
No worries, I think I may have figured it out
Would you like me to share some of the IT/programming/SQL articles I read that are interesting and most of the time relevant?
https://www.pcgamer.com/hardware/if-you-thought-usb-naming-was-nonsense-allow-this-professional-furry-engineer-explain-the-total-nightmare-that-is-the-underlying-hardware-complexity-of-usb-c/ https://dev.to/code42cate/serverless-is-a-scam-5fc0 https://www.kdnuggets.com/sql-cte-vs-subquery-this-debate-aint-over-yet



https://dev.to/devnenyasha/if-youre-diving-into-devops-start-here-no-not-with-kubernetes-3gch

And do use it daily. Maybe replace windows
git bash was installed with git and lets you do some things
I would be down, but gaming makes that such a difficult sell
I am currently dual booting for that purpose (VR and FPS games)
Would it be possible to run linux on these machines? When I say possible I mean allowed and quick enough move over that it isn't going to halt things for weeks.
I can boot from a flashdrive without IT. but flash drives do not have the longevity. I also have external ssds. I can get one running to show you tomorrow
I would say for me it takes less than half a day to install linux, configure and install all the programs I need. For others it may take a couple of days
Maybe I'll set it up on my personal laptop or desktop first
I also have an older (like 3-4ish years) HP laptop that might be fun to full boot over
beware you may need ethernet. sometimes wifi drivers do not work at first
not gross to ethernet, I use it when I can\
gross to driver incompatibility. I have been having to fight that nonstop on my full AMD build and it's been annoying.
AMD is better on linux than Intel and NVidia
I'm not sure why but that makes sense to me subconsciously.
Maybe it's because AMD is a little more.. finnicky, but you get a better bang for buck
Is this sarcasm? I thought arch was generally unstable and you have to re-configure constantly.

It can be solid but you have to be careful. I suggest Debian or Fedora as the first distro to try
Heyo~ question for you when you get a chance..
Any idea why these 10 leads show up in lrdata.lead , but not lrdata.contact?


are those lead ids or contact ids? the id column in the contacts table maps the contactid in the leads table
Ah, that makes sense. Leadids. I spaced that. They show up on LRData, and are making their way into my billableleadsunique step, but aren't making their way through to the end of the newfin pipeline which is odd.
FYI: the five9 call report table has not updated since 5 PM April 28th
FYI: the five9 call report table has not updated since 5 PM April 28th
You should take a look at this tool: https://learn.microsoft.com/en-us/windows/powertoys/
It can installed without admin with winget install microsoft.powertoys

Its one of my standards to install on windows machines I use. I only a few functions but all of them are useful
i'm excited to play with it, but the installer won't launch lol
I can help in a few minutes after this meeting
no worries, I'm OOO today. I think it's just joes IT being Joes IT
did you use the winget command I gave?
No I missed that part of the message, lemme try
Looks like it's going through now. The Microsoft store version crashes out hard
I thought you would. I think I tried telling you about it before
Especially with my pc doing this constantly
And that is why having web search enabled is a bad idea but you can only turn it off using admin
I know how you feel about Bigquery (lol) but have you used their data canvas feature?
The AI aspect of is pretty trash but as a tool to view multiple table schemas and pipelines at once, and build out new pipelines
It's a bit laggy but I'm not sure if that's our machines
Heyo~ lr_data question, do we pull this section here?
That is where we declare if a lead is a inital lead vs referral and I need to be able to tag referral leads

lead_source holds the options and lead.sourceid is the selected option
Looks like they are stored in Pacific time in Lawruler

What do you think we should do? change all sources into UTC???
or say heck it and keep it all Pacific time?
Should probably change all but it will be a task. We will need to identify all columns using PST then update the DB (UPDATE query) and change the database dump code before it runs again
I'm trying to get it consistent across my end, but even just the things i've built, it's a nightmare trying to move it all over. Might be worth keeping it in PST if we can't get the full scope of what we are effecting but idk
All times in a DB should be UTC since daylight savings and timezones affect it if not
My subconscious was correct. Before I got back from lunch I got the thought that it was a GCP permissions issue. When I checked the logs, I was correct
I'm gonna make a Postgres server bc I wanna poke around in it and use it for a simple project to get my feet wet
What kind of cost are we looking at? I recall you saying it's a blanket cost rather than how BQ does it, but I'm seeing hourly pricing here

Is that like processor time an hour, or is that like, like.. 60 cents an hour all the time, meaning 460 bucks a month no matter what
Hey there, please remind me, where is marketingsource ( if it is a referal or not) held in lrdata?
https://www.cio.com/article/3979014/12-reasons-to-ignore-computer-science-degrees.html?amp=1

https://www.theregister.com/2025/05/09/37signals_cloud_repatriation_storage_savings/

https://blog.det.life/why-are-there-so-many-databases-87d334c5dce6


gcloud init
gcloud auth application-default login
Another small one: https://www.bitecode.dev/p/lies-damn-lies-and-feedback-on-arch
You left your water bottle near our whiteboard
Heads up looking to rename at least 1 of the 2 case types named Camp Lejeune - Dicello - Crump (TC) - BLX
DB dump just restarted since LR update at midnight. ETA for update is probably 1.5 hours
Does Five9 natively bring talk_time in as a datetime64 or did you use some sort of code to convert it? It seems odd that it does not live natively as a timedelta64
Gets CSV from five9 and converts timestamp column to datetime: https://github.com/shield-legal/dialers/blob/973bf5decca8b92ded82c0f2bea6f0fe3aad65ed/five9_reports.py#L40-L51 If table does not exist in Postgres import from json to pandas then replace types to match Postgres before creating table: https://github.com/shield-legal/dialers/blob/973bf5decca8b92ded82c0f2bea6f0fe3aad65ed/cloudpostgres.py#L89-L105
Once table is created manually go through to update column types. Postgres then handles the conversions for new (on insert) and old data (on column type update)
https://www.cnn.com/2025/05/14/us/triple-fatal-climbing-fall

https://dev.to/shayy/the-serverless-dream-is-dead-2945

I read that article, and I feel a little silly asking this but it keeps referring to 'state'
I understand state as the status of a variable
but that doesn't really make sense with what they are talking about
Hey I think something might of bugged out on the postgresql server.
I ran a query that normally takes like 2-3 minutes, and walked away, came back and it was still running at 40min. I canceled it but that's odd right???

I took the screenshot right before I sent it to you
Possible stuck in a db lock during the table update process. Will have to check logs to be sure and check if there are any other impacts. Try running it now and see if it is running normally
Did a very odd thing. It initially never reported it as finished, so I waited until 6 minutes and force ended it. After force ending it, it read as a success. I attempted to use the dataframe the results were set to be saved to, and Pycharm is saying it doesn't exist in the traceback error.
Checking my database services and it failed to cancel server side on the earlier one, despite reporting canceled on my jupyter notebook

Checking my database services and it failed to cancel server side on the earlier one, despite reporting canceled on my jupyter notebook
Restarting PC, hopefully that forces closed the connection
Can I get access to Paul's repo in the tip GitHub?

*Thread Reply:* haha Bump- it's been a hot minute since I saw that in forums and such
*Thread Reply:* thanks
Ward told Brittany & Paul they are not allowed to deploy code without my or McFadden's approval
Hey there, any known issues with the Lr_data extract? Cam is not seeing the notifications he should be seeing so I'm trying to get a quick backup system set up.
Not atm. Just pulled into office. Give 5 minutes to look
How we doing on getting LR-data to every half hour?
It was changed at 9:33am, just after I sent: https://themedialaboratory.slack.com/archives/C08UUCKAYKD/p1748881968616799
Oh I didn't realize it was gonna be that quick
I figured it would take code changes and testing
No, its controlled by cloud scheduler. Thats why I checked the metrics
> Open the view > make an edit > save view > save as > write the exact same table name and over-write will appear which updates the schema.

Also his code is not pythonic. it is structured as a c project...
That tool currently uses gcloud cli and google console permissions. That means it would not work for CSP. (that is why I spun up the website)
Thinking about it, part of the problem is the constant references to the past or other companies
https://peps.python.org/pep-0008/ https://google.github.io/styleguide/pyguide.html

Whats your opinion on rearranging slack so that shield people are external users to tort workspace and tort are external users to shield workspace instead of some people having accounts in both?
Honestly, it would be more trouble than it's worth
I think it makes sense, but with all the other stuff going on, doesn't make sense to do rn
What are you saying the masters that be cannot multi-task?
What are you saying the masters that be cannot multi-task?
It does seem like something we can do ourselves
Potentially? Might cause a lot of confusion for non technical people though. Also on a personal/selfish note I just don't want to change everything over
Any reason my global Data sources would disappear on PC restart??

Pycharm was being funky (Not updating data set that it should of) so I closed out all windows, restarted PC and now my whole pc is CHUGGING despite sitting at 18-20% cpu
Might just do a full shut down, and leave it off for a few minutes
shutdown is better than restart, (cold boot vs warm boot)
Weird. I full shutdown, left it down for 10 minutes, turned it back on and I'm sitting at 30-50% cpu usage idle
and my global database connections are wiped from all my projects

Looks like some of the files are hidden but was able to get it to it through powertoys helpfulness
Looks like some of the files are hidden but was able to get it to it through powertoys helpfulness
Thats the wrong path. try inserting C:\Users\James\AppData\Local\JetBrains into explorer
I navigated to that from where I got before

check the PyCharm2025.1/data-source folder. if empty replace with mine once pycharm is closed

I actually didn't even have a data-source file anymore
wrong folder. put in the folder without a space
Saved mine as a zip, deleted it out, copied yours into the file path. Gonna go for one more re-start and hopefully things pop
Saved mine as a zip, deleted it out, copied yours into the file path. Gonna go for one more re-start and hopefully things pop


try using file > manage ide settings > import settings and point it to this zip
Cool looks like that worked, just gotta go into properties on each one and change user / delete what I don't use
Think I got it for Bigquery- Trying to remember for Postgresql because I remember it was different..
Bro- why so long?? It seems to be all over the place. Sometimes takes a minute or 2, sometimes like 6??

https://www.bytebase.com/blog/features-i-wish-mysql-had-but-postgres-already-has/

https://www.blog4ems.com/p/being-an-engineering-manager-today-has-never-been-harder

https://blog.cloudflare.com/cloudflare-service-outage-june-12-2025/

https://dev.to/coingecko/scaling-postgresql-performance-with-table-partitioning-136o

I was right. The outages were related https://www.bleepingcomputer.com/news/technology/google-cloud-and-cloudflare-hit-by-widespread-service-outages/

https://dev.to/shayy/postgres-is-too-good-and-why-thats-actually-a-problem-4imc

Heyo- Let me know what you think of this so far: https://docs.google.com/document/d/14HsIL--xCIXrX-5LpgDLOTXcPYI_zysy0R5VFzxyoy8/edit?usp=sharing
So when are we flipping the db to utc?
Probably after we audit and document where everything is right now.
This came up because I was requested to build a data privacy and model governance policies for Sphere
Also I would list Python in the data transformation area with BQ, Postgres & DBT
Good call- Been staring at this too long lol


Lol working out of a military base pretty much
With walls made of 2x4 and plywood on the edge of salt flats
Stuck in a meeting, but feel free to start jackson thing w/o me
He already started, Me, McFadden and Brittany are in it
So it is hard to dump the image I have of what the program should look like into words

Nice- According to Jackson the part that takes awhile isn't the checking or lawruler stuff, it's the call recordings
Did you look into what I shared for call recording transcripts by any chance?
Did you look into what I shared for call recording transcripts by any chance?
I am leaving the transcripts to @Nicholas McFadden

Makes sense- He communicated that to me, I should of passed that on.
Not to make more work, but I'm surprised HIPPA is not mentioned
in your data standards and policies doc
I have a meeting with Tim in legal tomorrow to go over any extra legal stuff
but we have documents that people sign that cover Hippa stuff
I wanted to go GGWP policies, which would cover everything but was told that would be overkill
I wanted to go GGWP policies, which would cover everything but was told that would be overkill
I'm having a hard time trying to figure out RBAC because we have no roles to begin with
So I'm thinking of making permission sets, and each user can have multiple permission sets assigned to them
Ill make you admin in site so you can see what I have setup
permissions assigned. I have roles which can be assigned to users or groups. pemissions are put on the roles
I think the comments in the permissions tab is funcky
https://userjot.com/blog/postgres-jsonb-vs-mongodb/

Excited to blab with you about how your week in the desert went

Btw, I left in the bit about the weekend to see who actually read it.
Removed should, and forgot to add must there. Thank yu
Lol I knew you would, you read the emails
Also wondered about it since you set the deadline as wednesday
Other than the missing word, any changes you see that need to be made? Any additions?
? You can partition in postgres + have multiple indexes to improve performance
Oh I know I just wanted to share that with you in case you weren't aware
Have you read Orileys Fundamentals of Data Engineering?
When building out RBAC, do you recommend building by data bucket?
I'm not sure how to explain it. The drop down bucket tables live in.
org.project.bucket.table


Hey there, I am working with Murilo, data engineer for sphere and he is attempting to understand what is going on with integrations side.
Would you know the answer for this?

Yes that is a GCP project for integrations
There is a GCP project for integrations?
There are multiple GCP project and probably will be more
Guy requesting read only access to integrations: mcamargos@sphereinc.com
From Sphere, we were requested to give them whatever they need
Remind me one more time because brain go brrrr
Looking, but that's showing up SUPER weird on mobile
billable vs signed vs signed_declined for DL campaigns
I blame slack. It renders excel / csv weird period
Where did you get the numbers? And for billable is it any status deemed billable in our status table?
billable is based on the statuses with billable=true in iotiplrstatusrates the numbers are from the attached sql
Ones where current status is a billable =True?
For the billable column and just final or retriggered for the signed column
What are they trying to gather from the table?
How many emails we may have to re-trigger for finals since the email automations for dl have been turned on and off without integrations in place. I think Abe was angry about missing cases
Sorry I got pulled into other things last night
In your opinion, what is the best way to run a scheduled query, that gets seconds as an int from a 'time' datatype and returns it as new column on a medium sized but growing dataset (five9)
I wrote this up which you think would be easy to run, but the estimated time to run it is wild-
```CREATE OR REPLACE TABLE tort-intake-professionals.tipopsdashboards.five9summarydata AS
SELECT -- Convert timestamps from PST to UTC DATETIME(TIMESTAMP(timestamp, 'America/LosAngeles'), 'UTC') AS timestamp, DATETIME(TIMESTAMP(contactcreatetimestamp, 'America/LosAngeles'), 'UTC') AS contactcreatetimestamp,
-- Raw fields abandoned, ani, calltype, campaign, customername, disposition, dnis, listname, sessionid, skill, aftercallworktime, calltime, handletime, holdtime, ivrtime, queuewaittime, talktime, timetoabandon, transfers, agentname, email, firstname, lastname, leadid,
-- Duration fields converted to seconds EXTRACT(HOUR FROM aftercallworktime) ** 3600 + EXTRACT(MINUTE FROM aftercallworktime) ** 60 + EXTRACT(SECOND FROM aftercallworktime) AS aftercallworktime_seconds,
EXTRACT(HOUR FROM calltime) ** 3600 + EXTRACT(MINUTE FROM calltime) ** 60 + EXTRACT(SECOND FROM calltime) AS calltime_seconds,
EXTRACT(HOUR FROM handletime) ** 3600 + EXTRACT(MINUTE FROM handletime) ** 60 + EXTRACT(SECOND FROM handletime) AS handletime_seconds,
EXTRACT(HOUR FROM holdtime) ** 3600 + EXTRACT(MINUTE FROM holdtime) ** 60 + EXTRACT(SECOND FROM holdtime) AS holdtime_seconds,
EXTRACT(HOUR FROM ivrtime) ** 3600 + EXTRACT(MINUTE FROM ivrtime) ** 60 + EXTRACT(SECOND FROM ivrtime) AS ivrtime_seconds,
EXTRACT(HOUR FROM queuewaittime) * 3600 + EXTRACT(MINUTE FROM queue_wait_time) * 60 + EXTRACT(SECOND FROM queuewaittime) AS queuewaittime_seconds,
EXTRACT(HOUR FROM talktime) ** 3600 + EXTRACT(MINUTE FROM talktime) ** 60 + EXTRACT(SECOND FROM talktime) AS talktime_seconds,
EXTRACT(HOUR FROM timetoabandon) * 3600 + EXTRACT(MINUTE FROM time_to_abandon) * 60 + EXTRACT(SECOND FROM timetoabandon) AS timetoabandon_seconds
FROM tort-intake-professionals.five9source.five9bulkcalldata_tabularv2```
I ran it for a few minutes, it hit a slot time of 1hr 50min and I canceled
I could partition, but I am not sure how to do it effectively
It has to scan the whole table for that query. postgres will return 500 rows in 0.7s. I suggest a view in postgres that you connect to BQ for further processing
Remember do most queries in Postgres then link the outputs to BQ if needed (views...)
It only takes postgres 3.5s to run the query. the rest of the time is downloading on our slow network
That makes sense- I need to figure out how to set it up on Postgres and connect it as a view but that makes sense to me
I can show you. it only takes a few minutes
I know Postgres is faster, but /why/ is it that much faster?
I need 4 minutes to finish this email, then I can help
-- Convert timestamps from PST to UTC
timezone('UTC', (timestamp AT TIME ZONE 'America/Los_Angeles')) AS timestamp,
timezone('UTC', (contact_create_timestamp AT TIME ZONE 'America/Los_Angeles')) AS contact_create_timestamp,
-- Raw fields
abandoned,
ani,
call_type,
campaign,
customer_name,
disposition,
dnis,
list_name,
session_id,
skill,
after_call_work_time,
call_time,
handle_time,
hold_time,
ivr_time,
queue_wait_time,
talk_time,
time_to_abandon,
transfers,
agent_name,
email,
first_name,
last_name,
lead_id,
-- Duration fields converted to seconds
EXTRACT(EPOCH FROM after_call_work_time) AS after_call_work_time_seconds,
EXTRACT(EPOCH FROM call_time) AS call_time_seconds,
EXTRACT(EPOCH FROM handle_time) AS handle_time_seconds,
EXTRACT(EPOCH FROM hold_time) AS hold_time_seconds,
EXTRACT(EPOCH FROM ivr_time) AS ivr_time_seconds,
EXTRACT(EPOCH FROM queue_wait_time) AS queue_wait_time_seconds,
EXTRACT(EPOCH FROM talk_time) AS talk_time_seconds,
EXTRACT(EPOCH FROM time_to_abandon) AS time_to_abandon_seconds
FROM five9_bulk_call_data_tabularv2
Do you do any of the financials for secondaries or is only @deleted-U05EFH3S2TA?
What do you mean? Like What status's are considered billable?
SELECT ** FROM `tort-intake-professionals.tip_prod_application.io_tip_lr_status_rates` LIMIT 1000

The I have a message chain for you to read while your over here for the next meeting
~40 minutes for DB dump to finish backfill from last night
Now its running in to the memory limit
there must be a memory leak somewhere
its now maxing 2 GB of RAM where as before it was sitting at 600 MB
Still think we can get it fixed in a couple of hours?
Im trying but also my laptop is not letting me debug it...
errors that I have fixed. Now I am debugging the memory leak. I think I know about where in the code is the issue is. The bug that LR fixed is that the drop down items are now be supplied from the LR endpoint
Good stuff- keep me updated on if anything breaks
Who should handle this request from the meeting last week?

Since it's a verification process for integrations, It would make sense for integrations to own it, but I would be happy to contribute my system checks for billable leads so you guys can see how many leads we have, and measure that leadid list against what got sent to firms
The two tables it would make sense for yall to use are likely these ones:
If you are just checking retainers it would be the first one here, if you are checking secondarys it would be the second

Is the contactid key from contact_address table, the same key as 'id' from the contact table?
Is the contactid key from contact_address table, the same key as 'id' from the contact table?
Btw if you need an easy summary table of all the LR data
tort-intake-professionals.tipopsdashboards.AllLawRulerLeadsWithEnrichment
or I can give you the sql so you can host in postgres if u want
Can you help with the following query? The numbers seem off
leads as (
select l.id, casetypeid, ct.name from lead l
INNER JOIN case_type ct ON l.casetypeid = ct.id
WHERE
(ct.name LIKE '%DL%' OR ct.name ILIKE '%DiCello%')
AND l.id IN (
SELECT DISTINCT leadid
FROM lead_history_status
WHERE tostatus = 'Signed e-Sign FINAL'
)
),
sent as (
SELECT COUNT(DISTINCT lh.leadid) as count, l.casetypeid
FROM lead_history lh
inner join leads l on l.id=lh.leadid
WHERE lh.username ILIKE '%@dicellolevitt.com%'
group by lh.leadid, l.casetypeid
)
select count(leads.id), name as case_type_name, leads.casetypeid as case_type_id, sum(sent.count) as sent_leads from leads left join sent on leads.casetypeid=sent.casetypeid group by leads.casetypeid, leads.name
Currently working through my own weird broken query but sure I'll take a look lol
What are you trying to find with it, and what makes you believe that it is off about it?
I am trying to find the count of all leads that should have been sent to DL and the count of the ones that have been sent via email (to get the count of not sent). I will need to also add count of ones sent via integration but that is extra

I wouldn't ever go off the case type name, too risky of things being set up wrong or typoed.. You might also be picking up campaigns with DL belonging to another campaign.
I recommend using the PCTID table but If you are gonna do it without it, normalize it first by forcing lower case before checking like
Also if for any reason a status is copied, and made as 'Signed e-Sign FINAL' out of the gate (Should not happen but it does) you're going to miss it with the current query because that change does not exist in history
For something as delicate as DL cases, I also wouldn't rely on count- I would get two complete lists of the leadids, and use a comparison script to spit out any leadids that are in one list but not the other.
Then you do it. They asked for count, that is what I was trying to do. I am SWAMPED
I get the frustration, you have a wild amount of things coming down on you all at once.
I need to step away from my current project anyway- I'll take a crack at this and see what I can find
Are you looking for JUST DiCello as the primary firm, or if they are associated with the case at all?
I'll set it up as all for now- if something changes it should be an easy fix
```-- Comparison Script for Finding Emailed leads vs All leads that DL is part of the case
WITH signedesignfinalleads AS (
SELECT DISTINCT statushistory.leadid
FROM tort-intake-professionals.lr_data.lead_history_status statushistory
LEFT JOIN tort-intake-professionals.lr_data.lead lead
ON statushistory.leadid = lead.id
WHERE LOWER(TRIM(statushistory.tostatus)) = 'signed e-sign final'
OR lead.statusid = 1075 -- signed e-sign final
OR lead.statusid = 3063 -- RE triggered
),
lawrulerdicelloleads AS (
SELECT
enriched.lawrulerleadid,
enriched.lawrulercasetypename,
enriched.lawrulercasetypeid,
enriched.allfirmsarray
FROM tort-intake-professionals.tip_ops_dashboards.All_LawRuler_Leads_With_Enrichment enriched
JOIN signedesignfinalleads statuscheck
ON enriched.lawrulerleadid = statuscheck.leadid
WHERE EXISTS (
SELECT 1
FROM UNNEST(enriched.allfirms_array) AS firm
WHERE LOWER(TRIM(firm)) LIKE '%dicello levitt%'
)
),
emaileddicelloleads AS (
SELECT
leadhistory.leadid,
lead.casetypeid
FROM tort-intake-professionals.lr_data.lead_history leadhistory
INNER JOIN tort-intake-professionals.lr_data.lead lead
ON lead.id = leadhistory.leadid
WHERE LOWER(leadhistory.username) LIKE '%@dicellolevitt.com%'
),
comparison AS ( SELECT dicelloleads.lawrulerleadid, emailedleads.leadid, dicelloleads.lawrulercasetypename, dicelloleads.lawrulercasetypeid, CASE WHEN dicelloleads.lawrulerleadid IS NOT NULL AND emailedleads.leadid IS NOT NULL THEN 'Match' WHEN dicelloleads.lawrulerleadid IS NOT NULL AND emailedleads.leadid IS NULL THEN 'Missing in Emailed Leads' WHEN dicelloleads.lawrulerleadid IS NULL AND emailedleads.leadid IS NOT NULL THEN 'Missing in LawRuler Leads' END AS comparisonresult FROM lawrulerdicelloleads dicelloleads FULL OUTER JOIN emaileddicelloleads emailedleads ON dicelloleads.lawrulerleadid = emailedleads.leadid )
SELECT ** FROM comparison WHERE comparisonresult != "Match" ORDER BY comparisonresult;```

That's why I included it, just in case.. looks like something odd though where the lead id is being repeated on the email side
Hospital Portal Privacy - Dicello - Shield Legal
I took the logic for the email ones from what you had but looking at what I wrote, it looks like those leads may have had 3 separate history logs with the email
emailed_dicello_leads AS (
SELECT
distinct lead_history.leadid,
lead.casetypeid
FROM `tort-intake-professionals.lr_data.lead_history` lead_history
INNER JOIN `tort-intake-professionals.lr_data.lead` lead
ON lead.id = lead_history.leadid
WHERE LOWER(lead_history.username) LIKE '%@dicellolevitt.com%'
),
Adding the distinct should fix the duplicates...
I would want to inspect the leads to see why it appears multiple times, but yeah distinct will cut it down.
And see if those leads are in Lawruler still to see what happened and why they aren't populating in my dataset
maybe the case type is not marked as DL in PCTID?
Case types missing DL in PCTID: Paraquat - DL - ML - Shield Legal CA Juv Hall Abuse - ACTS - DL Flatirons - Shield Legal
How soon can you update that?
With a few tweaks we should be able to use for the report Carter was asking about...
WITH signed_esign_final_leads AS (
SELECT DISTINCT status_history.leadid, lead.casetypeid
FROM `tort-intake-professionals.lr_data.lead` lead
LEFT JOIN `tort-intake-professionals.lr_data.lead_history_status` status_history
ON status_history.leadid = lead.id
WHERE (
LOWER(TRIM(status_history.tostatus)) = 'signed e-sign final'
OR lead.statusid = 1075 -- signed e-sign final
OR lead.statusid = 3063 -- RE triggered
)
AND lead.id NOT IN (657524, 393041, 582410, 511461, 581845, 692908, 711950, 581002, 657500, 623587, 395951, 651893, 556126, 679106,
647070, 712339, 562398, 643270, 580995, 610079, 381596) -- test leads
),
lawruler_dicello_leads AS (
SELECT
enriched.lawruler_lead_id,
enriched.lawruler_case_type_name,
enriched.lawruler_casetype_id,
enriched.all_firms_array
FROM `tort-intake-professionals.tip_ops_dashboards.All_LawRuler_Leads_With_Enrichment` enriched
INNER JOIN signed_esign_final_leads status_check
ON enriched.lawruler_lead_id = status_check.leadid
WHERE EXISTS (
SELECT 1
FROM UNNEST(enriched.all_firms_array) AS firm
WHERE LOWER(TRIM(firm)) LIKE '%icello levit%'
OR LOWER(TRIM(firm)) LIKE '%latiron%'
)
),
emailed_dicello_leads AS (
SELECT
DISTINCT lead.leadid AS leadid,
lead.casetypeid
FROM signed_esign_final_leads lead
INNER JOIN `tort-intake-professionals.lr_data.lead_history` lead_history
ON lead.leadid = lead_history.leadid
WHERE
LOWER(lead_history.username) LIKE '%@dicellolevitt.co%'
AND lead.casetypeid NOT IN (1703, 515, 351, 562, 309, 523) -- moved leads
),
comparison AS (
SELECT
COALESCE(dicello_leads.lawruler_lead_id, emailed_leads.leadid) AS leadid,
dicello_leads.lawruler_case_type_name,
dicello_leads.lawruler_casetype_id,
CASE
WHEN dicello_leads.lawruler_lead_id IS NOT NULL AND emailed_leads.leadid IS NOT NULL THEN 'Match'
WHEN dicello_leads.lawruler_lead_id IS NOT NULL AND emailed_leads.leadid IS NULL THEN 'Missing in Emailed Leads'
WHEN dicello_leads.lawruler_lead_id IS NULL AND emailed_leads.leadid IS NOT NULL THEN 'Missing in LawRuler Leads'
END AS comparison_result
FROM lawruler_dicello_leads dicello_leads
FULL JOIN emailed_dicello_leads emailed_leads
ON dicello_leads.lawruler_lead_id = emailed_leads.leadid
)
SELECT **
FROM comparison
ORDER BY comparison_result;
https://www.kdnuggets.com/10-surprising-things-you-can-do-with-pythons-collections-module

Below is the list that showed in the query we made the other day as DL. Please verify the firms are correct in PCTID.
MD Juv Hall Abuse - BG - Issacs and Issacs - Shield Legal Camp Lejeune EO - Bailey Glasser - FLG - Shield Legal Firefighting Foam - BG - Bowersox - Shield Legal MD Juv Hall Abuse - BG - Bowersox - Shield Legal Illinois Juv Hall Abuse - BG - Bowersox - Shield Legal Michigan Juv Hall Abuse - BG - Bowersox - Shield Legal Camp Lejeune - Bailey Glasser - FLG - Shield Legal Michigan Juv Hall - BG - Isaacs - Shield Legal Illinois Juv Hall - BG - Isaacs - Shield Legal MD Juv Hall - BG - FLG - Shield Legal PA Juv Hall - BG - Bowersox - Shield Legal
Just checked the first one- weirdly enough DL is showing up as a partner firm.. I wonder if these campaigns changed name at some point??
Maybe ask @Malissa or @deleted-U055HQT39PC?
These are also campaign IDs like 400s-early 500s
Cleaned all of the cases, give it a lil time and it will clear DL off of the "All_Firms" field
Do you have a flow chart that shows how integrations works from a technical side? If not do you have any questions / opinions about the below steps that can help me make a useful diagram? Status change in lr (lead finalizes) Lr generates questionnaire doc Lr sends email with questionnaire and retainer Gcp code checks inbox every 20 minutes Gcp code grabs oldest 100 unread emails For each email: Logs in db table Gets latest answers from lr Uploads email docs and answers to cloud storage Checks if case type automation is enabled for destination (firm crm) Sends lead to function for that firm: Translates the fields to the crm fields Sends to crm Logs response in db table
Let me take a look- I know I built some when I was over there, not sure how much has changed
https://techxplore.com/news/2025-07-source-tool-complex.html

https://www.bitecode.dev/p/what-parse-dont-validate-means-in


Finishing up something rn, but I'll be available after. I do have to get out at 4:25 though to get to the pharmacy before they close at 5
https://www.infoq.com/news/2025/07/cloudflare-timescaledb-olap/
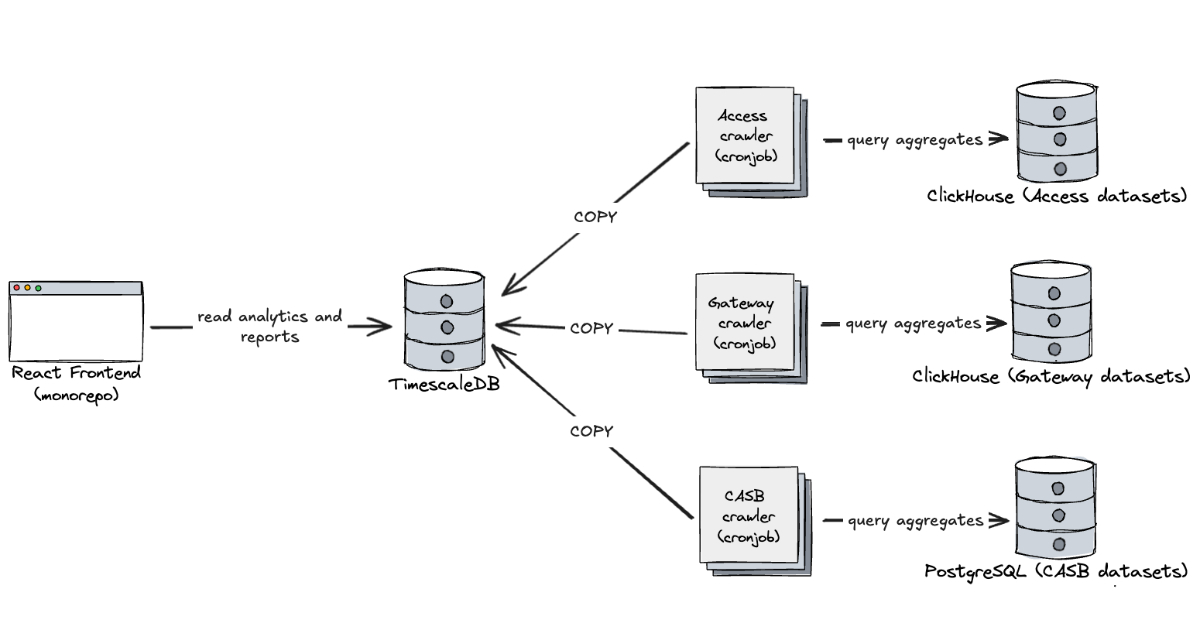
wanna add me back to shield legal git? lol

He constantly makes new repos but doesn't manage the permissions. Me, Ryan and McFadden can see no matter what
Wouldn't you be able to see it anyway because of Admin access?
and told him to think about the audience when sending a message (attach instead of link if some people do not have github)
Nothing confirmed, so keep it quiet but we are looking for new medical record solutions. We may need your team to build an Agent portal on the website to send a api post to a medical record company.
As I said, nothing confirmed- it's still in proposal mode
but I wanted to show you the Draw.io Chart I made

Agents cannot log into the website currently. You need to have a valid tort or shield email to login. Do the supervisors have emails?
Some do, but I'm not sure of the scope. I'll learn more and let you know, don't stress for now
https://www.kdnuggets.com/top-10-collections-of-cheat-sheets-on-github


Lol is this one of those youtubers you were telling me about?"
"Bunch of lonely kids, being led into devil worship by chatgpt" LOL
https://www.xda-developers.com/why-switching-from-brave-huge-mistake/

I like Draw.io but certain parts of it are a big pain in the butt, like it's framing system is either super janky, or unintuitive enough it's a problem

RING CENTRAL
SELECT ** FROM EXTERNAL_QUERY("<a href="http://tort-intake-professionals.us">tort-intake-professionals.us</a>.tort-intake-professionals-lr-data", "SELECT ** FROM ring_central.call_log;");
Invalid table-valued function EXTERNAL_QUERY PostgreSQL type in column type is not supported in BigQuery. You can cast it to a supported type by PostgreSQL CAST() function. at [1:15]
-- If legs is STRING, cast it; if it's JSON already, drop the CAST(...)
SELECT
JSON_VALUE(leg, '$.to.phoneNumber') AS to_phone,
JSON_VALUE(leg, '$.from.name') AS from_name,
JSON_VALUE(leg, '$.action') AS action,
JSON_VALUE(leg, '$.result') AS result,
SAFE_CAST(JSON_VALUE(leg, '$.durationMs') AS INT64) AS duration_ms,
JSON_VALUE(leg, '$.direction') AS direction,
JSON_VALUE(leg, '$.startTime') AS start_time
FROM `your_dataset.your_table` t
CROSS JOIN UNNEST(JSON_QUERY_ARRAY(CAST(t.legs AS JSON), '$')) AS leg;
not starttime or json values breaking it
apparently bigquery sees the postgres json as string
So does the script cited above not work?
I am looking through the Lawruler Q&A and I am seeing a lot of answers that is just "1" Is 1 true and 0 or a non answer false??


Those 2 examples are different leads but the same case type: Gaming Addiction - Meadow Law/Levinson/TC (TIP) - Shield Legal

It seems like sometimes it's Yes / No or 1
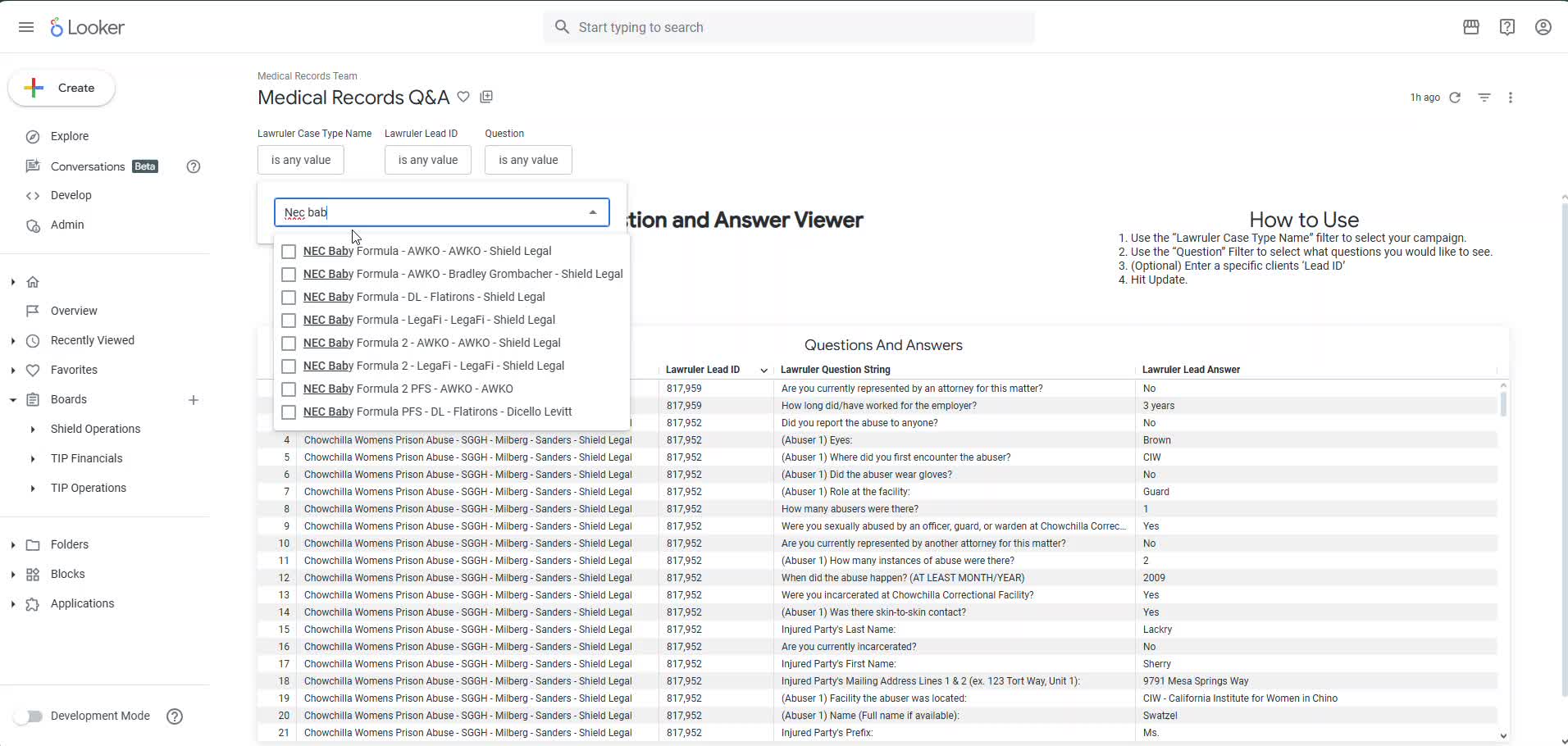
I imagine it's a simple 1 = Check Box checked
Those seem to be on the Form Fields tab which comes from the media source (Meta, TikTok, Web Form)

Maybe add filter to remove the form fields tab from your search?
Hey there, on lr_data where would I look to find the id of the closing agent?
Hey there, is lr_data broken for the user field?
I'm only getting like 783 leads with a valid intake_agent and most of them are really really old

l.id AS leadid,
l.casetypeid AS lr_id,
TRIM(l.casedescription) AS lp_lead_id,
l.displayname AS lr_lead_displayname,
l.createdate,
l.contactid,
l.sourceid,
u.name AS intake_agent
FROM postgres.public.lead AS l
LEFT JOIN postgres.public.user AS u -- "user" is a reserved word in Postgres
ON l.contactid = u.id
WHERE u.name IS NOT NUL
should l.userassigneeid not l.contactid on the join
damnit- that was obvious, I should of seen'
In relation to the meeting we just got out of, what do you think of using VertexAi for it since it's scaleable?
• LR Job Title field but not returned via API • Cannot find Groups or Roles in settings • What about Ad Campaign per lead?

FYI - Found a whole tab dedicated to keeping track of order medical records...
That's awesome, but I wonder why we haven't used it yet? What broken old system relies on that? lol
You can also add multiple contact cards to to a lead...
Hey I still don't have access to the conference rooms- can you look and see if anything is available for 11??
Does BQ remove empty lines from the scheduled query details page?
What do you mean? like if all values in a row are null?

Oh! That's where it represents the string condensed. if you want to see the query as written do this... (video incoming)
Also @Ryan is arguing with me about the source of table when I looked into it and he didnt... https://themedialaboratory.slack.com/archives/C02EGTD8LPP/p1755801094015249

Sounds like @Ryan will give you the task of updating the queries to use lr_data instead to make sure their up to date.
Joy- I haven't been explicitly asked yet, but I'm working on like 3 other tasks for him rn
Maybe he meant the other James? It will probably come once this meeting ends
Good morning! Could you please put me down for 11am for conference room 2?
sorry to treat you like a secretary lol
CR2 is already booked from 0900 to 1330
I appreciate you looking -Who has it from 09 to 1330?
• 0900 - 1000 | CSP Mtg • 1000 - 1100 | LDS AWKO CALL • 1030 - 1100 | S&R Huddle (@deleted-U04GZ79CPNG) • 1100 - 1130 | SL Data Sync (My team + @Carter Matzinger, @deleted-U06VDQGHZLL, @deleted-U06F9N9PB2A) • 1130 - 1300 | BCL - Ariana • 1300 - 1330 | Weekly ASA Check In (@deleted-U04GZ79CPNG, jscott@tortintakeprofessionals.com)
I have found that you need to reserve the room at least the day before if not earlier. when it comes to the day of, the people that get in early will reserve the rooms
Do you think it would be useful to pull some of the monday boards into the DB (such as open/closed tracker)?
If we can guarantee that those are consistently updated and correct then yeah for sure
your tip email should now be able to see the conference room calendar
Is there a way to get PG Admin without Joe?
why not just use pycharm?
winget install postgresql.pgadmin
I guess I could huh? I need to get access to Ryans 'public' dataset which I need to learn to set up
I think so? Not anything you need to do- i'm mostly just thinking "out loud"
Do you think I should set up associated campaigns as an array, so as many as needed can be added, or set up "auxillary campaign 1", "Auxillary campaign 2", "Medical Records Campaign"?
to be dynamic an array but we would have to tag the purpose of each (JSON dict instead?). But for ease of dashboards seperate columns. We talked about 4; SEC, Docs, Medical Records, SEC/Docs 2
unless you think the dynamicness can be handled...
Researching and it looks like Looker Enteprise CAN handle json nests, but it just requires some extra code on the presentation layer..
I just don't know how I would set that up in an easy to use front end system like what we have now
It's actually kind of weird. It can't handle array values right, but it has a JSON_EXTRACT_SCALAR() function that allows us to split it into new dimensions for presentation
And would Re-tool allow for manipulating it? Or are we going with the internal site where we can do anything?
I would love to do it on the internal site, but because Chris isn't truly dedicated to the project, I don't want to rely on it if that makes sense
and idk how long it would take for him to build it and have it be consistent/functional
So then can re-tool manipulate the JSON in the way we want? That would give us the answer between columns or dynamic
It looks like it has a JSON option, for data types on a table, but idk how well it handles it or limitations for data entry using it. I need to build some kind of test for it
Looks like you can edit it, but you edit it like it was a string, it doesn't break it out in a way that makes sense to non-engineers
Looks like you can edit it, but you edit it like it was a string, it doesn't break it out in a way that makes sense to non-engineers
Looks like Retool re-vamped how their database connections work.. I wonder if it will work now?


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I added the retool ips to the DB. Do you have a postgres account you can use for retool, or want me to make one?
Make one please- I'm still very inexperienced with Postgres
Potentially dumb question but is that a 'user' login or a database user/pass?
Not a immediate need, but is that something we plan on changing to be more clear down the line?
Like we might have an 'engineering_postgres"
Not a immediate need, but is that something we plan on changing to be more clear down the line?
Like we might have an 'engineering_postgres"
is possible but would break everything and make things much harder. thats why we do the split at the schema level
cannot join between databases (in same postgres or different). can only join between schemas
Kind of like if we changed the bigquery setup to have different projects, with multiple buckets instead of a single project?
in BQ you are able to join across multiple projects but it's additional steps- I do understand what you're saying though so ty! Let me test this out
10:42:06 AM Test Connection Failed
- ▶️{query: "Select 1 as result", error: Object} a. query: "Select 1 as result"
- ▶️error: Object a. message: "pg_hba.conf rejects connection for host "35.90.103.134", user "retool", database "postgres", no encryption"
30 second inspection on postgres, makes it look like internal_tools would be the right location to store PCT-ID
Does that sound right to you?
I think the public schema since its all LR data
In a few years when we are departed from Lawruler, and the "lr" in lr_data becomes "Lead Repository" instead of "Law Ruler" I foresee situations where we may want to give read-only PCT-ID access without giving read access to all of our client data. Thoughts?
(Came up with Lead Repository on the spot, but I think that's pretty clever)
Nevermind- I see pctid_v2 already exists within the public set
You should be able to add / modify the columns for pctid_v2 in postgres
tort-intake-professionals.tipprodapplication.iotiplrstatusrates